AWS 기술 블로그
Part 1: 삼성계정 서비스의 AI SecOps, Multi-Agent로 진화하는 보안 위협 탐지
이번 포스팅은 삼성전자 서비스의 핵심, 삼성계정 서비스에서 서비스 운영에 실질적인 문제를 해결하는데 GenAI를 어떻게 활용하는지 소개 하는 2부작 시리즈 포스팅입니다. 사례가 AWS 기술블로그를 통해 세상에 알려질 수 있게 도움주신 모든 분들에게 감사의 마음을 전합니다.
- Part 1: 삼성계정 서비스의 AI SecOps – Multi-Agent로 진화하는 보안 위협 탐지 (현재)
- Part 2: 삼성계정 서비스의 GenAI Observability – 장애를 스스로 분석하는 AI
1. 개요
삼성 계정(Samsung Account)은 전 세계 20억 사용자에게 삼성 디바이스와 서비스를 연결하는 통합 인증 플랫폼입니다. 초당 270만 건의 트래픽을 365일 24시간 무중단으로 처리하며, 하루 1~2TB에 달하는 AWS WAF 로그와 그 10배에 달하는 Amazon CloudWatch 로그가 생성됩니다. 이러한 초대규모 트래픽 환경에서 Credential Stuffing, API 남용, L7 DDoS 등 지능화되는 보안 위협에 대응하기 위해, 복잡한 WAF 로그 분석부터 공격 탐지, 리포트 생성까지 수행하는 AI SecOps (Security Operation) 시스템을 구축했습니다. 이 글에서는 단순한 Text-to-SQL 에이전트에서 시작해 Multi-Agent 아키텍처로 발전하기까지, 각 단계에서 마주한 기술적 한계와 해결 방법을 실무 관점에서 다룹니다.
2. 배경 및 목표 설정
2.1 문제 정의
글로벌 서비스 규모로 인한 보안 위협
20억 사용자 규모의 계정 서비스는 그 자체로 공격자들의 주요 타깃이 됩니다. 전 세계 계정을 노린 대규모 크리덴셜 스터핑, 국가별·통신사별로 다른 2차 인증 환경의 취약점을 파고드는 SMS 우회 공격, 이미지 인식 AI를 활용한 Captcha 우회, 그리고 연계 서비스 API를 악용한 L7 DDoS까지, 공격의 유형과 규모는 일반적인 서비스와 차원이 다릅니다.
AI 발전으로 인한 공격의 지능화
AI 기술의 발전은 방어자뿐 아니라 공격자에게도 강력한 도구가 되었습니다. 공격 도구의 자동화와 지능화로 진입 장벽이 낮아지면서 공격 빈도와 변종이 급증하고 있습니다.
수동 대응의 한계
이러한 환경에서 기존의 수동적 방어 방식은 한계가 명확했습니다. 새로운 공격 패턴이 발견될 때마다 보안 엔지니어가 직접 규칙을 작성하고 배포하는 방식으로는 급증하는 공격에 대한 신속한 탐지와 대응이 불가능했습니다.
2.2 AWS WAF 기반 보안 운영
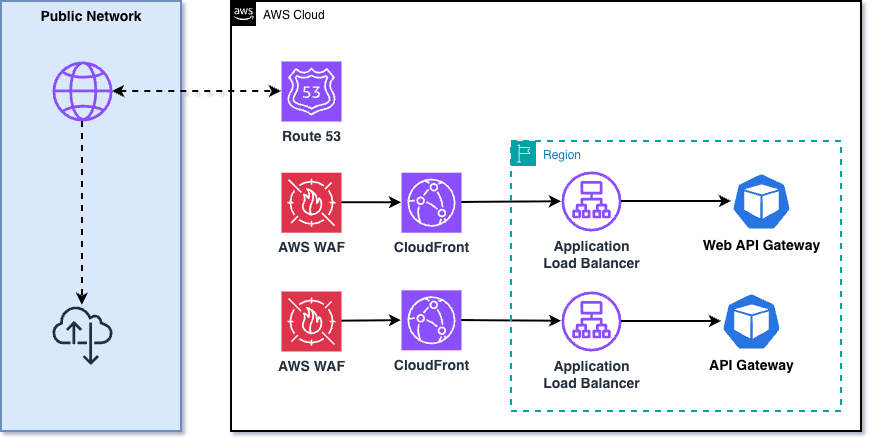
AWS WAF 기반 보안 체계
삼성 계정 서비스의 1차 방어선은 AWS WAF입니다. OWASP Top 10 취약점 차단, 사용자 정의 규칙을 통한 트래픽 필터링, Amazon CloudFront·Application Load Balancer·API Gateway와 통합된 엣지 단위 실시간 검사까지. AWS WAF는 대규모 웹 공격에 대한 강력한 보호 체계를 제공합니다. 특히 모든 HTTP/HTTPS 요청에 대한 검사 결과와 차단 이벤트가 상세히 기록되어, 소스 IP, 요청 URI, 적용된 규칙, 액션 정보 등 보안 분석에 필요한 풍부한 데이터를 확보할 수 있습니다. 이 로그 데이터는 이후 AI SecOps 시스템의 핵심 입력 데이터가 됩니다. AWS WAF가 제공하는 보호 기능과 로그 데이터는 강력하지만, 20억 사용자 규모에서 이를 최대한 활용하려면 추가적인 자동화가 필요했습니다.
