Amazon Bedrock 및 Strands Agents를 이용한 롯데백화점의 AI 컨시어지 구축기
오프라인 리테일의 AI 혁신
대한민국 대표 백화점인 롯데백화점은 전국 수십 개 지점에서 프리미엄 쇼핑 경험을 제공하고 있습니다. 롯데백화점의 오프라인 매장 및 서비스 정보를 제공하는 롯데백화점 앱은 업계 최대인 약 700만 명의 가입자를 보유하고 있으며, 월간 활성 사용자 수(MAU)는 110만 명에 이릅니다. 롯데백화점은 이러한 디지털 접점을 더욱 강화하고 고객 경험을 한 단계 끌어올리기 위해 AI 기반의 컨시어지 서비스를 기획하였고, AWS PACE팀과 협력하여 AI 컨시어지 ‘더스틴’을 구축하게 되었습니다. 본 포스팅에서는 롯데백화점이 어떻게 AI 컨시어지를 설계하고 구현했는지, 그리고 실제 운영 과정에서 마주한 최적화 과제들을 어떻게 해결했는지 살펴보겠습니다.
AI 컨시어지 도입 배경
롯데백화점 앱은 수백 개의 입점 브랜드와 수시로 변경되는 행사 및 서비스 정보를 다루고 있습니다. 이처럼 방대하고 동적인 정보를 고객에게 효과적으로 전달하기 위해, 기존 앱의 정보 체계를 개선할 필요가 있었습니다.
정보의 분산: 매장 위치, 브랜드 정보, 할인 혜택, 영업 시간 등 고객이 필요로 하는 정보가 여러 메뉴 및 기능에 흩어져 있어 통합적인 안내가 어려웠습니다.
디지털 접근성 문제: 앱 사용이 익숙하지 않은 중장년층 고객에게는 원하는 정보를 찾아가는 과정이 어려움이 되었습니다.
검색 기능 고도화의 필요성: 기존의 키워드 검색이나 FAQ 방식으로는 “여자친구 생일 선물로 뭐가 좋을까?”, “한식당 추천해줘”와 같은 자연스러운 질문에 대응하기 어려웠습니다.
옴니채널 전략의 필요성: 온라인의 편리함과 오프라인의 경험적 가치를 결합하여 차별화된 고객 경험을 제공해야 했습니다.
반복 문의로 인한 업무 부담: 매장 위치, 주차 정보 등 단순 반복 문의가 고객센터와 현장 직원의 업무 부담으로 이어지고 있었습니다.
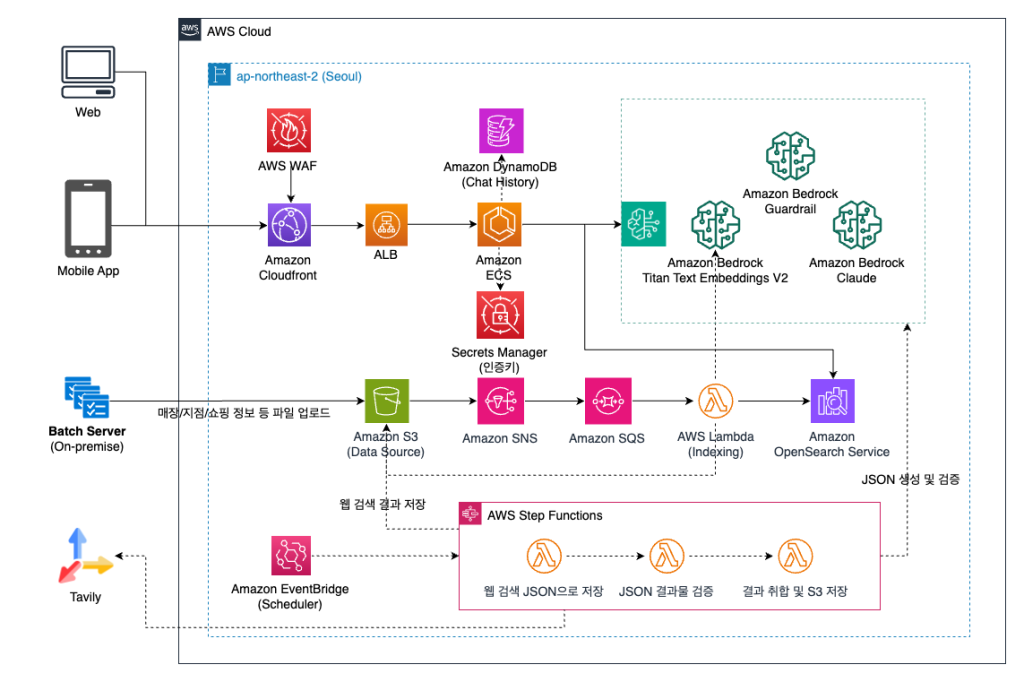
2. AI 에이전트 레이어
Amazon ECS에서 Strands Agents SDK 기반 에이전트 서버를 운영합니다. 에이전트 추론 시에는 Amazon Bedrock의 Anthropic Claude Haiku 모델을 사용하여 빠른 응답 속도와 비용 효율성을 확보하였습니다. Amazon Bedrock Guardrails를 통해 개인정보 및 부적절한 데이터는 필터링하여 에이전트가 해당 데이터를 처리하지 못하도록 차단하고, Amazon DynamoDB를 이용해 대화 이력을 관리하여 문맥을 유지합니다.
