AWS 기술 블로그
Amazon EKS에서 Slinky를 사용하여 Slurm 배포하기
이 글은 Containers 블로그에 게시된 글 (Running Slurm on Amazon EKS with Slinky)을 한국어로 번역 및 편집하였습니다.
사전 학습(pre-training), 파인튜닝(fine-tuning) 또는 추론(inference) 워크로드를 위한 AI 인프라 스택을 구축할 때, 흔히 Slurm이나 Kubernetes를 컴퓨팅 오케스트레이션 플랫폼으로 활용합니다. 각 플랫폼은 다양한 팀의 요구사항을 충족하고 AI 개발 과정의 여러 단계를 지원할 수 있습니다. 하지만 전통적으로 이 방식은 가속 컴퓨팅 용량을 위한 별도의 클러스터를 각각 관리해야 했기 때문에, 운영 오버헤드가 중복되고 리소스 활용률이 저하되는 문제가 있습니다. 만약 Slurm 클러스터를 Kubernetes 서비스로 배포할 수 있다면, 두 플랫폼의 장점을 동시에 취할 수 있을 것입니다.
Kubernetes를 테넌트에게 전력, 인터넷, 보안, 냉난방 같은 공유 리소스를 제공하는 대형 오피스 빌딩이라고 가정해보겠습니다. 특수 전력이나 정밀한 온도 제어가 필요한 전문 연구실이 입주한다고 해서 새 건물을 짓지는 않습니다. 대신 기존 빌딩 인프라에 연구실을 통합해서 공유 서비스는 그대로 활용하면서, 고성능 작업에 필요한 세밀한 제어는 독립적으로 유지하는 방식을 택합니다. 이와 마찬가지로 Slurm은 오픈 소스 Slinky Project를 통해 Amazon Elastic Kubernetes Service (Amazon EKS)와 같은 Kubernetes 환경 내에서 실행될 수 있습니다.
이 게시물에서는 Slinky 프로젝트를 소개하고 주요 이점을 살펴봅니다. Slinky Slurm operator를 사용하는 Slurm on EKS blueprint를 배포과정에 대해 알아보고 몇 가지 대안도 함께 확인해 보겠습니다.
Slurm 기초
Slurm은 다양한 규모의 컴퓨팅 클러스터에서 리소스를 관리하도록 설계된 오픈 소스 워크로드 매니저이자 작업(job) 스케줄러로, 뛰어난 확장성을 갖추고 있습니다. Slurm은 세 가지 핵심 기능을 제공합니다. 첫째, 컴퓨팅 리소스에 대한 접근 권한을 할당합니다. 둘째, 병렬 컴퓨팅 작업을 실행하고 모니터링하기 위한 프레임워크를 제공합니다. 셋째, 리소스 경합 해소를 위한 작업 큐를 관리합니다.
Slurm은 전통적인 고성능 컴퓨팅(HPC) 환경과 AI 학습 과정에서 다중 노드 클러스터 전반에 걸친 대규모 가속 컴퓨팅 워크로드를 관리하고 스케줄링하는 데 널리 사용됩니다. 연구자와 엔지니어 모두 Slurm을 통해 리소스 유형과 작업 우선순위를 세밀하게 제어하면서 분산 훈련 작업에 필요한 CPU, GPU, 메모리 리소스를 효율적으로 할당할 수 있습니다. Slurm은 안정성, 고급 스케줄링 기능, 온프레미스 및 클라우드 환경과의 통합 지원을 바탕으로 현대 AI 연구와 산업에 요구되는 규모(scale), 처리량(throughput), 재현성(reproducibility)을 충족하는 데 적합한 솔루션으로 자리 잡았습니다.
Slinky Project
Slinky Project는 Slurm의 핵심 개발사인 SchedMD가 설계한 오픈 소스 통합 도구 모음입니다. Slurm 기능을 Kubernetes에 도입하여 효율적인 리소스 관리와 스케줄링을 위해 두 플랫폼의 장점을 결합합니다. Slinky Project에는 Slurm 클러스터용 Kubernetes operator가 포함되어 있으며, 이는 custom-controllers와 custom resource definitions (CRDs)를 구현하여 Kubernetes 환경 내에 배포된 Slurm Cluster 및 NodeSet 리소스의 수명 주기를 관리합니다.