기존 AWS WAF 운영의 한계
- 수동 규칙 관리의 어려움: 새로운 공격 패턴이 발견되면 보안 엔지니어가 직접 규칙을 작성하고 배포해야 합니다. 복잡한 공격의 경우 규칙 자체를 표현하기 어렵고, 변종 공격에는 빠르게 대응할 수 없었습니다.
- 오탐(False Positive/Negative) 문제: 너무 엄격한 규칙은 정상 트래픽을 차단하고(FPR, False Positive Rate), 느슨한 규칙은 공격을 놓칠 수 있습니다(TPR, True Positive Rate). TPR과 FPR의 균형을 맞추기 위해 지속적인 수동 튜닝이 필요했습니다.
- 제로데이 공격 대응 지연: 알려지지 않은 공격 기법이나 삼성 계정 서비스를 특정해 노리는 공격에는, 시그니처 업데이트를 기다리는 동안 취약한 상태에 노출될 수밖에 없었습니다.
결국 하루 수백만 건의 로그를 분석하고, 적용된 WAF Rule의 효과를 검증하며, 이 과정을 자동화하는 것이 핵심 과제였습니다.
2.3 목표 설정
앞서 정의한 과제를 해결하기 위해 세 가지 목표를 설정했습니다.
- 대규모 로그 분석: 하루 수백만 건의 WAF 로그를 분석할 수 있어야 한다.
- 규칙 효과 검증: 적용된 규칙의 TPR/FPR을 정교하게 분석할 수 있어야 한다.
- 프로세스 자동화: 이 모든 과정이 자동화되어야 한다.
이 목표를 달성하기 위해 AI 기반 접근 방식을 선택했습니다.
| 기존 과제 | 기존 과제 한계 | AI 기반 해결 방안 |
|---|---|---|
| 지능화된 변종 공격 | 규칙 기반 시스템은 Unknown Attack 방어에 실패 | LLM의 추론 능력을 활용한 패턴 분석 |
| 느린 수동 대응 | “탐지→분석→대응”의 긴 MTTD/MTTR | Agentic AI 기반 자율 대응 시스템 |
| 운영 자원의 한계 | 반복 분석 업무로 인한 인력 효율성 저하 | Agent를 통한 운영 자동화 |
이를 통해 다음을 달성하고자 합니다.
- 실시간 위협 대응 토대 마련: Agentic AI 분석 인프라를 구축하고, 자동화된 보안 리포트를 발행합니다.
- 분석 정확도 확보: AI Agent의 분석 성능을 지속적으로 개선하여 오탐을 최소화합니다.
- 클라우드 네이티브 보안 통합: Amazon EKS와 AWS WAF 연동 환경을 조성하여 확장 가능한 아키텍처를 구축합니다.
3. AI SecOps 구축 여정
3.1 Foundation Model의 도메인 지식 검증
에이전트를 직접 구축하기 전, 활용하고자 하는 Foundation Model이 보안 취약점 문제를 이해하고 발견할 수 있는지 확인하는 것이 중요합니다. 저희는 Amazon Q Developer CLI (현: Kiro-CLI)를 활용해 실제 WAF 로그 데이터에 대한 분석을 요청한 결과, 다음과 같은 보안 위협을 스스로 식별해내는 것을 발견했습니다.
- 정책 위반 트래픽 탐지: IP Reputation List 매칭, XSS 탐지, Size Restriction 위반에도 허용된 트래픽 식별
- API 남용 패턴 식별: 세션 관리 API 대량 호출, 정책/설정 정보 수집 등 정찰 활동 탐지
- 우회 공격 탐지: Rate Limiting을 피하기 위한 IP 로테이션, User-Agent 위장
- 이상 트래픽 패턴 분석: 특정 지역에서의 비정상적 트래픽 집중 식별
- 대응 방안 제시: 차단 권장 IP 대역, 모니터링 강화 포인트 제안
이 검증을 통해 Foundation Model이 WAF 로그를 분석하여 보안 위협을 식별하고, 실무에 적용 가능한 대응 방안까지 제시할 수 있음을 확인했습니다.

이를 통해 WAF 로그 검색(Text-to-SQL) → 검색된 데이터 기반 패턴 분석이라는 시스템 시나리오를 정의하고, 본격적인 에이전트 구축을 시작했습니다.
3.2 WAF 로그 분석을 위한 데이터 파이프라인 구성
AI 에이전트가 WAF 로그를 분석하려면 먼저 로그 데이터를 쿼리 가능한 형태로 준비해야 합니다. WAF 로그를 분석 가능한 형태로 만들기 위해 다음과 같은 파이프라인을 구성했습니다.
