AWS 기술 블로그
리멤버앤컴퍼니의 Amazon S3 Tables를 활용한 실시간 분석 워크로드 구축하기 1부: S3 Tables에 CDC 데이터 레이크 구축하기
리멤버앤컴퍼니 소개

리멤버앤컴퍼니는 대한민국 직장인 500만 명 이상이 사용하는 국내 대표 비즈니스 플랫폼입니다. ‘일하는 사람과 기회를 연결한다’는 미션 아래 개인에게는 명함 관리, 커리어 관리, 비즈니스 인물 검색 플랫폼 ‘리멤버 커넥트’, 커뮤니티 서비스 등을 통한 성장의 기회를 제공하고, 기업 대상으로는 인재 채용과 고객 발굴의 생산성을 높이는 B2B 솔루션을 제공하며 독보적인 비즈니스 생태계를 구축해 나가고 있습니다.
수준 높은 방대한 인재 데이터와 AI 기술을 결합한 HR 플랫폼으로서, 기업의 우수 인재 채용 속도와 정확도를 획기적으로 높여 대한민국 채용 시장을 선도해 나가고 있습니다. 전통적인 방식과 차별화된 데이터 테크 기반의 리멤버 마케팅 솔루션은 B2B 타겟광고, 타겟 시장 조사, 세일즈 리드 획득 솔루션 등을 통해 기업이 고객에게 정확하고 빠르게 닿을 수 있도록 도와 마케팅 효율을 극대화합니다.
리멤버는 독보적이고 강력한 데이터 자산과 AI 기술력을 접목한 제품 경쟁력을 기반으로 혁신적 방식으로 시장의 변화를 선도하며, 국내 대표 비즈니스 플랫폼으로서의 입지를 더욱 확고히 다지고 있습니다.
도입 배경
리멤버에서는 수억 건의 명함을 처리하기 위한 분석용 아키텍처로 Amazon S3에 Parquet 파일을 적재하고 Presto를 사용해 대용량 데이터를 분석하고 있었습니다.
기존 방식의 문제점
1. Full Refresh 기반 데이터 처리 방식의 비효율성
- 리멤버에서는 매일 새벽 Amazon EMR과 Sqoop을 이용해 Amazon Aurora MySQL의 운영 데이터를 S3로 전체 적재(Full Refresh) 하는 파이프라인을 운영하고 있었습니다. 이 과정에서 매번 수십억 건의 데이터를 전량 읽어오는 배치 작업이 반복되었고, 데이터 볼륨이 커질수록 Aurora MySQL과 S3 모두에 높은 부하가 발생했습니다. 이 데이터는 Hive 포맷으로 S3에 저장되었으며, EMR 기반의 Presto 클러스터를 통해 분석이 수행되었습니다.
- Full Refresh 방식은 매일 동일한 데이터까지 반복해서 읽고 써야하기 때문에 구조적 비효율성이 존재했습니다. 그 결과 S3의 PUT/GET 요청, EMR I/O, 그리고 Aurora MySQL의 Read I/O 부하가 지속적으로 증가하며 운영 비용이 빠르게 상승했습니다.
2. 운영 DB를 통한 실시간 분석의 한계
- Aurora MySQL의 Reader 인스턴스는 운영 데이터의 읽기 복제본으로, 일부 실시간 분석 쿼리의 데이터 소스로도 활용되었습니다. 대용량 집계나 실시간 쿼리가 실행될 경우, MySQL 내부의 HLL(History List Length) 지표가 급격히 증가하는 문제가 자주 발생했고 이로 인해 롱 쿼리(Long Query)가 트랜잭션 커밋을 지연시키고, InnoDB Undo Log가 쌓이면서 운영 트랜잭션의 응답 지연(latency)으로 이어지는 문제가 발생했습니다.
- 또한 운영 데이터와 분석 데이터의 동기화 주기가 하루에 한 번(새벽 배치)이다 보니, 실시간 분석이 필요한 경우 Presto에서 Aurora MySQL을 Federated Source로 직접 조회해야 했습니다. 이 경우 쿼리가 잘못 작성되거나 필터링이 누락되면, 수십억 건의 데이터를 직접 스캔하면서 Reader 인스턴스에 높은 부하가 발생했습니다.