Slinky의 용례
Slinky 프로젝트는 장시간 실행되는 리소스 집약적 배치 작업과 빠르게 확장되는 서비스 지향 워크로드를 모두 관리해야 하는 조직을 위해 설계되었습니다. 결정론적 (deterministic) 스케줄링과 세밀한 리소스 제어가 강점인 Slurm과, 동적 리소스 할당 및 신속한 확장이 가능한 Kubernetes를 결합하여 이를 구현합니다. 예를 들어, 유전체 시퀀싱이나 기후 모델링을 수행하는 연구 기관에서는 Slurm의 안정적인 배치 작업 관리 기능을 활용하여 수 시간에 걸친 복잡한 시뮬레이션을 실행할 수 있습니다. 동시에 Kubernetes의 신속한 오토스케일링 기능을 활용하는 반응형 API나 마이크로서비스도 호스팅할 수 있습니다. 이와 같은 컴퓨팅 리소스 사용 최적화와 운영 오버헤드 절감은 비용 관리의 핵심 요소입니다. Slinky를 활용하면 클라우드 인프라를 Kubernetes로 표준화하여 운영 효율성을 높이면서도 연구 팀에 필요한 Slurm 기능을 그대로 유지할 수 있습니다. 즉, 보유한 리소스의 가용성을 최대화하는 통합 컴퓨팅 환경을 구성할 수 있습니다.
EKS에 배포된 Slinky Slurm 아키텍처 개요
다음 다이어그램은 Slinky를 Amazon EKS에 배포하는 방식을 보여줍니다. 중앙 관리 데몬인 slurmctld와 기타 핵심 구성 요소(다이어그램에는 생략됨)는 범용 노드에 배포되고, Slurm의 컴퓨팅 노드 데몬인 slurmd는 가속 노드에 배포됩니다. 고성능 공유 스토리지를 위해 Amazon FSx for Lustre 파일 시스템이 slurmd 파드에 마운트되며, AWS Network Load Balancer가 로그인 파드로 트래픽을 라우팅하도록 구성됩니다. 이 아키텍처는 Slurm on EKS blueprint를 사용하여 배포하고 테스트할 수 있습니다.
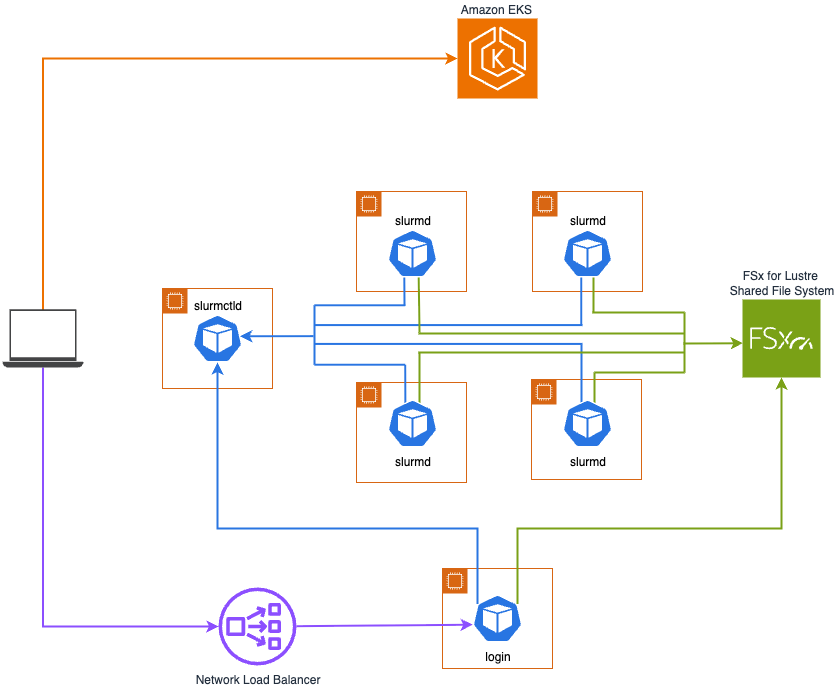
Slinky Slurm 클러스터 구성 요소
컨테이너화된 Slinky Slurm 클러스터는 일반적인 Slurm 클러스터와 기능적으로 유사한 구성 요소를 사용합니다.
컨트롤러 파드(헤드 노드)는 slurmctld 중앙 관리 데몬을 실행합니다. 이 데몬은 리소스를 모니터링하고, 작업을 수락하며, 컴퓨팅 노드에 작업을 할당합니다.