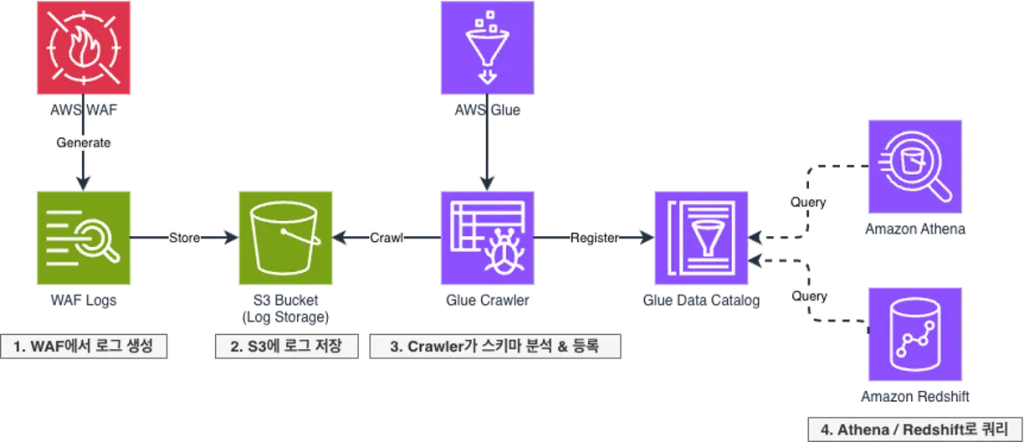
- WAF에서 로그 생성: AWS WAF가 모든 웹 요청에 대한 로그를 생성합니다. 로그에는 타임스탬프, 클라이언트 IP, 요청 URI, 적용된 규칙, 액션 정보 등이 포함됩니다.
- S3에 로그 저장: 생성된 로그는 Amazon S3 버킷에 JSON 형태로 저장됩니다. S3는 대용량 로그를 비용 효율적으로 저장하면서 다양한 분석 서비스와 연동할 수 있는 중앙 저장소 역할을 합니다.
- Crawler가 스키마 분석 및 등록: AWS Glue Crawler가 S3에 저장된 로그 파일을 스캔하여 스키마를 자동으로 추론합니다. 추론된 스키마는 AWS Glue Data Catalog에 테이블로 등록됩니다.
- Athena/Redshift로 쿼리: Data Catalog에 등록된 테이블을 통해 Amazon Athena 또는 Amazon Redshift에서 SQL로 로그를 조회할 수 있습니다.
이 파이프라인을 통해 AI 에이전트가 자연어 질문을 SQL로 변환하여 WAF 로그를 검색할 수 있는 기반이 마련되었습니다.
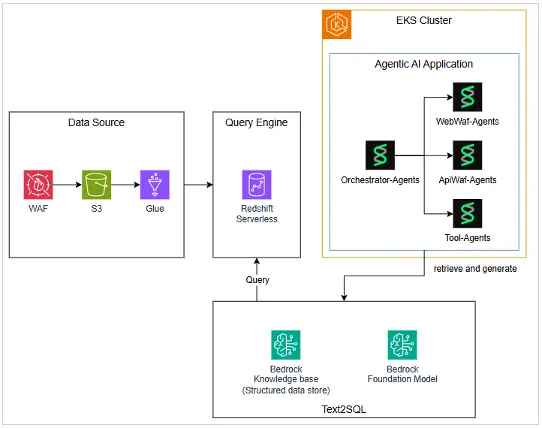
3.3 Text-to-SQL을 활용한 WAF 로그 검색 에이전트 구축
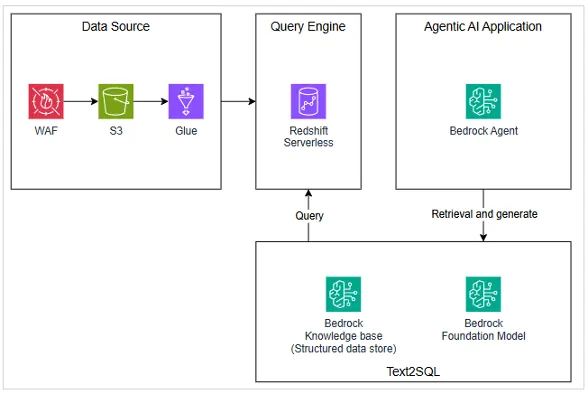
첫 번째 버전은 심플했습니다. 보안 담당자가 자연어로 질문을 하면, AI 에이전트가 이를 SQL 쿼리로 변환하여 WAF 로그 데이터베이스를 검색하고, 결과를 분석해 리포트를 생성하는 구조였습니다. 프로토타이핑 단계에서 가장 중요한 것은 빠르게 검증하는 것이다 보니, Text-to-SQL 파이프라인을 직접 구현하기보다는 AWS 관리형 서비스를 최대한 활용하여 우리가 풀고자 하는 핵심 문제 해결에 집중했습니다.
Amazon Bedrock Agents
에이전트 오케스트레이션을 위해 Amazon Bedrock Agents를 선택했습니다.
- No-Code 관리형 서비스: 인프라 관리 없이 에이전트를 빠르게 구축할 수 있습니다.
- AWS 생태계 통합: WAF 로그가 이미 AWS 환경에 있어 별도의 데이터 이동 없이 연동이 가능합니다.
- 빠른 실험: Bedrock Agent Builder 콘솔에서 프롬프트 수정과 테스트를 즉시 반복하고 배포할 수 있습니다.