3. 데이터 및 색인 레이어
온프레미스 배치 서버에서 매장, 지점, 쇼핑 정보 등을 Amazon S3에 업로드합니다. 파일 업로드 시 Amazon SNS와 SQS를 통해 AWS Lambda 함수가 실행되어 데이터를 파싱하고 Amazon OpenSearch Service에 색인합니다. 에이전트에서 검색 시에는 질의 의도와 유형에 따라 키워드 검색과 하이브리드 검색(키워드 + 의미 기반 벡터 검색)을 혼용하며, 벡터 검색에는 Amazon Bedrock Titan Text Embeddings V2를 활용합니다.
백화점 지점 주변의 최신 핫플레이스 정보 등 웹에서 검색된 데이터를 활용하기 위해서는 주기적으로 AWS Step Functions를 실행합니다. 검색 도구인 Tavily로 검색된 문서에서 Amazon Bedrock Claude Sonnet 및 Opus를 이용해 데이터를 추출하고 JSON으로 파싱하여, 다른 데이터와 동일하게 S3에 저장합니다.
AI 컨시어지 구현 과정
서비스 화면 소개
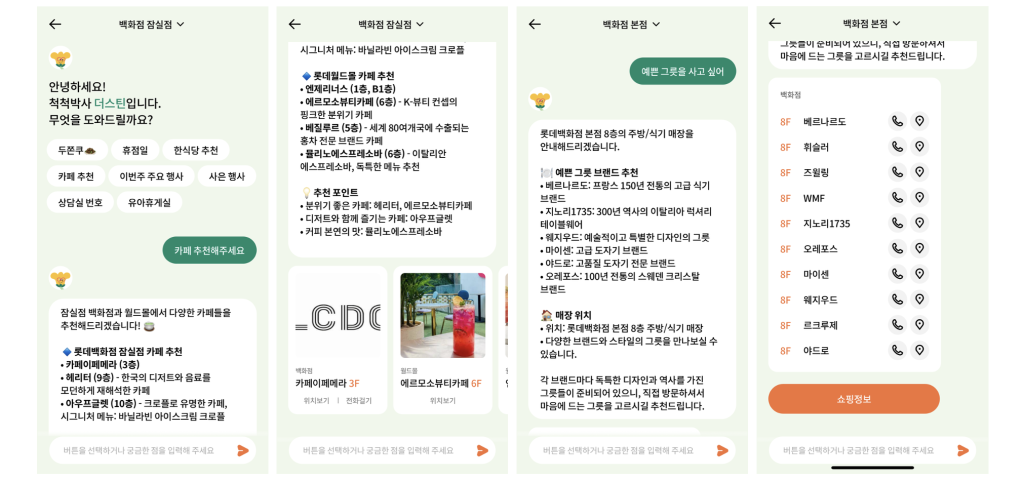
더스틴의 기능을 한눈에 확인해볼 수 있도록 서비스 화면을 우선 살펴보겠습니다. 초기 화면에서는 “휴점일”, “한식당 추천”, “카페 추천” 등 자주 묻는 질문들을 빠른 버튼으로 제공하여, 타이핑이 익숙하지 않은 고객도 쉽게 서비스를 이용할 수 있도록 하였습니다. 만약 고객이 “카페 추천해주세요”라고 요청하면, 현재 선택된 지점의 카페 정보를 층수와 함께 안내합니다. 또한 “예쁜 그릇을 사고 싶어”와 같이 특정 매장을 찾는 것이 아닌 쇼핑 목적으로 문의하는 경우에도, AI 컨시어지는 적절한 카테고리의 관련 브랜드를 추천합니다. 응답 시에는 텍스트 답변과 함께 카드형 UI로 매장 정보를 시각적으로 제공합니다. 각 카드에는 매장 이미지, 위치(동/층), 위치보기 및 전화걸기 버튼이 포함되어 있고, 카드 선택 시 해당 매장의 상세 안내 페이지로 이동하기 때문에 고객은 빠르게 연관 정보를 이어서 확인할 수 있습니다.