어카운팅 파드는 slurmdbd 데몬을 실행합니다. 이 데몬은 백엔드 MariaDB 데이터베이스와 연동하여 작업 사용량 및 리소스 할당 정보 등의 어카운팅 기록을 아카이빙하고 관리합니다. 기본적으로 백엔드 MariaDB 데이터베이스는 Slurm 클러스터 Kubernetes 배포의 일부로 호스팅되지만, Amazon Relational Database Service (Amazon RDS) for MariaDB와 같은 서비스를 사용하여 외부 호스팅으로 구성할 수도 있습니다.
REST API 파드는 slurmrestd 데몬을 실행하여 Slurm 클러스터에 대한 HTTP 기반 API 접근을 제공하며, 이를 통해 프로그래밍 방식의 상호 작용이 가능합니다. REST API는 NodeSet 컨트롤러가 워커 노드 파드의 수명 주기를 관리하는 데 사용되며, Slurm 클러스터의 메트릭 익스포터가 모니터링 및 옵저버빌리티를 위한 텔레메트리 데이터를 수집하는 데도 활용됩니다.
워커 노드 파드는 slurmd 데몬을 실행하여 현재 실행 중인 모든 작업을 모니터링하고, 새로 들어오는 작업을 시작하기 위해 수락하거나 요청에 따라 실행 중인 작업을 종료합니다. 워커 노드 파드는 사용자가 지정한 nodeSelector 및 resource quota 사양에 따라 가속화된 컴퓨팅 EC2 인스턴스에서만 실행됩니다. 파드는 특정 하드웨어 리소스 및 스케줄링 제약 조건에 매핑하기 위해 다양한 파티션으로 그룹화할 수도 있습니다. 이를 통해 유사한 요구 사항을 가진 작업을 클러스터 내에서 효율적으로 관리하고 우선순위를 지정할 수 있습니다. Slurm operator는 compute pod에서 현재 실행 중인 워크로드를 고려하여 drain으로 표시하므로 기존 작업이 완료된 후 scale-in 또는 업그레이드 작업을 위해 종료할 수 있습니다. Slurm operator는 scale to zero 작업을 지원하는 모든 horizontal pod autoscaler(HPA)를 사용하여 compute pod를 0개 복제본으로 축소하는 것을 지원합니다.
로그인 파드는 사용자가 Slurm 클러스터와 상호 작용할 수 있는 작업 공간을 제공합니다. 사용자는 로그인 파드에서 데이터를 스테이징하고 작업 제출을 준비한 후 sbatch, srun, salloc과 같은 일반적인 Slurm 명령을 사용하여 준비가 되었을 때 작업을 제출할 수 있습니다. 로그인 파드는 sackd 데몬을 통한 인증을 지원합니다. Slurm의 내부 인증은 Slurm Auth and Cred Kiosk (SACK)라고 불리는 서브시스템을 기반으로 하며, slurmctld, slurmdbd, slurmd 데몬이 이를 내부적으로 처리합니다. sackd 데몬은 이러한 Slurm 데몬이 실행되지 않는 로그인 노드를 위해 특별히 설계되어, 해당 노드가 클러스터의 나머지 구성 요소와 인증하고 Slurm 클라이언트 명령을 실행할 수 있도록 합니다. SSH 접근의 경우, 로그인 파드에는 수신되는 SSH 클라이언트 연결을 수신 대기하고 처리하는 OpenSSH 서버 프로세스인 sshd가 포함됩니다. 또한, 로그인 파드 접근은 system security services daemon (sssd)로도 구성할 수 있습니다. 이 경우, sssd가 LDAP(Lightweight Directory Access Protocol)과 같은 프로토콜을 사용하여 AWS Directory Service 등의 원격 디렉터리 서비스에 대한 접근을 관리합니다.
Slurm 클러스터 메트릭 익스포터는 REST API에서 작업, 노드 및 파티션에 대한 Slurm 텔레메트리 데이터를 수집한 후, Amazon Managed Service for Prometheus 및 Amazon Managed Grafana와 같은 도구를 사용한 모니터링 및 옵저버빌리티를 위해 Prometheus 메트릭 포맷으로 내보냅니다. 나아가, 내보낸 메트릭을 활용하여 KEDA와 같은 HPA를 구성함으로써 파티션의 대기 중인 작업 수와 같은 사용자 지정 메트릭을 기반으로 워커 노드 파드를 스케일링하는 구성도 가능합니다.