Amazon Bedrock Knowledge Bases: Structured Data Retrieval
Text-to-SQL 기능 구현을 위해 Amazon Bedrock Knowledge Bases를 활용했습니다.
- Text-to-SQL 내장: 자연어를 SQL로 변환하는 기능이 이미 구현되어 있어 직접 개발할 필요가 없습니다.
- 데이터베이스 직접 연동: Amazon Redshift Serverless와 네이티브로 연결되어 별도의 커넥터 구현이 불필요합니다.
- 스키마 자동 인식: 연결된 데이터베이스의 테이블 구조를 자동으로 파악하여 쿼리 생성에 활용합니다.
이 조합을 통해 빠르게 “자연어 질문 → SQL 변환 → WAF 로그 검색 → 결과 분석”이 가능한 프로토타입을 구축할 수 있었습니다.
3.4 Text-to-SQL 성능 개선
Amazon Bedrock Knowledge Base에 Redshift Serverless를 연동하여 초기 에이전트를 구축했을 때, 단순한 질문에는 잘 답변했지만, 다수의 테이블을 조인하거나 특정 보안 조건을 필터링해야 하는 복잡한 분석 요청에서는 부정확한 SQL을 생성하는 문제가 발견되었습니다. LLM이 생소한 데이터베이스 스키마를 완벽히 이해하고 정교한 SQL을 작성하게 하기 위해서는, 모델에게 더 상세한 컨텍스트와 모범 답안을 제공해야 합니다. Amazon Bedrock Knowledge Bases의 Query Configuration 기능을 활용해 두 가지 핵심적인 개선을 수행했습니다.
Schema Description 최적화를 통한 컨텍스트 제공
LLM이 각 필드의 역할과 의미를 명확히 이해할 수 있도록 상세한 설명을 추가했습니다. 이를 통해 LLM은 단순한 텍스트 매칭이 아니라, 데이터의 의미와 구조적 맥락을 이해하고 쿼리를 설계할 수 있게 되었습니다. 또한 포함/제외(Inclusions/Exclusions) 설정을 통해 분석에 불필요한 테이블 또는 컬럼을 배제함으로써, LLM이 잘못된 데이터를 참조할 확률을 원천적으로 차단했습니다.
Curated Query 도입을 통한 Few-Shot Prompting
보안 분석에는 특정한 패턴이나 도메인 특화 로직이 필요한 경우가 많습니다. 이를 위해 큐레이트된 쿼리(Curated Queries) 기능을 도입했습니다. 자주 사용되는 질의와 검증된 SQL 쿼리 쌍을 예시로 등록하면, LLM은 이 모범 답안을 참고하여 유사한 질문에 대해 구문 오류 없이 정확한 문법과 로직으로 SQL을 생성하게 됩니다.
3.5 정교한 워크플로우 제어를 위한 Strands Agents 도입
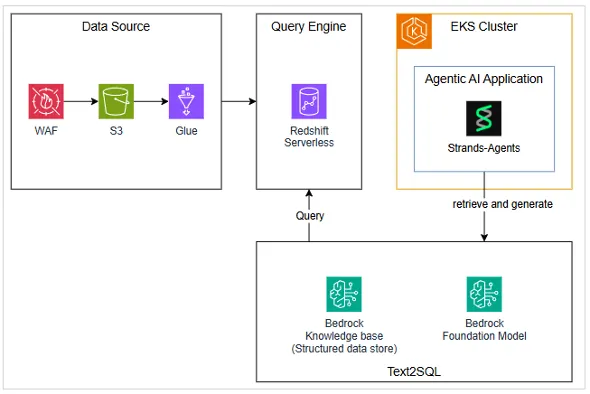
기존 Bedrock Agent의 한계
초기 프로토타이핑 단계에서 Amazon Bedrock Agents는 인프라 관리 없이 에이전트를 즉시 배포하고 테스트할 수 있어 매우 효율적이었습니다. 하지만 본격적인 AI SecOps 시스템을 구현하는 과정에서, WAF 로그 분석 업무가 단순한 질의응답을 넘어서 복잡한 워크플로우가 요구되었고, Bedrock Agent는 프롬프트 기반 Orchestration에 의존하기 때문에, 이러한 정교한 실행 흐름을 제어하기 어려웠습니다.
Strands Agents를 선택한 이유
이에 따라 AWS에서 제공하는 오픈 소스 SDK인 Strands Agents 도입을 결정했습니다. Strands Agents가 제공하는 그래프 기반의 정교한 태스크 제어와 병렬 실행, 그리고 Python 환경의 유연한 Tool 연동 기능은 복잡한 에이전트 워크플로우를 구현하는 데 유용하게 활용되었습니다. LangGraph와 같은 다른 프레임워크도 함께 고려했으나, 빠른 프로토타이핑과 AWS 서비스와의 통합에 강점이 있는 Strands Agents를 최종 선택했습니다.