에이전트 도구(Tool) 설계 전략
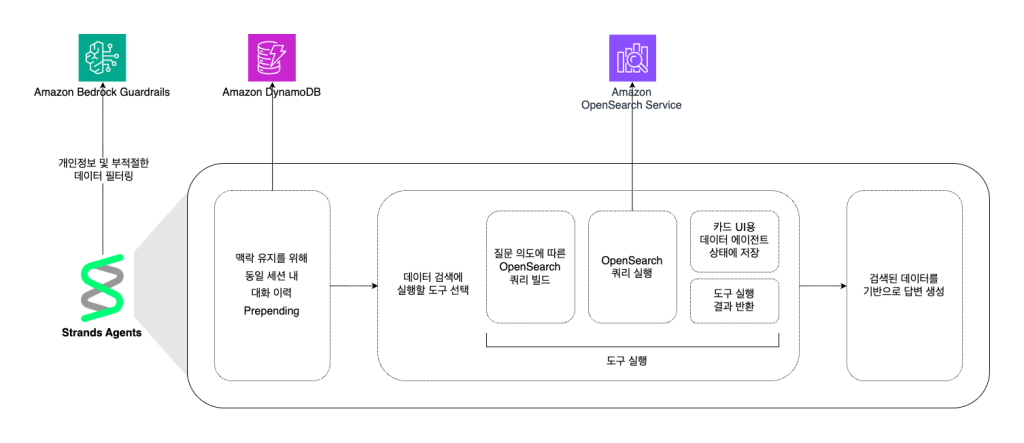
롯데백화점 AI 컨시어지는 고객의 다양한 질문 의도에 맞춰 적절한 데이터를 활용하고 제공하기 위해 질문 의도 별로 도구를 분류하여 관련 데이터를 조회합니다. 예를 들어 “OOO 매장 어디있어?”라고 질문하면 Amazon OpenSearch Service에서 매장 및 시설 관련 정보를 조회하는 도구를, “오늘 진행 중인 할인행사는 뭐야?”라고 질문하면 이벤트 정보를 조회하는 도구를 실행합니다.
이때 질문 유형과 의도에 따라 OpenSearch에서 실행해야하는 쿼리 유형이 달라지기 때문에 도구 실행 시 필요한 쿼리를 우선 빌드하고 실행합니다. 예를 들어 지점 관련 질문 시 검색 쿼리에는 고객이 화면에서 선택한 지점의 데이터만 검색하도록 제한하기 위한 쿼리를 추가합니다.
# OpenSearch 쿼리 빌더 함수 예시
def _build_opensearch_query(
branch_name: Optional[str] = None,
...
) -> Dict[str, Any]:
must_conditions = []
must_conditions.append({
# 지점 관련 질문의 경우 해당 지점의 데이터만 검색하도록 제한
"term": {"metadata.branch_name": branch_name}
})
...
시스템 프롬프트는 에이전트가 더 높은 정확도로 도구를 선택할 수 있도록 도구 선택 지침을 포함합니다. 예를 들어 ‘샵나우(롯데백화점의 큐레이트 쇼핑 컨텐츠)’, ‘쇼핑정보(롯데백화점의 할인, 사은, 문화/이벤트 등의 행사 정보)’와 같이 롯데백화점에서 고유하게 쓰이는 서비스 용어도 에이전트가 이해할 수 있도록 예시와 설명을 프롬프트에 추가하였습니다.
# 시스템 프롬프트 예시
<tool_choice_policy>
# 예시 도구명
<get_shopping_info>
Tool to get information related to promotions, coupons, and culture event.
Example keywords include: "세일", "쿠폰", "사은", "문화 이벤트", "샵나우" ...
Lotte Department Store refers to the contents containing shopping promotion information as "쇼핑 정보".
</get_shopping_info>
</tool_choice_policy>
각 도구는 필요에 따라 인풋 파라미터를 다르게 설정하였고, 파라미터로 받은 정보를 OpenSearch Service의 검색 시에 활용하여 검색 결과를 반환합니다. 예를 들어 브랜드 관련 정보를 제공하는 도구의 경우 상품 카테고리 기반 브랜드 추천을 위해 추천 카테고리 파라미터를 활용합니다. 고객은 “머그컵 살 곳 있어?” 또는 “여자친구 선물 추천해줘”와 같이 다소 광범위한 추천을 요구하는 쇼핑 목적으로 질문하는 경우가 있습니다. 이러한 질문에 효과적으로 대응하기 위해 도구에 추천 카테고리 파라미터를 추가하였습니다. 에이전트는 사용자의 질문 의도를 파악하여 적절한 카테고리를 선택하고, 해당 카테고리 내 브랜드를 검색하여 추천합니다. 예를 들어 ‘머그컵’ 관련 질문에는 ‘주방/식기’를, ‘여자친구 선물’에는 ‘패션 액세서리’ 등의 카테고리를 선택하여 관련 매장을 안내합니다.
from typing import Literal
from strands import tool
from strands.types.tools import ToolContext
# 예시 카테고리
CategoryLiteral = Literal[
"레져/스포츠", "패션 액세서리", "남성패션", "여성패션",
"아동/유아", "가전", "주방/식기", "화장품", None
]
# 예시 도구
@tool(context=True)
async def get_facility_info(
tool_context: ToolContext,
recommended_category: CategoryLiteral
...
) -> dict:
"""
롯데백화점 내 브랜드 매장, F&B, 편의시설을 검색합니다.
Args:
tool_context: Strands Agents tool context
recommended_category: 추천 카테고리 (특정 매장명이 아닌 경우 활용)
...
"""
branch_code = tool_context.agent.state.get("branch_code")
branch_name = tool_context.agent.state.get("branch_name")
...