Slinky Slurm의 이점
Slinky는 Slurm과 Kubernetes 애플리케이션이 동일한 인프라에서 실행될 수 있도록 하여 하이브리드 워크로드 관리를 간소화합니다. 이 통합 접근 방식은 실시간 워크로드와 배치 워크로드를 함께 처리하는 조직에 적합합니다. 예를 들어 AI 학습과 추론을 함께 실행하거나, 과학 시뮬레이션 및 데이터 집약적 분석을 클라우드 네이티브 애플리케이션과 병행하는 경우가 이에 해당합니다. 일반적으로 운영 경험 수준이나 선호하는 도구가 서로 다른 여러 팀이 이러한 워크로드를 관리하는 경우가 많습니다. Slinky를 사용하면 Slurm과 Kubernetes 워크로드가 동일한 노드들을 공유하므로 리소스 활용률을 극대화할 수 있습니다. 조직은 워크로드 유형별로 별도의 인프라를 구축할 필요 없이, 각 팀이 익숙한 환경에서 계속 작업할 수 있는 유연성을 확보할 수 있습니다.
다음으로, Slurm Operator는 동적 오토스케일링을 통해 워크로드 수요에 따라 워커 노드 파드를 자동으로 프로비저닝하거나 종료할 수 있습니다. Slinky는 Slurm 작업 큐를 모니터링하고 실시간으로 대응하여, 수요가 급증하면 워커 노드 파드를 추가하고 작업이 완료되거나 큐가 비워지면 스케일 다운합니다. 이를 통해 조직은 클라우드 컴퓨팅 리소스 사용 방식을 동적으로 조정할 수 있습니다. 예를 들어, 업무 시간에 더 많은 컴퓨팅 리소스를 사용하는 Kubernetes 기반 AI 추론 워크로드는 트래픽 증가에 따라 스케일 아웃할 수 있습니다. 동시에 Slurm 기반 훈련 작업은 별도의 재구성 없이 작업 큐를 기반으로 업무 시간 외에 스케일 아웃할 수 있습니다. Karpenter 또는 Cluster Autoscaler와 함께 사용하면 온디맨드 EC2 컴퓨팅의 비용 효율성을 더욱 높일 수 있습니다. 또한, 예약 ID(reservation ID)를 Karpenter 노드 클래스의 capacityReservationSelectorTerms 또는 관리형 노드 그룹(managed node group)의 시작 템플릿(launch template)에 지정하여 On-Demand Capacity Reservations (ODCRs) 또는 Capacity Blocks for ML을 사용할 수 있습니다.
마지막으로, Slurm은 구성 요소들의 컨테이너 이미지를 통해 일관성을 확보합니다. 이를 통해 애플리케이션과 종속성이 개발, 스테이징, 프로덕션 환경에서 동일하게 동작하며, 반복 가능하고 신뢰할 수 있는 배포가 가능합니다. Slinky는 사용자 정의 Slurm 컨테이너 이미지도 지원하여 유연성과 커스터마이징을 제공합니다. 커스텀 컨테이너 이미지를 사용하면 특수 라이브러리, 종속성, 구성을 환경에 내장할 수 있습니다. 예를 들어, AWS Deep Learning Containers를 slurmd 데몬과 결합하여 특정 버전의 NCCL, CUDA, PyTorch가 사전 설치된 워커 노드 파드를 생성할 수 있습니다. 이를 통해 팀은 수동으로 프로비저닝한 Python이나 Conda 가상 환경에 의존하지 않고도 종속성들을 세밀하게 제어할 수 있습니다.
AWS에서 Slurm을 실행하는 다른 방법들
Slurm을 표준으로 채택한 조직은 AWS에서 HPC 또는 AI 학습 환경을 구축하기 위해 Slinky 이외에도 다양한 옵션을 선택할 수 있습니다. 각 옵션은 서비스 관리 수준, 확장성, 주요 사용 사례에 대한 특화 정도에 따라 차이가 있습니다.
AWS ParallelCluster
이미 검증된 HPC 참조 아키텍처를 기반으로 클라우드 인프라를 자유롭게 맞춤 구성해야 하는 팀에게는 AWS ParallelCluster가 적합합니다. AWS ParallelCluster는 자체 관리형(self-managed) Slurm 클러스터 설정을 자동화하는 AWS 지원 오픈 소스 솔루션입니다. Python 패키지로 배포되는 명령줄 인터페이스, 그리고 콘솔과 같은 경험을 제공하는 자체 호스팅 웹 기반 사용자 인터페이스를 제공합니다. 또한, AWS CloudFormation(custom resource 사용) 및 Terraform과 통합되어 Infrastructure as Code (IaC) 방식 관리가 가능합니다. AWS ParallelCluster는 Slurm 클러스터의 운영 체제, 커스텀 소프트웨어, 스케줄러 구성을 직접 지정할 수 있어 높은 수준의 제어와 자체 커스터마이징이 가능합니다.
