AWS 기술 블로그
AWS Advanced JDBC Wrapper를 사용하여 표준 JDBC 드라이버로 Amazon Aurora의 고급 기능 활용하기
이 글은 AWS Database Blog에 게시된 Unlock Amazon Aurora’s Advanced Features with Standard JDBC Driver using AWS Advanced JDBC Wrapper by Dave Cramer, Chirag Dave, Ramesh Eega을 한국어 번역 및 편집하였습니다.
Amazon Aurora를 사용하는 최신 Java 애플리케이션은 클라우드 기반 기능을 최대한 활용하는 데 어려움을 겪는 경우가 많습니다. Aurora는 빠른 장애 조치, AWS Identity and Access Management(IAM) 인증 지원, AWS Secrets Manager 통합과 같은 강력한 기능을 제공하지만, 표준 JDBC 드라이버는 클라우드 특화 기능을 고려하여 설계되지 않았습니다. 이는 오픈소스 드라이버의 한계가 아닙니다. 오픈소스 드라이버는 설계 목적에 맞게 클라우드 기반 최적화보다는 데이터베이스 표준에 초점을 맞추고 있습니다.
Aurora는 장애 조치가 몇 초 만에 완료되지만, 표준 JDBC 드라이버는 DNS 전파 지연으로 인해 재연결하는 데 최대 1분이 소요될 수 있습니다. Aurora는 IAM 인증과 Secrets Manager 통합과 같은 강력한 기능을 지원하지만, 표준 JDBC 드라이버로 이러한 기능을 구현하려면 복잡한 사용자 지정 코드와 오류 처리가 필요합니다. Advanced JDBC Wrapper는 이러한 복잡성을 없애줍니다.
이 블로그 게시물은 Java 개발자들에게 오픈 소스 표준 JDBC 드라이버와 HikariCP 연결 풀러를 사용하는 기존 애플리케이션에 AWS Advanced JDBC Wrapper(JDBC Wrapper)를 추가하여, 최소한의 코드 변경으로 Aurora와 AWS 클라우드의 기능을 활용하는 방법을 보여줍니다. 이 접근 방식은 PostgreSQL 드라이버의 모든 장점을 유지하면서 클라우드 기반 기능을 추가합니다. 또한 이 게시물은 JDBC Wrapper의 강력한 기능 중 하나인 읽기/쓰기 분할을 설명합니다.
솔루션 개요
JDBC Wrapper는 Aurora와 AWS 클라우드 기능을 활용하여 기존 JDBC 드라이버를 향상시키는 지능형 Wrapper입니다. Wrapper를 사용하면 표준 PostgreSQL, MySQL, MariaDB 드라이버를 클라우드 환경에 최적화된 프로덕션 솔루션으로 전환할 수 있습니다. 개발자는 JDBC Wrapper를 도입하여 다음 기능을 활용할 수 있습니다.
- DNS 제한을 넘어서는 빠른 장애조치 — JDBC Wrapper는 Aurora에 직접 쿼리를 통해 Aurora 클러스터 토폴로지와 각 데이터베이스 인스턴스의 기본 또는 복제본 역할을 실시간으로 캐시합니다. 이를 통해 DNS 지연을 완전히 우회하여 장애조치 시 새 기본 인스턴스에 즉시 연결할 수 있습니다.
- 원활한 AWS 인증 — Aurora는 IAM 데이터베이스 인증을 지원하지만, 기존 방식에서는 토큰 생성, 만료 처리, 갱신 관리를 위한 사용자 지정 코드가 필요합니다. JDBC Wrapper는 전체 IAM 인증 수명 주기를 자동으로 처리합니다.
- 내장 Secrets Manager 지원 — Secrets Manager 통합을 통해 데이터베이스 자격 증명을 자동으로 가져옵니다. 애플리케이션은 실제 암호를 알 필요가 없으며, 드라이버가 모든 작업을 백그라운드에서 처리합니다.