Amazon Bedrock Agent vs Strands Agents 비교
| 비교 항목 | Amazon Bedrock Agent | Strands Agents (Python SDK) |
|---|---|---|
| 개발 방식 | Low-Code / No-Code (콘솔 중심) | Code-First (Python 코드 중심) |
| Workflow 제어 | 프롬프트 기반의 Orchestration에 의존 | 개발자가 실행 흐름을 직접 설계 |
| Tool 연동 | Lambda 함수 연결, API 스키마 정의 필수 | Python 함수/클래스로 유연하게 정의 가능 |
| 디버깅 | Trace Logs를 통한 사후 분석 중심 | IDE를 활용한 실시간 디버깅 및 테스트 용이 |
| 적합 대상 | 빠른 프로토타이핑, 표준화된 태스크 | 복잡한 로직, 정교한 제어가 필요한 복잡한 에이전트 앱 |
단일 에이전트(Single Agent)의 한계
Strands Agents로 전환하며 정교한 워크플로우 제어가 가능해졌지만, 하나의 에이전트가 모든 분석 과정을 전담하는 구조(Single Agent)에는 한계가 있습니다.
- 성능 저하: 방대한 컨텍스트 처리로 인한 토큰 과소비 및 병목 현상 발생
- 정확도 이슈: 과도한 역할 부여로 전문성이 희석되며 할루시네이션(Hallucination) 빈도 증가
- 통찰력 부족: 운영자가 즉시 활용하기에는 부족한 리포트 품질
이러한 단일 에이전트의 구조적 한계를 극복하기 위해, 역할이 명확히 분리된 Multi-Agent 아키텍처로의 전환을 결정했습니다.
3.6 Multi-Agent 아키텍처 도입
우리는 단일 에이전트의 한계를 극복하기 위해 역할을 세분화하고, 4가지 핵심 페르소나(Orchestrator, Actor, Supervisor, Reporter)를 정의했습니다. 이들은 서로 협력하며 전략 수립 → 실행 → 검증 → 보고를 수행합니다.
설계 원칙
- 불필요한 에이전트 실행 방지: 사용자의 의도를 파악하고 불필요한 분석 단계를 생략하여 리소스를 최적화합니다.
- 전문화된 에이전트 분리: 각 에이전트는 하나의 명확한 책임만 가집니다. 프론트엔드, 백엔드, 인프라 등 도메인별로 에이전트를 분리하여, 각자의 전문 영역에만 집중하도록 합니다.
- 병렬 처리를 통한 성능 최적화: 다수 에이전트가 병렬로 분석을 진행하여 실행 속도를 개선합니다.
- 피드백 루프 구현: 에이전트가 생성한 결과물을 검증하고, 특정 기준에 미치지 않으면 재작업을 요청하여, 전체 시스템의 신뢰성을 향상시킵니다.
Agent 별 역할 및 상세 워크플로우
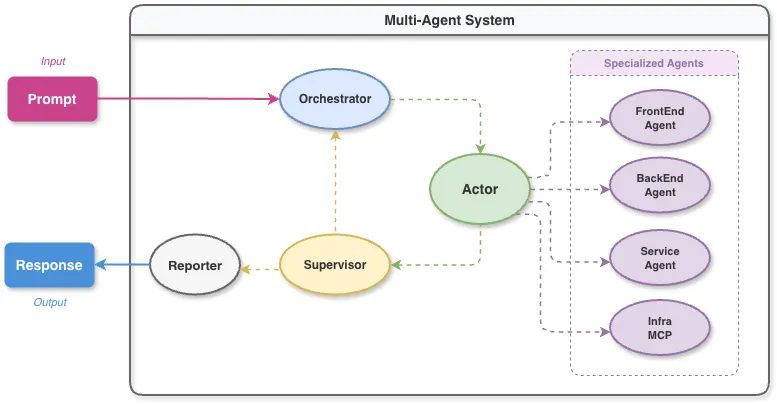
| Agent | 역할 (Persona) | 핵심 기능 |
|---|---|---|
| Orchestrator | 프로세스 통제 | 사용자 의도 파악, 위협 복잡도 판단, 불필요한 분석 단계 생략을 통한 리소스 최적화 |
| Actor | 병렬 분석 실행 | Strands Graph 기반으로 다수의 전문 에이전트(SQL Gen, Log Analysis 등)를 병렬 실행 및 결과 취합 |
| Supervisor | 품질 보증(QA) | 교차 소스 일관성 검증, 데이터 노이즈 제거, 오탐(False Positive) 판별 및 재작업 지시 |
| Reporter | 리포트 생성 | 검증된 데이터를 바탕으로 통찰력 있는 최종 리포트 생성 |
시스템은 단순히 순차적으로 동작하는 것이 아니라, 결과 품질이 기준에 미달할 경우 재작업(Feedback Loop)을 수행하는 구조를 가집니다.
- 사용자 프롬프트 입력: 보안 운영자가 자연어로 분석을 요청합니다.
- 전략 수립 (Orchestrator): 요청의 복잡도를 판단하여 분석 전략을 수립합니다. 단순 조회인 경우 불필요한 심층 분석 단계를 생략하여 토큰 비용과 시간을 절약합니다.
- 병렬 실행 (Actor): 수립된 전략에 따라 실제 데이터 조회 및 분석을 수행합니다. Strands의 그래프 기능을 활용해 다수의 에이전트가 동시에 실행되며 결과를 취합합니다.
- 품질 검증 (Supervisor): 취합된 결과의 논리적 모순이나 오탐 가능성을 검증합니다.