- 결과적으로 운영 트랜잭션(OLTP)과 분석 쿼리(OLAP)가 같은 DB 리소스를 공유하면 운영 안정성과 실시간 분석 성능을 동시에 보장하기 어려운 구조적 한계에 부딪혔습니다.
이러한 문제를 해결하기 위해 리멤버에서는 다음과 같은 기술적 목표를 설정했습니다.
- Incremental Update 기반의 데이터 적재
매번 전체 데이터를 다시 읽는 대신, 변경분(CDC)만 반영하여 효율적인 데이터 동기화 수행 - 실시간 혹은 준실시간 분석 지원
Aurora Reader 인스턴스에 직접 쿼리를 수행하지 않고, Iceberg 기반의 분석 레이크하우스로 전환하여 실시간 수준의 대시보드 및 지표 계산 가능
그리고 이러한 목표들을 달성하기 위한 방법으로 Amazon S3 Tables(Iceberg) 를 도입하기로 결정했습니다.
- Iceberg는 오픈테이블 포맷으로 Incremental Update 지원하기 때문에 매번 전체 데이터를 다시 읽지 않고 변경 분만 반영할 수 있음
- 변경 사항을 거의 실시간에 가깝게 적용할 수 있기 때문에 OLAP와 OLTP를 분리하여 Reader 인스턴스에 부하를 주지 않고도 실시간 분석 가능
리멤버 데이터 분석 파이프라인 아키텍처
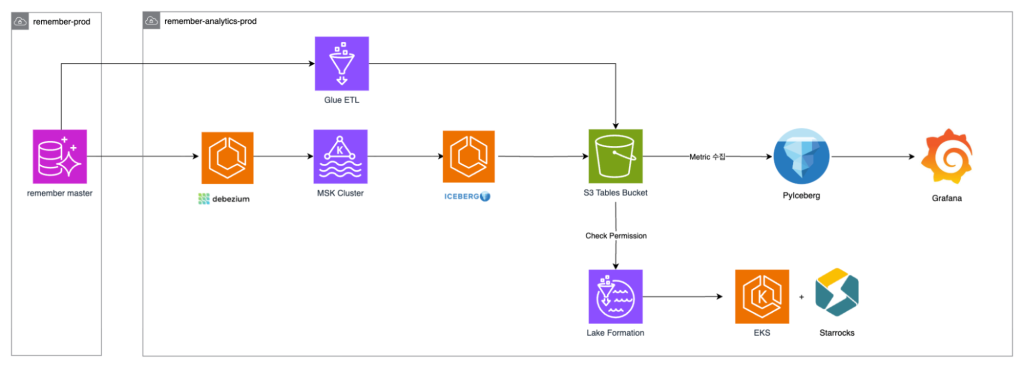
리멤버의 데이터 분석 파이프라인은 운영 데이터의 안정성을 유지하면서, 실시간에 가까운 분석을 지원하도록 설계되었습니다. 전체 데이터 흐름을 단계별로 살펴보면 다음과 같습니다.
- Amazon Aurora MySQL
- 운영 데이터베이스 역할을 수행하며, 유저 활동 로그와 핵심 트랜잭션 데이터를 저장합니다.
- 기존에는 분석 쿼리가 직접 Aurora에 부하를 주었지만, 현재 파이프라인에서는 읽기 전용으로 데이터를 안전하게 추출합니다.
- Debezium을 통한 변경 데이터 캡처 (CDC)
- Aurora에서 발생하는 데이터 변경 사항(INSERT, UPDATE, DELETE)을 실시간으로 캡처합니다.
- Debezium은 변경 이벤트를 Kafka 토픽 형식으로 변환하여 Amazon MSK(Managed Streaming for Apache Kafka)클러스터로 전달합니다.
- Amazon MSK Cluster
- 변경 데이터를 안정적으로 전달하고, 중간 버퍼 역할을 수행합니다.
- MSK를 통해 실시간 이벤트가 Iceberg 기반 S3 테이블로 안전하게 전달됩니다.
- Apache Iceberg 기반 Amazon S3 Tables
- 변경 데이터를 Incremental Update 가능한 오픈 테이블 포맷으로 저장합니다.
- 기존 Full Refresh 방식과 달리, 변경된 데이터만 반영하기 때문에 S3 I/O 비용과 Aurora Reader 부하를 크게 줄일 수 있습니다.
또한, 테이블 스키마 변경에도 유연하게 대응할 수 있으며, Amazon Athena 및 Presto 기반 분석 워크로드와 호환됩니다.