# 특정 매장명이 없고 추천 카테고리가 있는 경우
# 해당 카테고리의 매장/브랜드를 검색하여 추천
recommendation_keyword = recommended_category
# Opensearch 검색 함수
search_results = await find_facility_by_branch(
query=query,
branch_code=branch_code,
branch_name=branch_name,
keyword=recommendation_keyword
)
...
매장 및 서비스용 데이터 파이프라인 설계
롯데백화점의 매장, 지점, 쇼핑 정보는 온프레미스 배치 서버에서 관리됩니다. 이 데이터를 AI 컨시어지가 활용할 수 있도록 Amazon S3, SNS, SQS, Lambda를 연결한 이벤트 기반 파이프라인을 구축하였습니다. 파일이 S3에 업로드되면 자동으로 데이터 파싱, 청킹, 임베딩 생성, OpenSearch 색인까지 완료되는 구조입니다. 데이터 파이프라인은 다음과 같이 구성됩니다:
온프레미스 배치 서버: 매장정보, 지점정보, 쇼핑뉴스 등 데이터를 JSON 파일로 생성하여 S3에 업로드
Amazon S3: 데이터 저장소이자 파이프라인의 시작점으로 파일 업로드 시 이벤트 알림 발생
Amazon SNS/SQS: S3 이벤트를 수신하여 Lambda로 안정적으로 전달
AWS Lambda: 데이터 파싱, 청킹, 임베딩 생성 및 OpenSearch 색인 수행
Amazon OpenSearch Service: 벡터 검색과 키워드 검색을 지원하는 검색 엔진
Amazon SQS는 메시지 배치 처리, 재시도, Dead Letter Queue 등을 제공하여 대용량 데이터 처리 시에도 메시지 유실 없이 안정적으로 처리할 수 있습니다. Lambda 함수는 AWS Lambda Powertools의 BatchProcessor를 활용하여 SQS 메시지를 효율적으로 처리합니다:
# 예시 Lambda 코드
from aws_lambda_powertools.utilities.batch import BatchProcessor, EventType, batch_processor
from aws_lambda_powertools.utilities.data_classes.sqs_event import SQSRecord
processor = BatchProcessor(event_type=EventType.SQS)
@batch_processor(record_handler=process_record, processor=processor)
def lambda_handler(event, context):
"""Lambda 핸들러 진입점"""
logger.info(f"Embedder function invoked with {len(event.get('Records', []))} SQS records.")
return processor.response()
각 SQS 메시지에는 S3 이벤트 정보가 포함되어 있으며, 이를 파싱하여 업로드된 파일의 버킷과 키를 추출합니다:
# 예시 레코드 처리 함수
def process_record(record: SQSRecord):
"""SQS 레코드 처리 - S3 이벤트 알림 파싱"""
message_body = json.loads(record.body)
for s3_record in message_body.get('Records', []):
bucket = s3_record['s3']['bucket']['name']
key = urllib.parse.unquote_plus(
s3_record['s3']['object']['key'],
encoding='utf-8'
)
# 파일명에서 데이터 유형과 버전 정보 추출
source_parts = key.split("_")
source_type = source_parts[1] # 'store', 'branch', 'faq' 등
source_date = source_parts[2] + source_parts[3].split('.')[0] # 버전 관리
# 데이터 처리 로직 수행
content = get_s3_object_content(bucket, key)
chunk_objects = chunk_content(client, INDEX_NAME, content, bucket, key)
...
색인 시 벡터 검색을 위해 Amazon Bedrock의 Titan Text Embeddings V2 모델을 통해 생성된 벡터도 함께 저장됩니다. 대량의 청크를 처리해야 하므로 멀티스레딩을 활용하여 임베딩 생성을 병렬화하였습니다:
import concurrent.futures
bedrock = boto3.client("bedrock-runtime", region_name="ap-northeast-2")
# 멀티스레딩을 활용한 병렬 임베딩 생성 예시
def get_embedding(text: str) -> Optional[list[float]]:
"""Bedrock Titan으로 텍스트 임베딩 생성"""
if not text:
return None
response = bedrock.invoke_model(
modelId=EMBEDDING_MODEL_ARN,
body=json.dumps({"inputText": text}),
contentType='application/json',
accept='application/json'
)
response_body = json.loads(response["body"].read())
return response_body.get("embedding")
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
embedding_futures = {
executor.submit(get_embedding, chunk["text"]): i
for i, chunk in enumerate(batch_chunks)
}
embeddings = {}
for future in concurrent.futures.as_completed(embedding_futures):
idx = embedding_futures[future]
embedding = future.result()
if embedding:
embeddings[idx] = embedding
데이터 파이프라인은 파일명에 포함된 날짜 정보(source_date)를 활용하여 증분 처리를 수행합니다. 새로운 버전의 데이터가 색인되면 이전 버전의 문서를 자동으로 삭제하여 검색 결과의 최신성을 유지합니다:
# 과거 버전 문서 삭제 함수 예시
def delete_old_versions(source_type: str, source_date: str):
"""이전 버전 문서 삭제 - 증분 처리"""
search_query_body = {
"query": {
"bool": {
"must": [
{"term": {"source_type": source_type}},
{"range": {"source_date": {"lt": source_date}}}
]
}
}
}
# search_after를 사용한 페이지네이션으로 대량 삭제 처리
while True:
response = client.search(index=INDEX_NAME, body=search_query_body)
hits = response.get("hits", {}).get("hits", [])
if not hits:
break
bulk_ops = [
{"delete": {"_index": INDEX_NAME, "_id": hit["_id"]}}
for hit in hits
]
client.bulk(body=bulk_ops)
이러한 이벤트 기반 파이프라인 구조를 통해 배치 서버에서 데이터가 업로드되면 수 분 내에 AI 컨시어지가 최신 정보를 기반으로 고객 질문에 응답할 수 있게 되었습니다.