- Pass: Reporter에게 데이터 전달
- Fail: Orchestrator에게 구체적인 피드백과 함께 재작업 요청 (Iterative Process)
- 리포팅 (Reporter): 검증된 결과를 바탕으로 최종 보안 리포트를 생성하여 사용자에게 전달합니다.
최종 아키텍처 확정 후 성과
이러한 Multi-Agent 아키텍처는 Amazon EKS 클러스터 상에서 컨테이너화되어 운영됩니다. 이로 인해 아래와 같은 성과를 얻었습니다.
- 리포트 품질 및 통찰력 확보: Reporter 에이전트를 별도 도입하여 분석 결과의 가독성과 통찰력을 획기적으로 높였습니다.
- 분석 정확도 향상 (Hallucination 최소화)
- 역할 분리(SRP)를 통해 각 모델의 집중도를 높였습니다.
- 필요한 도메인 지식(API 문서, 과거 대응 이력)은 RAG로 연동하여 정보의 정확성을 보강했습니다.
- Supervisor의 교차 검증으로 오탐을 획기적으로 줄였습니다.
- 역할 분리를 통한 정확도 향상: 단일 에이전트의 역할 과부하 및 할루시네이션 문제를 해결했습니다. 필요한 정보는 RAG 툴로 등록하여 정보 정확성을 높였습니다.
- 시스템 처리 속도 및 운영 효율 개선: 에이전트 간 역할 분리를 통해 시스템 처리 속도가 빨라지고 운영 효율성까지 개선되었습니다.
결과적으로, 삼성 계정 서비스는 정교한 보안 분석 워크플로우를 자율적으로 처리하는 AI SecOps 환경을 구축할 수 있었습니다.
4. 실제 공격 탐지 사례
이 시스템이 실제 운영 환경에서 어떻게 위협을 탐지하고 대응했는지, 두 가지 구체적인 사례를 통해 살펴보겠습니다.
4.1 Brute Force + WordPress 공격 탐지
첫 번째 사례는 인프라의 이상 징후가 보안 위협으로 연결된 케이스입니다.
공격 징후 포착
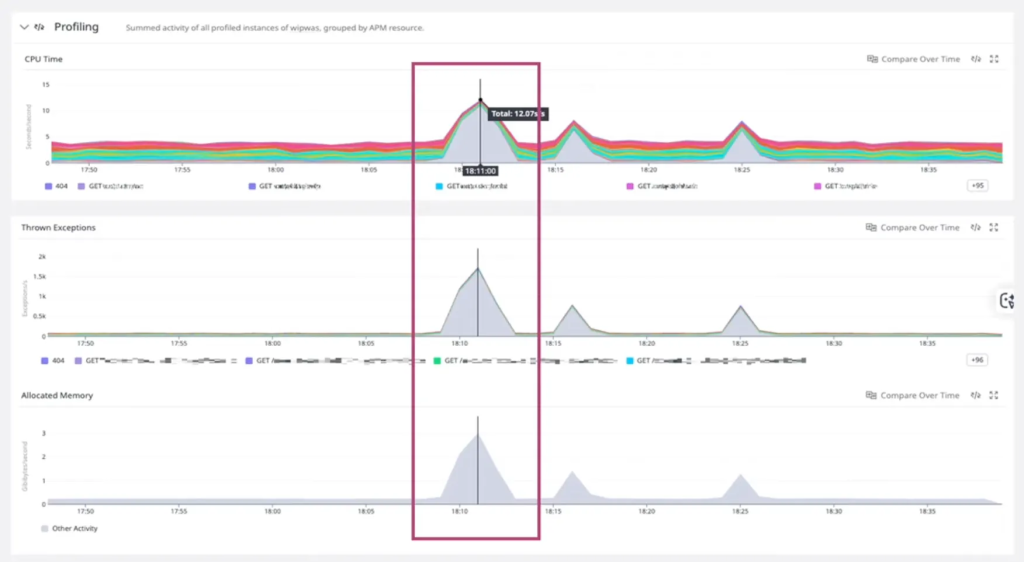
평소 2% 수준으로 유지되던 요청 실패율(4xx/5xx Error Rate)이 갑자기 20% 이상으로 급증했습니다. 동시에 백엔드 리소스의 CPU 및 메모리 사용량이 비정상적으로 치솟는 패턴이 CloudWatch 알람을 통해 감지되었습니다.