AWS Parallel Computing Service
HPC 워크로드를 위해 보다 완전한 관리형 Slurm 환경을 원하는 팀에게는 AWS Parallel Computing Service (AWS PCS)가 적합합니다. AWS PCS는 Slurm 컨트롤러 패치 자동 업데이트, 관리형 Slurm 어카운팅, 그리고 Slurm 파티셔닝을 위한 큐 기능을 제공하여 클러스터 운영을 간소화하고 유지보수 및 관리 부담을 줄여줍니다. AWS PCS는 AWS Management Console, AWS SDK, 그리고 AWS Command Line Interface (AWS CLI)를 통해 직접 액세스할 수 있습니다. AWS PCS 클러스터의 수명 주기는 AWS 퍼스트 파티(first-party) PCS CloudFormation resource type 또는 AWS PCS Terraform AWS Cloud Control provider를 사용하여 IaC로도 관리할 수 있습니다. 즉, AWS PCS는 Slurm 컨트롤러, 어카운팅, 파티셔닝 기능을 관리형 서비스로 제공합니다.
Amazon SageMaker HyperPod
파운데이션 모델(FM)을 최대한 빠르고 효과적으로 학습해야 하는 팀의 경우, Amazon SageMaker HyperPod가 적합합니다. SageMaker HyperPod는 대규모 분산 머신러닝(ML) 워크로드를 자동화와 최적화를 위해 특별 설계되었습니다. AWS ParallelCluster나 AWS PCS와 달리, HyperPod는 영구적(persistent)이고 자가 복구(self-healing)가 가능한 클러스터를 제공합니다. 클러스터 상태 확인, 자동 노드 교체, 작업 자동 재개, 멀티 헤드 노드 지원과 같은 고급 복원력 기능을 갖추고 있어 장시간 훈련 중에도 다운타임을 최소화합니다. SageMaker HyperPod는 AWS Trainium 가속기 및 NVIDIA GPU와의 긴밀한 통합을 위한 필수 패키지가 사전 설치된 AWS Deep Learning Amazon Machine Images (DLAMIs)를 사용합니다. 사용자는 SageMaker HyperPod와 함께 Slurm 오케스트레이션을 활용하여 익숙한 작업 스케줄링과 유연한 파티셔닝을 활용할 수 있습니다. 또한 환경 커스터마이징, 특수 ML 프레임워크 설치, Amazon Managed Service for Prometheus 및 Amazon Managed Grafana를 통한 고급 모니터링 도구 활용도 가능합니다.
다른 Kubernetes 네이티브 작업 스케줄러들
Amazon EKS 위에서 Kubernetes 네이티브 작업 스케줄러로 HPC 또는 AI 훈련 워크로드를 관리하려는 조직은 Slinky 이외에도 다양한 오픈 소스 도구를 활용할 수 있습니다. 이 섹션에서는 몇 가지 주요 옵션을 살펴봅니다.
Volcano
Volcano는 컴퓨팅 집약적 워크로드를 위해 특별히 설계된 강력한 배치 스케줄러로, 대규모 분산 HPC, 빅 데이터, AI 학습 작업을 실행하는 팀에 적합합니다. Volcano는 플러그인을 통해 kube-scheduler와 통합되어 노드 필터링 및 스코어링 기능을 강화합니다. 리소스 집약적인 멀티노드 학습 작업을 위해 갱 스케줄링, 네트워크 토폴로지 인식, 동적 GPU 파티셔닝 등 고급 스케줄링 정책도 지원합니다. 이를 통해 학습 작업들은 필요한 모든 리소스를 사전에 확보받을 수 있고, 병렬 처리와 GPU 활용률을 극대화할 수 있습니다. 또한 워크로드 코로케이션과 동적 오버서브스크립션을 지원하여 온라인 워크로드의 서비스 품질을 유지하면서도 높은 리소스 활용률을 보장합니다. 이러한 기능은 최적의 처리량과 세밀한 리소스 관리가 필요하고, 정교한 스케줄링 전략을 워크플로에 통합하는 데 익숙한 연구 조직이나 프로덕션 AI 팀에 유용합니다.