웹 검색 데이터 파이프라인 설계
롯데백화점 본점, 잠실점 등 주요 지점은 단순한 쇼핑 공간을 넘어 관광 명소로도 각광받고 있습니다. 고객의 쇼핑 경험이 주변 핫플레이스 탐방으로 자연스럽게 이어질 수 있도록, 각 지점 주변의 인기 명소 정보를 제공하기로 하였습니다.
다만 웹 검색 결과를 실시간으로 활용할 경우 컨텐츠의 정확도와 품질을 보장하기 어렵습니다. 이를 해결하기 위해 AWS Step Functions를 활용한 배치 파이프라인을 구축하여, 사전에 검증된 핫플레이스 정보만 서비스에 활용하도록 설계하였습니다. 이 파이프라인에서는 데이터 추출 및 검증의 정확도를 높이기 위해 Amazon Bedrock의 Claude 4.5 Sonnet과 Claude 4.5 Opus 모델을 활용합니다.
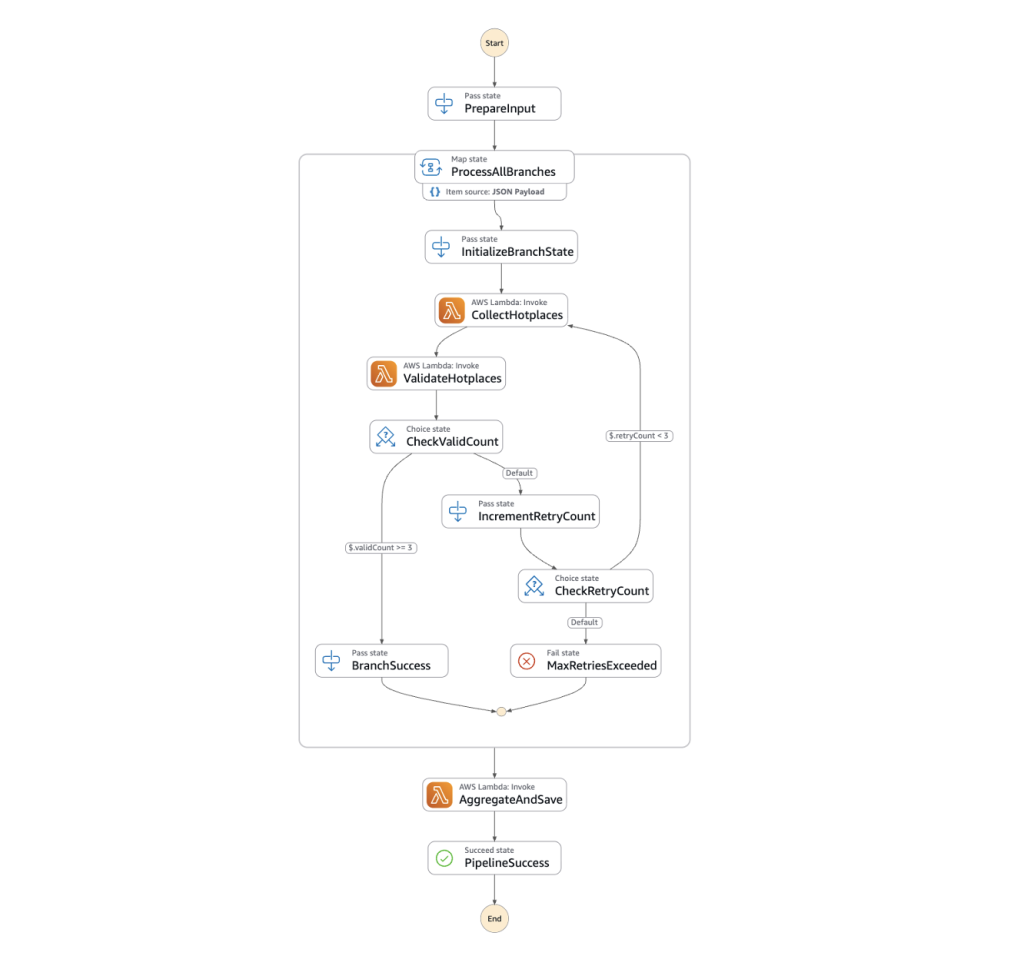
파이프라인은 Amazon EventBridge를 통해 주 1회 실행되며 최신성을 유지하지 위해 실행시마다 새 데이터로 업데이트됩니다. 실행 단계는 크게 세 단계로 구성됩니다.