- Lake Formation & 권한 관리
- S3 Tables에 대한 접근 제어와 권한 체크를 수행합니다.
- 분석 팀과 BI 도구에서 안전하게 데이터를 조회할 수 있도록 보장합니다.
- Amazon EKS 위 StarRocks
- Incremental Sync된 데이터를 StarRocks로 로딩하여, 고성능 실시간 분석 쿼리를 지원합니다.
- Materialized View와 인덱스를 활용하여, 사용자 대시보드에서 ms 단위 수준의 저지연 조회가 가능합니다.
- EKS 환경에서 운영되므로 리소스 확장과 관리가 유연합니다.
- 분석 및 시각화 (Plyceberg + Grafana)
- PyIceberg(Plyceberg)를 통해 S3 Tables 데이터를 Python 환경에서 읽어 분석합니다.
- Grafana와 연동하여 시각화, 모니터링, 대시보드 제공을 수행합니다.
기존 데이터 마이그레이션
S3 Tables 기반 데이터 레이크를 구축할 때, 가장 먼저 기존 데이터를 마이그레이션하는 작업이 필요합니다. 리멤버에서는 기존 Aurora MySQL에 저장된 데이터를 대상으로, 1/Full Load, 2/CDC(Change Data Capture) 동기화 순서로 마이그레이션을 진행했습니다.
Full Load 용 복제 인스턴스 생성
수십억 건 단위의 데이터를 한 번에 마이그레이션할 경우, 운영 환경에 직접적인 영향을 줄 수 있습니다. 이를 방지하기 위해 Full Load 전용 복제본(Replica)을 생성합니다.
- 복제본은 마이그레이션 작업 완료 후 삭제
- 데이터 볼륨에 따라 CPU, 메모리 등 스펙을 적절히 구성
- 독립된 복제본이기 때문에 운영 중인 Production DB에 부하 최소화 가능
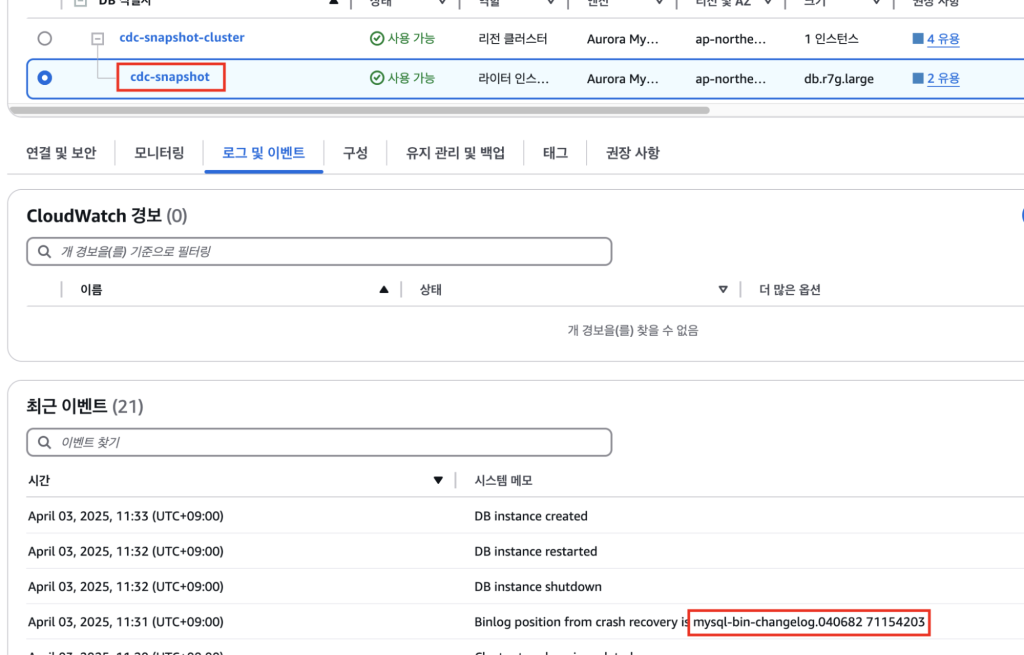
복제본이 준비되면, 해당 복제본의 Binlog가 표시됩니다. 이는 CDC 동기화 시작 지점을 나타내며, 이후 실시간 데이터 반영 시 기준점으로 활용됩니다.