AI 에이전트 분석 결과
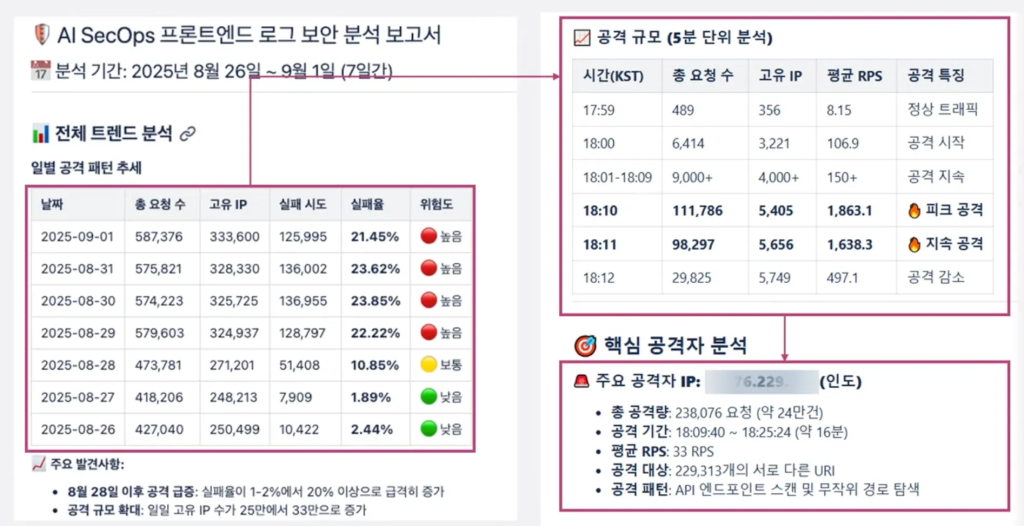
주요 공격자 IP 주소, 공격 유형, 분당 TPS를 종합 파악한 결과, 단순한 트래픽 증가가 아닌 복합 공격임을 밝혀냈습니다.
- 위협 식별: 대규모 SQL Injection 시도와 L7 DDoS 공격 및 스캐닝 공격
- 공격 패턴: 삼성 계정 서비스 스택과 무관한 WordPress 관리자 페이지(wp-login.php, wp-admin)를 타깃으로 한 무차별 대입(Brute Force) 공격이 2만 건 이상 확인됨
- 결론: 좀비 PC들로 구성된 봇넷(Botnet)이 취약점을 찾기 위해 무차별 스캐닝을 시도하는 상황으로 판단
즉각적인 조치
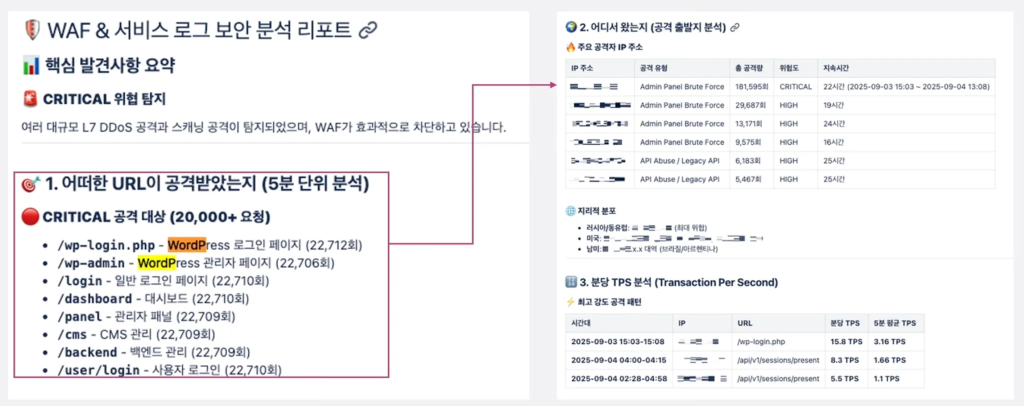
Reporter Agent는 공격을 주도하는 주요 소스 IP 대역과 Attack Signature를 정리하여 즉시 차단 규칙 생성을 제안했습니다. 운영팀은 이를 기반으로 신속하게 블랙리스트를 적용하여 리소스 사용량을 정상화할 수 있었습니다.
4.2 Scanning Attack with DDoS
두 번째 사례는 단순 임계치(Threshold) 기반의 탐지 시스템으로는 식별하기 어려운, 지능적인 패턴의 공격입니다.
공격 패턴 확인
약 20개의 분산된 IP에서 총 16만 건 이상의 요청이 유입되었습니다. 요청량이 아주 많지는 않았으나, 특정 경로에 대해 지속적인 접근을 시도하는 이상 행동이 관측되었습니다.
AI 에이전트 분석 결과
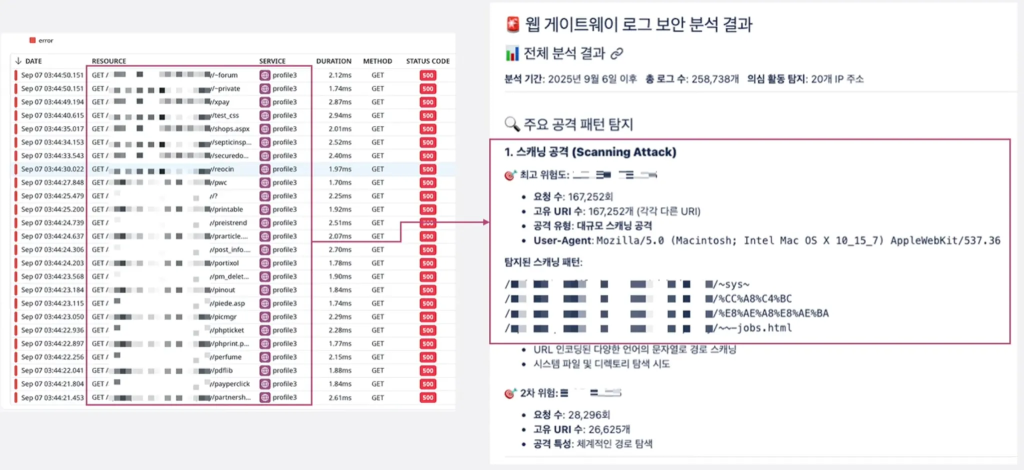
AI Agent는 로그의 URL 패턴을 분석하여 이것이 단순 접속 시도가 아닌, 조직적인 퍼징(Fuzzing) 공격임을 정확히 추론해 냈습니다.