1단계: 웹 검색 및 데이터 수집 (CollectHotplaces)
Collector Lambda 함수는 각 지점별로 주변 명소를 검색하고, LLM을 활용하여 구조화된 JSON 데이터를 생성합니다.
웹 검색 서비스인 Tavily를 통해 "{search_area} 핫플레이스 추천", "{search_area} 가볼 만한 곳" 등의 키워드로 검색을 수행한 후, Amazon Bedrock의 모델을 호출하여 장소명, 카테고리, 설명문을 추출합니다.
branch_data = event.get('branchData', event)
search_area = branch_data.get('searchArea')
# 예시 프롬프트
EXTRACTION_PROMPT = """당신은 백화점 고객을 위한 지역 핫플레이스 정보를 제공하는 전문가입니다.
아래 웹 검색 결과를 분석하여 "{search_area}" 지역의 핫플레이스 정보를 추출해주세요.
## 검색 결과:
{search_context}
## 요구사항:
1. 검색 결과에서 실제로 언급된 장소만 추출하세요.
2. 각 장소에 대해 다음 정보를 제공하세요:
- name: 장소 이름 (정확한 상호명)
- category: 카테고리 (카페, 레스토랑, 전시/문화, 쇼핑, 포토존, 복합문화공간 등)
- description: 200자 내외의 한글 설명문
3. 최대 10개의 핫플레이스를 추출하세요.
4. 카페와 식당은 총 2개를 넘지 않도록 해주세요.
## 출력 형식:
JSON 형식으로만 응답해주세요."""
2단계: 데이터 검증 (ValidateHotplaces)
Validator Lambda 함수는 생성된 데이터의 정확도와 지침 이행 여부를 평가합니다. 최소 결과 개수를 충족하지 않을 경우 최대 3회까지 데이터 수집을 재시도합니다.
# 예시 프롬프트
VALIDATION_PROMPT = """당신은 데이터 검증 전문가입니다. 아래 핫플레이스 정보를 검증해주세요.
## 검증 기준:
1. 실존 확인: 원본 검색 결과에서 해당 장소가 실제로 언급되었는지 확인
2. 부적절한 표현 체크: 비속어, 혐오 표현, 광고성 문구 포함 여부
3. 부정적 의견 체크: 지나치게 부정적인 리뷰가 description에 포함되어 있지 않은지
4. 설명 일치성 확인: description이 해당 장소에 대한 설명이 맞는지
## 출력 형식:
각 핫플레이스에 대해 is_valid와 reason을 포함한 JSON으로 응답해주세요."""
3단계: 데이터 통합 및 저장 (AggregateAndSave)
Aggregator Lambda 함수는 검증을 통과한 데이터만 취합하여 S3에 저장합니다. 이후 기존 데이터 파이프라인을 통해 OpenSearch에 색인되어 에이전트 응답 생성에 활용됩니다.
# Map 상태에서 전달된 결과 배열
branch_results = event.get('branchResults', [])
if not branch_results:
raise ValueError("No branch results provided")
# 결과 병합 코드 예시
collected_at = datetime.now(KST).strftime("%Y-%m-%d %H:%M:%S")
aggregated_data = {
'collected_at': collected_at,
'branches': []
}
total_hotplaces = 0
for result in branch_results:
branch_data = {
'branch_code': result.get('branchData', {}).get('branchCode'),
'branch_name': result.get('branchData', {}).get('branchName'),
'hotplaces': result.get('validatedHotplaces', [])
}
aggregated_data['branches'].append(branch_data)
total_hotplaces += len(branch_data['hotplaces'])
logger.info(f"Branch {branch_data['branch_name']}: {len(branch_data['hotplaces'])} hotplaces")
# S3에 저장
today_kst = datetime.now(KST).strftime('%Y%m%d')
s3_key = f'hotplace_{today_kst}.json'
try:
s3_client.put_object(
Bucket=OUTPUT_BUCKET,
Key=s3_key,
Body=json.dumps(aggregated_data, ensure_ascii=False, indent=2),
ContentType='application/json; charset=utf-8'
)
logger.info(f"Successfully saved to s3://{OUTPUT_BUCKET}/{s3_key}")
except Exception as e:
logger.error(f"Failed to save to S3: {e}")
raise
성능 최적화 방안
토큰 사용량 최적화
서비스 초기 구축 과정에서 토큰 사용량이 예상보다 높게 관찰되었습니다. 롯데백화점은 다음과 같은 최적화 작업을 통해 토큰 사용량을 약 50% 감소시킬 수 있었습니다.
1. 시스템 프롬프트 최적화
롯데백화점은 가장 먼저 한글 프롬프트를 영문으로 변경하여 토큰 효율을 개선하였습니다. 또한 반복적으로 사용되는 프롬프트를 비용 효율적으로 처리하고 성능을 향상시키기 위해 프롬프트 캐싱을 사용하였는데, 이때 캐싱 효과를 극대화하기 위해 동적으로 삽입되던 현재 시간(current_time)과 현재 지점(current_branch) 정보를 시스템 프롬프트에서 제거하고 사용자 프롬프트로 이동시켰습니다.