S3 Tables로 데이터 마이그레이션
AWS에서 데이터를 마이그레이션 할 때, 일반적으로 AWS DMS(AWS Database Migration Service)를 사용합니다.
다만, 현재 DMS는 Iceberg 테이블 대상 마이그레이션을 지원하지 않기 때문에, 별도의 방법이 필요했고 리멤버에서는 AWS Glue(PySpark)를 활용하여 Aurora MySQL 데이터를 S3 Tables로 안전하게 이전했습니다.
AWS Glue(PySpark) Job으로 Aurora MySQL → S3 Tables 로 데이터를 이관하는 전체 흐름은 다음과 같습니다.
- AWS Glue(PySpark)와 S3 Tables 연결
- CDC 용 RDS 연결
- 대상 테이블을 병렬로 읽어 S3 Tables에 저장
AWS Glue(PySpark)에서 S3 Tables에 접근하는 방법은 3가지가 있습니다.(AWS 공식 가이드 참고) 리멤버에서는 그중 Java 라이브러리를 통해 AWS S3 Tables Catalog에 직접 접근하는 방식으로 진행했습니다.
AWS 공식 Github에서 제공하는 JAR 파일을 S3에 업로드한 후, Glue Job의 Dependent JARs path 에 등록하면 Spark configuration 설정을 통해 Spark Session에서 S3 Tables에 접근할 수 있습니다.
Spark을 통해 S3 Tables에 접근하기 위해 반드시 설정해야 하는 항목은 아래와 같습니다.
| key | value |
|---|---|
| spark.sql.catalog.s3tablesbucket | org.apache.iceberg.spark.SparkCatalog |
| spark.sql.catalog.s3tablesbucket.catalog-impl | software.amazon.s3tables.iceberg.S3TablesCatalog |
| spark.sql.catalog.s3tablesbucket.warehouse | AWS S3Tables Bucket ARN |
| spark.sql.defaultCatalog | s3tablesbucket |
| spark.sql.extensions | org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions |
| spark.sql.catalog.s3tablesbucket.cache-enabled | true |
리멤버에서는 추가적으로 ENUM, Timestamp 타입 처리를 위해 아래 항목을 설정해주었습니다.
| key | value | notes |
|---|---|---|
| spark.sql.parquet.int96RebaseModeInWrite | CORRECTED | 1900-01-01 이전 타임스탬프에서 Julian과 Proleptic Gregorian 달력 차이를 처리하는 방식에 대한 설정입니다. CORRECTED로 설정 시, 기존값을 그대로 사용합니다. |
| spark.sql.readSideCharPadding | false | MySQL의 ENUM 타입과 CHAR 타입은 Spark의 기본 설정 하에서는 Padding이 포함된 STR로 변환됩니다. 이를 방지하기 위한 설정입니다. |
위의 항목들은 Glue Job parameters 또는 PySpark의 SparkSession config를 통해 설정할 수 있습니다.
이제 Spark에서 외부 JDBC 연결을 통해 스냅샷 복제본에 접근하여 데이터를 S3 Tables로 이관합니다.
이 과정에서 저희는 추가적으로 JDBC 연결에서 대상 테이블의 크기와 관계없이 100만 건씩 나누어 처리될 수 있도록 아래와 같이 동적 파티션 수 조절을 적용했습니다.
# 테이블의 min/max ID 쿼리
minmax_df = spark.read.jdbc(
url=jdbc_url,
table=f"(SELECT MIN(id) as min_id, MAX(id) as max_id FROM {db}.{table}) AS minmax_{db}_{table}",
properties=jdbc_properties
)
min_max_row = minmax_df.collect()[0]
min_id = min_max_row['min_id']
max_id = min_max_row['max_id']
# 각 파티션이 처리할 행 수 계산
rows_per_partition = {원하는 처리량}
partition_count = max({최소파티션 수}, min({최대파티션 수}, int((max_id - min_id) / rows_per_partition)))
# Property 추가
current_jdbc_properties |= {
"partitionColumn": "id",
"lowerBound": str(min_id),
"upperBound": str(max_id),
"numPartitions": str(partition_count)
}
target_df = spark.read.jdbc(
url=jdbc_url,
table=f"{db}.{table}",
properties=current_jdbc_properties
)
이를 통해 작은 크기의 테이블에서부터 10억 건 이상의 대용량 테이블까지 적절한 Workload를 유지하면서 이관 작업을 진행할 수 있었습니다.