Apache YuniKorn
Apache YuniKorn은 멀티 테넌시, 계층적 리소스 공유, 공정성을 핵심 차별화 요소로 설계되어 여러 팀이 공유하는 Kubernetes 클러스터를 운영하는 조직에 적합합니다. YuniKorn은 기본 kube-scheduler를 독립적인 커스텀 스케줄러로 대체하고 앱 인식(app-aware) 스케줄링이라는 방식을 도입합니다. 이를 통해, 스케줄링 결정 시 사용자, 애플리케이션, 큐를 인식하여 리소스 쿼터(quota)에 대한 세밀한 제어와 큐 간 작업 우선순위 지정이 가능합니다. YuniKorn의 선점(Preemption) 기능은 우선순위가 높은 중요 AI 워크로드가 낮은 우선순위 작업에 밀려 지연되는 것을 방지합니다. 또한, 리소스 공정성 및 계층적 쿼터 관리 기능은 여러 ML 팀이 리소스를 경쟁적으로 사용하는 기업 또는 연구 환경에서 특히 유용합니다. 이때, 각 팀은 수동 개입이나 병목 현상 없이 클러스터 리소스에 대한 접근을 보장받을 수 있습니다.
Kueue
Kueue는 명확성(clarity)과 점진적 도입(incremental adoption)에 중점을 둔 Kubernetes 네이티브 작업 큐잉 및 오케스트레이션 솔루션입니다. Kueue는 기본 kube-scheduler를 대체하지 않고 보완하는 방식으로, 작업 큐잉 및 일시 중단, 리소스 쿼터 평가, 우선순위 할당 등 작업 수준의 관리를 담당합니다. 사용자는 익숙한 Kubernetes의 근간 기술을 그대로 사용하면서도, 결정론적 스케줄링, 자동화된 공정 작업 승인, 효율적인 GPU 공유와 같은 이점을 누릴 수 있습니다. Kueue의 접근 방식은 기존 스케줄러 호환성과의 통합 용이성을 우선시하면서도, 확장 가능한 AI 학습 워크로드를 위한 고급 작업 큐잉과 공정한 리소스 할당이 필요한 조직에 적합합니다. 플랫폼 엔지니어링 팀, 스타트업을 비롯해 최소한의 변경으로 클라우드 네이티브 솔루션을 도입하려는 조직이 이에 해당합니다.
EKS에서 Slurm 사용이 적합한 경우
AWS는 클라우드에서 Slurm 클러스터를 배포하기 위한 다양한 옵션을 제공하고 있으며, 오픈 소스 Kubernetes 커뮤니티에서도 작업 스케줄링 Operator가 계속 발전하고 있습니다. 그중에서도 Slinky 프로젝트는 실시간 워크로드와 배치 워크로드를 모두 관리해야 하는 조직을 위해 특별히 설계되었습니다. 결정론적 스케줄링과 세밀한 리소스 제어가 강점인 Slurm과, 동적 리소스 할당 및 신속한 확장이 가능한 Kubernetes를 결합하여 이를 구현합니다.
챗봇이나 가상 어시스턴트와 같은 워크로드는 수요 변동이 크고, 작업 수명이 짧으며, 고가용성과 빠른 확장이 필요하다는 특징이 있습니다. 이러한 환경에서는 클라우드 네이티브 환경에서 서비스와 API를 위한 동적 리소스 할당, 신속한 확장성, 고가용성을 제공하는 Kubernetes가 강점을 발휘합니다. 반면 HPC 및 AI 훈련 작업은 실행 시간이 길고 리소스 소비가 높으며 컴퓨팅 요구사항이 비교적 예측 가능합니다. 이러한 워크로드는 정적 클러스터에 배포된 Slurm의 결정론적 스케줄링과 세밀한 리소스 제어가 더 적합합니다.
Slinky를 활용하면 Kubernetes에서 Slurm을 실행하여 통합된 클라우드 네이티브 인프라로 이기종 워크로드를 효율적으로 오케스트레이션할 수 있습니다. 이 접근 방식을 통해 별도의 사일로 형태로 클러스터를 유지할 필요가 없고 동적 리소스 공유가 가능해져, 전반적인 리소스 활용도가 향상되고 가변적인 컴퓨팅 요구사항에 대한 탄력성도 좋습니다. Slinky는 팀이 Slurm이나 Kubernetes와 상호작용하는 방식을 변경하도록 강요하지 않습니다. 사용자는 기존 Slurm 스크립트와 명령을 그대로 유지하면서, 클라우드 네이티브 환경에 익숙한 실무자들은 컨테이너 오케스트레이션 도구로 새로운 워크로드를 실행할 수 있습니다.
지금 바로 새로운 Slurm on EKS blueprint로 Slinky를 시작해 보세요.