# 변경 전 시스템 프롬프트 예시
SYSTEM_PROMPT = """
<current_context>
Current time: $current_time
Current branch: $current_branch
</current_context>
...
"""
# 변경 후 사용자 프롬프트 예시
final_message = f"""
...
Current time:{current_time}, Current branch:{current_branch}
...
"""
# 사용자 프롬프트로 에이전트 스트리밍 응답 요청 예시
stream = self.agent.stream_async(
final_message
)
2. 도구 실행 결과 경량화
에이전트는 도구 실행을 통해 OpenSearch에서 검색된 데이터를 받아 답변 생성에 참고합니다. 이때 검색 결과 중 답변 생성에 불필요한 이미지 및 앱 URL 주소 등의 데이터 역시 도구 실행 결과로 넘겨주게 되면 추가 토큰을 사용하게 됩니다. 때문에 답변 생성에 불필요한 데이터는 도구 실행 결과에서 제외하면 해당 토큰 사용량을 줄일 수 있습니다. 다만 이미지 및 앱 URL 정보는 프론트엔드에서 카드형 UI 제공을 위해 필요한 데이터이기 때문에 에이전트 상태(agent state)로 전달되도록 구현하여 토큰 사용량은 줄이면서도 화면에서 풍부한 정보를 제공할 수 있도록 분리하였습니다.
# 에이전트 상태 데이터 주입 함수 예시
def extract_urls(items: dict, agent_state: AgentState) -> None:
"""URL 정보를 추출하여 Agent State에 저장"""
url_info = {}
for key, item_list in items.items():
url_info[key] = []
url_key = 'url'
for idx, item in enumerate(item_list):
entry = {
url_key: item.pop(url_key, '')
}
url_info[key].append({str(idx): entry})
# Agent State에 저장 (LLM 컨텍스트에는 포함되지 않음)
agent_state.set("url_info", url_info)
3. 도구 실행 이력 압축
대화 맥락 유지를 위해서는 동일 세션 내의 이전 메세지들을 에이전트 대화 이력 맨 앞에 삽입해주어야 합니다. 이때 에이전트의 정상적인 동작을 위해서는 도구 실행 이력도 함께 저장했다가 삽입해주어야 합니다. 이때 도구 실행 이력 전체를 삽입할 경우 에이전트 처리하는 토큰량 또한 많아지기 때문에 도구 실행 이력 저장 시에는 실행 결과 중 고객에게 제공된 답변 유형(answerType) 등 핵심 정보만 남기고 나머지는 축약하여 저장합니다. 이를 통해 이전 대화 컨텍스트 중 toolResult를 에이전트로 전달할 때 토큰 사용량을 크게 줄일 수 있습니다. (해당 구성의 경우, 사용자 프롬프트를 캐싱하고 있다면 캐시를 활용하지 못하게 될 수 있습니다. 다만 롯데백화점의 경우, 사용자 프롬프트 캐싱을 통한 효과보다 도구 실행 이력 압축으로 인한 효용 가치가 클 것으로 판단되어 사용자 프롬프트는 캐싱하지 않고 해당 구성을 적용하였습니다.)
def _extract_answer_type(self, tool_result: List[Dict[str, Any]]):
"""tool_result에서 answerType만 추출하고 나머지는 truncate"""
simplified_result = []
answer_type = "N/A"
for item in tool_result:
if 'toolResult' in item:
tool_result_data = item['toolResult']
simplified_item = {
'toolResult': {
'toolUseId': tool_result_data.get('toolUseId'),
'status': tool_result_data.get('status'),
'content': []
}
}
for content_item in tool_result_data.get('content', []):
if 'text' in content_item:
try:
text_data = ast.literal_eval(content_item['text'])
answer_type = text_data.get('answerType', 'unknown')
# 토큰 절약을 위해 축약된 형태로 저장
simplified_item['toolResult']['content'].append({
'text': f"{{'answerType': '{answer_type}'}} Rest of the tool result has been truncated."
})
except:
simplified_item['toolResult']['content'].append(content_item)
else:
simplified_item['toolResult']['content'].append(content_item)
simplified_result.append(simplified_item)
else:
simplified_result.append(item)
return simplified_result, answer_type
검색 결과 필터링
에이전트는 사용자의 질문 의도에 따라 다소 광범위한 데이터를 검색하거나 하이브리드 검색을 수행하기 때문에 OpenSearch 검색 시 관련성이 낮은 결과가 포함될 수 있습니다. 이를 해결하기 위해 에이전트가 답변 생성에 실제로 활용한 검색 결과의 인덱스만 선별하도록 프롬프트를 설계하였습니다.
# 시스템 프롬프트 예시
<response_policy>
...
At the end of the message, append referenced indices for all keys in "results".
Format: <<'key1':[i1,i2], 'key2':[j1,j2]>>
Example:
이번주 잠실점 행사 정보 안내드립니다.
· 이달의 행사: 행사명
· 주요 기획전: 기획전 1, 기획전 2
<<'eventlist':[1,2]>>
...