최종적으로는 Spark SQL 또는 Spark Dataframe의 write 메소드를 통해 S3 Tables에 데이터를 저장할 수 있습니다.
CREATE OR REPLACE TABLE s3tablesbucket.{db}.{table}
USING iceberg
TBLPROPERTIES (
'format-version' = '2'
)
AS
SELECT * FROM target_dftarget_df.write.format("iceberg").mode("overwrite").saveAsTable(f"{db}.{table}")이렇게 구성할 경우 PySpark를 이용해 대용량 테이블을 병렬로 읽을 수 있으며 운영 환경과 분리되어 있기 때문에 서비스에 영향 없이 마이그레이션이 가능합니다. G4X(16vCPU / 64 Mem) 20 Worker 기준 수십억건의 테이블도 20~30분내 처리가 가능했습니다. 발생한 DPU 사용량은 약 37.5 DPU Hours로, $16.5 수준의 저렴한 비용으로 빠르게 마이그레이션할 수 있습니다.
Amazon MSK를 활용한 CDC 파이프라인 구성
리멤버에서는 CDC를 위해 Mananged kafka인 Amazon MSK를 허브로 구성했습니다.
MSK를 선택하게 배경은 다음과 같습니다:
- S3 Tables를 CDC 대상으로 바로 사용할 수 있는 서비스가 제한적
- Amazon Data Firehose의 유연성에 제약이 많아 복잡한 시나리오 적용이 어려움
MSK를 사용함으로써 얻게 된 이점은 다음과 같습니다.
- 실시간 데이터 스트리밍 허브로 활용 가능
- 다수의 CDC 소스를 통합하여 다양한 데이터 소비자에 배포 가능
- Kafka 기반 파이프라인이므로 확장성, 유연성, 내결함성 확보
즉, MSK는 S3 Tables를 대상으로 한 CDC 파이프라인의 중앙 허브 역할을 수행하며, Firehose 등 기존 AWS 매니지드 서비스로는 구현하기 어려운 유연성과 확장성을 제공합니다.
Kafka Connect 운영 방식
CDC를 위한 패키지로 아래의 Connector를 사용하고 있습니다.
- Source : Debezium MySQL Connector
- Sink : Icegerg Kafka Connector
리멤버는 Databricks가 제공하는 Iceberg Kafka Connect를 사용했습니다. 이 Connector는 2024년 6월 7일 v0.6.19 버전을 마지막으로 Apache Iceberg 프로젝트에 기부되어 더 이상 개발되지 않고 있습니다. Apache Iceberg 공식 Repository의 Kafka Connect는 Upsert 기능을 지원하지 않아 CDC 파이프라인 구축이 불가능합니다.
현재 관련 기능에 대한 논의가 활발히 이루어지고 있어 향후에는 지원되길 기대합니다.
따라서, CDC 구현을 위해서는 Databricks 버전을 선택이 불가피했고, 해당 Connector를 기반으로 S3 Tables Sink 파이프라인을 구축했습니다.
도입 초기에는 Managed Kafka Connect 서비스(MSK Connect)를 사용해서 커넥터를 관리했으나, MSK Connect에서 connector의 일시중단 및 재시작 기능이 제공되지 않아 운영상의 제약이 있었습니다. 이러한 이유로 특정 시나리오에서 리소스를 삭제 후 재구성해야 했기 때문에 1시간 이상 소요되는 상황이 발생하였습니다.
이를 해결하기 위해 리멤버는 Amazon ECS 환경 위에 Kafka Connect를 직접 배포하는 방식으로 전환했으며 ECS 전환 후 장점은 다음과 같습니다.
- Rolling Update를 통해 리소스 증설이 편리
- 중단이 가능하여 신규 테이블 추가가 편리
- PySpark 기반 병렬 처리로 수억건 데이터도 분 단위 처리 가능
변경된 워크플로우는 다음의 절차대로 수행됩니다.
- Source Connector에 테이블 추가
- PySpark를 활용한 데이터 마이그레이션
- Debezium Snapshot 모드 사용하지 않음
- 병렬 처리로 빠른 Full Load 수행
- Sink Connector에 토픽 추가
위의 방식대로 처리할 경우 신규 테이블의 Bin Log가 먼저 토픽에 적재되고 이후 PySpark로 Full Load를 수행하게 되면서 일부 변경 사항을 재처리하게 됩니다. Sink Connector에서는 PK 기준 Upsert로 처리하기 때문에 데이터의 정합성은 보장됩니다.