- 공격 규모: 20개 IP에서 160,000+ Request 발생
- 패턴 분석: 내부 API 경로(/api/v1/internal/) 뒤에 랜덤한 문자열을 조합하여 유효한 엔드포인트를 찾으려 시도
- 결론: 외부에 공개되지 않은 내부 관리자 API나 테스트 엔드포인트를 찾아내기 위한 정찰 행위로 판단
즉각적인 조치
단순히 404 에러가 많다는 통계적 사실을 넘어서, 에이전트는 랜덤 문자열을 이용한 체계적인 스캐닝 패턴을 정확히 포착하고 공격 의도까지 파악하여, 보안팀은 단순 차단을 넘어, 해당 경로에 대한 접근 제어 정책을 전반적으로 재점검하는 근본적인 대응을 할 수 있었습니다.
5. 핵심 교훈 (Key Takeaways)
Single Agent에서 Multi-Agent로의 전환 필요성
복잡한 비즈니스 로직을 하나의 에이전트가 모두 처리하려 할 때 성능 저하와 판단 오류가 발생합니다. 소프트웨어 설계의 단일 책임 원칙(SRP)과 마찬가지로, 에이전트 또한 역할을 명확히 분리하고 협업하는 구조가 훨씬 더 안정적이고 확장성 있습니다.
프롬프트 엔지니어링과 컨텍스트 오염 방지
많은 정보를 한 번에 주입하면 에이전트는 혼란을 겪습니다(Context Pollution). 에이전트를 분할하여 각자가 필요한 최소한의 정보만 처리하게 함으로써, 할루시네이션을 효과적으로 억제할 수 있습니다.
병렬 처리를 통한 Token 및 성능 최적화
단일 에이전트가 순차적으로 일을 처리하면 토큰 비용과 대기 시간이 기하급수적으로 늘어납니다. 독립적인 태스크를 병렬로 수행하는 멀티 에이전트 아키텍처는 처리 속도를 개선할 뿐만 아니라, 불필요한 연산을 줄여 토큰 효율성을 높입니다.
점진적 고도화 전략
처음부터 완벽한 시스템을 설계하려 하기보다, 작게 시작하며 단계별로 문제를 발견하는 점진적 접근법이 리스크를 줄이고 실질적인 문제를 해결하는 데 효과적입니다.
6. 향후 계획
AI 기반 실시간 자율 대응 체계 완성
현재 시스템이 분석과 제안에 집중했다면, 다음 단계는 자율적으로 행동하는 것입니다. 현재 분석된 WAF 로그 결과를 활용하여 대규모 트래픽에서 의미 있는 보안 특징(Feature)을 자동으로 추출하고, 이를 기반으로 정교한 ML 모델을 학습하고, 이 ML 모델이 예측한 위협 지수와 공격 유형을 바탕으로 사람 개입 없이 WAF 규칙을 동적으로 생성하고 배포하는 자율 방어 시스템을 구축할 예정입니다.
AI Ops로의 확장 통합
AI의 상황 인지(Contextual Awareness) 시스템은 보안에만 국한되지 않습니다. 이를 서비스 전반의 운영 영역으로 확장하여, 시스템 성능 저하, 장애 징후 등을 사전에 감지하고 대응하는 포괄적인 AIOps 체계를 구축하고자 합니다.
7. 결론 및 시사점
20억 사용자 규모 서비스에서 발생하는 지능화된 위협과 방대한 로그는 더 이상 사람의 수동적 노력만으로는 대응할 수 없습니다. 우리는 LLM의 추론 능력과 Agentic AI의 실행 능력을 결합함으로써, 기존 관제 시스템의 한계를 넘어 빠르고 정교하며 통찰력 있는 차세대 보안 운영 환경을 구축했습니다. 이번 포스팅이 대규모 트래픽 환경에서 AI를 활용한 보안 운영 효율화를 고민하는 많은 엔지니어분들에게 의미 있는 영감이 되기를 바랍니다.
이 블로그 게시물은 삼성전자 Samsung Account 서비스 개발팀과 AWS Korea의 협업으로 작성되었습니다.
참고 자료
- STC25 발표 영상
- Amazon Bedrock
- Amazon Bedrock Agents
- Amazon Bedrock Knowledge Bases
- AWS WAF
- Amazon Redshift Serverless
- Amazon EKS
다음 편 예고
Part 2에서는 Datadog MCP를 활용한 GenAI Observability 구축 사례를 다룹니다. 실제 LSE(Large Scale Event) 상황에서 AI가 자동으로 Root Cause를 분석한 사례를 공유합니다.
Part 2: 삼성계정 서비스의 GenAI Observability – 장애를 스스로 분석하는 AI →