</response_policy>
에이전트는 답변 생성 시 실제 참조한 검색 결과의 인덱스 번호를 텍스트 끝에 함께 전달합니다. 프론트엔드에서 카드 UI 제공을 위해 필요한 데이터를 전달할 시에는 ‘<<’와 ‘>>’ 사이에 전달된 인덱스의 데이터만 파싱하여 전달합니다. 이 방식을 통해 검색 결과 전체를 LLM이 다시 필터링하지 않아도 되어 토큰을 절약하고 응답 속도를 최적화할 수 있으며, 답변에서 실제로 언급된 매장이나 행사만 카드로 표시되어 답변 정확도가 향상되었습니다.
환각(Hallucination) 방지
에이전트 테스트 시 검색 결과가 충분하지 않은 경우에도 모델이 학습 데이터를 기반으로 답변을 생성하려는 현상이 일부 관찰되었습니다. "도구 실행 결과에 답변을 위한 정보가 없으면 답변하지 마세요"라는 지침을 시스템 프롬프트에 포함하였으나, 이 방식만으로는 환각을 완전히 방지하기 어려웠습니다.
이를 해결하기 위해 검색 결과 유무에 따라 답변 생성 지침을 분리하여 도구 실행 결과에 답변 생성을 위한 지침을 포함하는 전략을 활용하였습니다. 검색 결과가 있을 때랑 없을 때를 구분해서 프롬프트를 분기하여, 고객센터 연락처 안내 등 폴백 응답을 명시적으로 지정합니다.
# 답변 생성 지침 예시
def generate_response_instruction(results: dict, query: str) -> str:
"""검색 결과 유무에 따른 응답 지침 생성"""
if not is_empty_result(results):
# 검색 결과가 있는 경우 프롬프트 예시: 결과 기반 답변 생성
return f"""Your task is to generate appropriate answers for the user's question
based on the data from 'search_context_data'. If the 'search_context_data' does not have enough
information, inform that you cannot answer."""
else:
# 검색 결과가 없는 경우 프롬프트 예시: 답변 불가 안내
return f"""No sufficient information available. Inform the user:
'현재 말씀해주신 {query}에 대한 정보를 제공할 수 없어요.
더 자세한 정보가 궁금하시다면 고객센터로 문의해주세요.'"""
서비스 도입 후 비즈니스 효과
AI 컨시어지 '더스틴' 도입 이후, 고객 안내 방식에 의미 있는 변화가 나타났습니다. 기존에는 매장 위치, 영업 시간, 주차 정보 등 단순 문의가 고객센터와 현장 직원에게 반복적으로 인입되었으며, 고객 역시 앱 내 여러 메뉴를 탐색해야 원하는 정보를 찾을 수 있었습니다.
더스틴 도입 후에는 이러한 단순 문의가 AI 컨시어지를 통해 즉시 해결되면서 고객센터와 현장 직원의 반복 안내 업무 부담이 감소하였습니다. 고객 입장에서도 "여자친구 생일 선물 뭐가 좋을까?"와 같은 질문만으로도 맞춤형 브랜드 추천을 받을 수 있게 되어, 기존 키워드 검색이나 메뉴 탐색 방식 대비 훨씬 직관적인 정보 접근이 가능해졌습니다. 또한 여러 정보를 통합적으로 제공해야하는 질문에도 빠르게 관련 데이터를 취합하여 정리해주는 AI 컨시어지 덕분에 고객의 쇼핑 경험을 향상시킬 수 있었습니다.
기술적인 측면에서도 성과가 있었습니다. 시스템 프롬프트 최적화, 도구 실행 결과 경량화, 대화 이력 압축 등 다양한 토큰 최적화 작업을 통해 비용 및 처리량 효율성이 높은 에이전트를 구축하였으며, 이 과정에서 축적된 노하우는 향후 유사한 AI 에이전트 서비스 확장 시 활용할 수 있는 기반이 되었습니다.
향후 계획
롯데백화점은 더스틴을 단순한 정보 안내 챗봇이 아닌, 고객의 쇼핑 여정 전반을 지원하는 개인화된 쇼핑 어시스턴트로 발전시키는 것을 목표로 하고 있습니다.
우선, 외국인 관광객을 위한 다국어 지원을 추진할 계획입니다. 영어, 일본어, 중국어 응답을 지원하기 위해 언어별 프롬프트 최적화와 다국어 고객용 데이터 보강 작업을 준비하고 있습니다. 이를 통해 롯데백화점을 방문하는 해외 관광객들도 더스틴을 통해 매장 안내와 서비스 정보 추천을 받을 수 있도록 할 예정입니다.
또한, 현재는 고객의 현재 지점과 질문 맥락만을 기반으로 응답을 생성하고 있으나, 향후에는 멤버십 정보, 선호 브랜드 등 고객 데이터를 연동하여 개인화 추천 기능을 고도화할 예정입니다. 이를 통해 고객이 매장 추천을 요청할 때 고객 정보와 선호도를 반영한 더 정확한 추천이 가능해질 것입니다.