Debezium Source Connector 설정
리멤버에서는 MySQL Binlog 기반 CDC를 위해 Debezium MySQL Connector를 사용하고 있습니다. 아래는 실제 운영에서 사용 중인 주요 설정입니다.
몇 가지 중요한 속성을 먼저 설명드리겠습니다.
1. snapshot.mode = no_data
CDC 시작 전 별도의 Snapshot DB를 통해 데이터 마이그레이션을 이미 완료한 상태였습니다. Connector가 처음 시작될 때 데이터를 새로 캡쳐할 필요가 없기 때문에 Binlog Position부터 동기화를 진행합니다. 이 경우 no_data 모드로 설정하면 스냅샷 과정 없이 Binlog만 읽어오기 때문에 불필요한 부하를 줄일 수 있습니다.
2. snapshot.locking.mode=none
Debezium은 기본적으로 스냅샷 캡쳐 시점의 정합성을 보장하기 위해 Global Read Lock을 걸게됩니다. snapshot.mode=no_data에서는 실제 데이터를 캡쳐하지 않기 때문에 Lock이 불필요합니다. 따라서 none으로 설정하여 Global Lock 발생을 방지했습니다.
3. time.precision.mode = connect
이 속성의 기본값은 adaptive_time_microseconds입니다. 이 설정에서는 Debezium을 통해 MySQL 등의 데이터를 Kafka로 전송할 때, 날짜/시간 타입이 Debezium Semantic type(io.debezium.time.Timestamp) 으로 변환됩니다.
하지만 Iceberg Kafka Connector에서는 Debezium Semantic type을 인식하지 못하기 때문에 날짜형 변환에 실패하거나 Unix Time 으로 들어가 버리는 문제가 발생합니다.
따라서, 이를 해결하기 위해 time.precision.mode=connect 로 설정해 Semantic Type Kafka Connect 표준(org.apache.kafka.connect.data.Timestamp) 으로 바꾸어 다른 시스템에서 타임스탬프로 인식할 수 있도록 날짜/시간을 변환해야합니다.
Iceberg Kafka Connector 설정
이번에는 Iceberg Kafka Connector 설정 방법과 주의할 점에 대해 설명하겠습니다.
S3 Tables는 데이터를 조회/업데이트하기 위한 REST Endpoint를 제공하며, 연결을 위해 다음 속성이 필요합니다.
- Iceberg.catalog.uri : S3 Tables REST Endpoint
- Iceberg.catalog.warehouse : S3 Tables버킷 ARN
- Iceberg.catalog.rest.sigv4-enabled : SigV4 인증 활성화 여부
- Iceberg.catalog.rest.signing-region : 리전
- Iceberg.catalog.rest.signing-name : s3tables
Amazon S3 Tables Iceberg REST 엔드포인트에 대한 요청은 S3 Tables REST API 작업에 해당하는 IAM 작업을 통해 승인되며. 자세한 내용은 S3 테이블 액세스 관리 문서 참고를 부탁드립니다.
이번에는 Iceberg 테이블 및 Control 설정입니다.
"iceberg.tables.upsert-mode-enabled": "true",
"iceberg.tables.dynamic-enabled": "true",
"iceberg.tables.auto-create-enabled": "false",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.control.commit.timeout-ms": "180000",
"iceberg.control.commit.interval-ms": "600000",
"iceberg.control.topic": "cdc.s3tables.control_v9",
"topics": "Topic1, Topic2",- upsert-mode-enabled : Upsert 모드 사용 여부
- dynamic-enabled : routeField 값 기준으로 테이블 라우팅
- auto-create-enabled : 테이블이 없을 경우 자동 생성
- evolve-schema-enabled : 스키마 변경 사항을 자동 반영
- Control.commit.timeout-ms : Commit 타임아웃
- Control.commit.interval-ms : Commit 주기
- Control.topic : Commit 조정을 위한 내부 토픽
auto-create-enabled 설정 시 테이블이 존재하지 않을 경우 자동으로 생성합니다. 운영 환경에서는 예상치 못한 스키마가 생성될 수 있기 때문에 false 로 사용하시는 것을 권장드립니다.
evolve-schema-enabled 는 소스 DB에 새로운 컬럼이 추가되면 자동으로 S3 Tables 에도 반영이 됩니다. 다만, 컬럼 삭제나 타입 변경은 예상치 못한 호환성 문제를 일으킬 수 있어 운영에서는 변경 후 모니터링이 필요합니다.
마지막 중요한 설정은 commit.interval-ms 속성입니다. 이 속성은 Iceberg Connector에서 S3 Tables에 데이터를 갱신하는 주기입니다.
주기에 설정에 따라 다음과 같은 문제들이 생길 수 있습니다:
- 너무 짧으면 스냅샷과 Small 파일이 과도하게 증가
- 너무 길면 데이터 반영 지연 발생
Iceberg 는 Commit 발생 시 1개의 Snapshot과 다수의 Data File이 생성됩니다. 리멤버에서는 초기에 1분(60000ms)으로 설정했지만, 트랜잭션이 많은 워크로드에서는 지속적으로 Compaction이 실패하는 현상이 발생했습니다. 현재는 실시간 분석 목표와 성능을 고려하여 10분(600000ms)으로 설정하여 운영하고 있습니다.
CDC 관련 설정
S3 Tables와 Iceberg Kafka Connector가 혼합된 환경에서 Debezium 기반 CDC 이벤트를 반영하기 위해서는 별도의 Transformer 설정이 필요합니다. 리멤버에서는 Debezium Transform을 활용하여 CDC 이벤트를 Iceberg 테이블에 적재하고 있습니다.
아래는 설정 예시입니다.
"transforms": "dbztransform",
"transforms.dbztransform.type": "io.tabular.iceberg.connect.transforms.DebeziumTransform",
"iceberg.tables.cdc-field": "_cdc.op",
"iceberg.tables.route-field": "_cdc.target",
"transforms.dbztransform.cdc.target.pattern": "{db}.{table}",
"iceberg.tables.default-id-columns": "id"- transforms : CDC 변환기 지정
- cdc-field : CDC 이벤트 타입 필드
- route-field : 대상 테이블 메타데이터(_cdc.target)
- cdc.target.pattern : CDC 적용 대상 테이블 패턴
- default-id-columns : Upsert 모드에서 사용되는 Merge 기준 컬럼(Primary Key)
default-id-columns 는 반드시 소스 DB의 PK와 일치해야 합니다. PK가 누락되면 Delete 이벤트가 정상적으로 반영되지 않거나 Upsert가 중복 기록으로 이어질 수 있으니 주의해야합니다.
여기서 default-id-columns 을 제외한 속성들은 반드시 위의 값을 설정해야만 CDC가 가능합니다. 그 이유는 Debezium Source의 메시지 포맷과 Iceberg Kafka Connect의 DebeziumTransform.java 코드에서 살펴보겠습니다.
Debezium Source에서는 아래의 포맷으로 CDC 데이터가 들어오게 됩니다.
- Op : I(Insert), U(Update), D(Delete)
- Source : db, table 등 메타데이터
- Before, after : 변경 전후 데이터
DebeziumTransform.java
#
...
...
private static final String CDC_TARGET_PATTERN = "cdc.target.pattern";
private static final String DB_PLACEHOLDER = "{db}";
private static final String TABLE_PLACEHOLDER = "{table}";
...
...
private R applySchemaless(R record) {
Map<String, Object> value = Requirements.requireMap(record.value(), "Debezium transform");
String op = mapOperation(value.get("op").toString());
Object payload;
if (op.equals(CdcConstants.OP_DELETE)) {
payload = value.get("before");
} else {
payload = value.get("after");
}
if (!(payload instanceof Map)) {
LOG.debug("Unable to transform Debezium record, payload is not a map, skipping");
return null;
}DebeziumTransform 에서 payload는 Operation에 따라 before 또는 after의 값을 가져오게 됩니다.
즉, Debezium 이벤트의 구조를 그대로 사용하기 때문에 위에서 정의한 속성값을 그대로 설정해야하며 Debezium SMT(Single Message Transform) 를 적용할 경우 before/after 구조가 깨질 수 있어 CDC 반영이 되지 않으므로 주의해야 합니다.
아래는 CDC 환경을 위한 Iceberg Kafka Connector 최종 설정 예시입니다.
{
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"tasks.max": "1",
"iceberg.catalog.type": "rest",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"iceberg.catalog.uri": "https://s3tables.ap-northeast-2.amazonaws.com/iceberg",
"iceberg.catalog.warehouse": "{s3table bucket ARN}",
"iceberg.catalog.client.region": "ap-northeast-2",
"iceberg.catalog.rest.sigv4-enabled": "true",
"iceberg.catalog.rest.signing-region": "ap-northeast-2",
"iceberg.catalog.rest.signing-name": "s3tables",
# 테이블 설정
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.tables.upsert-mode-enabled": "true",
"iceberg.tables.dynamic-enabled": "true",
"iceberg.tables.auto-create-enabled": "true",
"errors.log.enable": "true",
"iceberg.control.commit.timeout-ms": "60000",
"iceberg.control.commit.interval-ms": "600000",
"iceberg.control.topic": "cdc.s3tables.control_v1",
"topics": "Topic1, Topic2",
# CDC 설정
"transforms": "dbztransform",
"transforms.dbztransform.type": "io.tabular.iceberg.connect.transforms.DebeziumTransform",
"iceberg.tables.cdc-field": "_cdc.op",
"iceberg.tables.route-field": "_cdc.target"
"transforms.dbztransform.cdc.target.pattern": "{db}.{table}",
"iceberg.tables.default-id-columns": "id",
}
Iceberg Kafka Connect 구성이 완료되면 3개의 Consumer Group이 생성됩니다.
- Connect-{connector}
- Kafka Connect Sink Worker가 데이터를 수집·적재하기 위해 사용하는 기본 Consumer Group
- Cg-control-{connector}
- Commit 및 상태 관련 이벤트를 수집하는 제어용 Consumer Group
- Cg-control-{connector}-coord
- Snapshot / Offset Commit 순서를 조율하는 Coordinator 전용 Consumer Group
Amazon Athena 조회
구축된 S3 Tables는 Amazon Athena를 통해 바로 조회할 수 있습니다. 이때 카탈로그는 아래와 같이 생성됩니다.
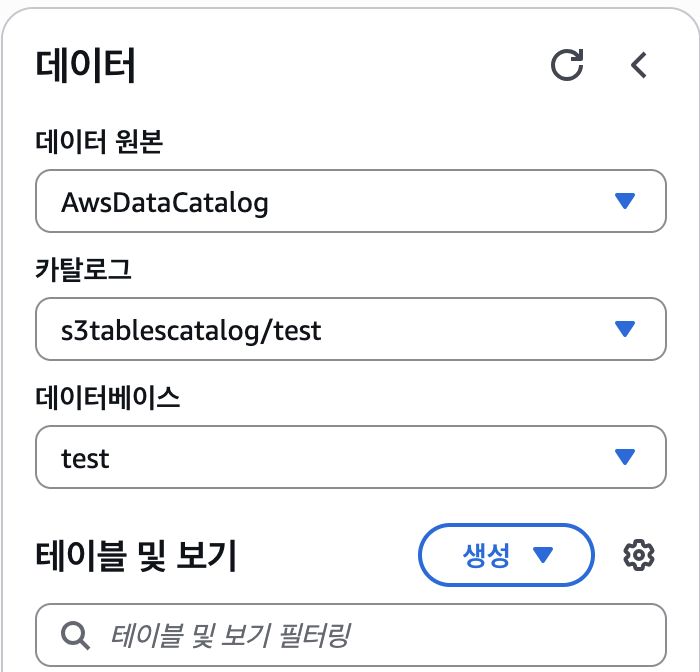
S3 Tables에 생성된 Iceberg 테이블은 기존 Glue Catalog에 등록된 Iceberg 테이블과는 완전히 분리된 s3tablecatalog라는 별도의 카탈로그에서 관리됩니다. 따라서 이름이나 경로가 겹치더라도 충돌 없이 운영할 수 있으며, Glue Iceberg와 독립적으로 동작하기 때문에 기존 운영 환경에 영향을 주지 않고 안정적으로 테이블을 조회하고 관리할 수 있습니다.
마무리
이렇게 1부는 Aurora MySQL에 있던 기존 데이터를 Amazon S3 Tables로 마이그레이션 하고 Kafka Connect를 구성하는 방법에 대해 다뤘습니다. 2부에서는 실제 운영 시 주의해야 할 사항과 함께, Compaction 전략, Snapshot 관리, 모니터링 전략, 그리고 분석 엔진 선택에 대해 정리해 보겠습니다.