- 페더레이션 인증 – Microsoft Active Directory Federation Services 또는 Okta를 통해 조직 자격 증명을 사용하여 데이터베이스 액세스를 활성화할 수 있습니다.
- 연결 제어를 사용한 읽기/쓰기 분할 — 쓰기 작업은 기본 인스턴스로 라우팅하고 읽기 작업은 Aurora 복제본에 분산하여 Aurora 성능을 극대화할 수 있습니다.
참고: 읽기/쓰기 분할 기능을 사용하려면 개발자가 읽기 작업을 위해 연결에서 setReadOnly(true) 를 명시적으로 호출해야 합니다. 드라이버는 쿼리를 분석하여 읽기 작업과 쓰기 작업을 자동으로 구분하지 않습니다. setReadOnly(true)가 호출되면 setReadOnly(false)가 호출될 때까지 해당 연결에서 실행되는 모든 후속 명령문이 복제본으로 라우팅됩니다. 이 기능은 이 게시물 뒷부분에서 자세히 설명합니다.
이 게시물에서는 JDBC Wrapper를 사용하여 실제 Java 애플리케이션을 변환시키는 과정을 살펴봅니다. 기존 Java 애플리케이션이 다음 세 단계를 거쳐 어떻게 발전하는지 확인할 수 있습니다.
- 1단계: 표준 JDBC 드라이버(기준) — 애플리케이션은 표준 JDBC 드라이버를 통해 Aurora Writer 엔드포인트에 직접 연결되며, 모든 작업은 단일 데이터베이스 인스턴스를 사용하고 DNS 기반 장애조치에 의존합니다.
- 2단계: 빠른 장애조치를 지원하는 JDBC Wrapper — 애플리케이션은 JDBC Wrapper를 사용하여 Aurora 클러스터의 내부 토폴로지 캐시를 유지하고, Writer 엔드포인트를 통해 모든 작업을 라우팅하면서 직접 인스턴스를 검색하여 빠른 장애조치를 가능하게 합니다.
- 3단계: 읽기/쓰기 분할 — 애플리케이션은 JDBC Wrapper 읽기/쓰기 분할 기능을 사용하여 쓰기 작업을 Aurora Writer 인스턴스에 보내고 읽기 작업을 Aurora Reader 인스턴스에 분산시켜 자동 로드 밸런싱을 통해 성능을 최적화합니다.
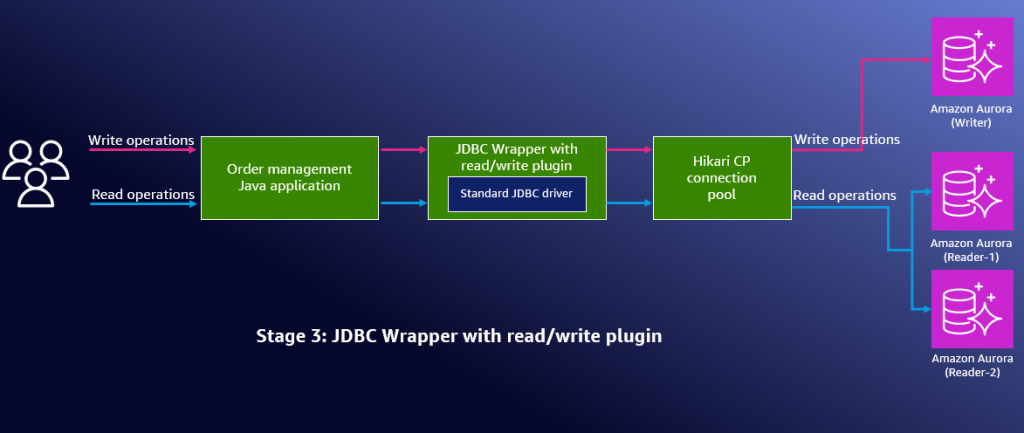
그림 1: 읽기/쓰기 분할이 활성화된 3단계 구성을 보여주는 아키텍처 다이어그램
사전 준비 사항
이 게시물의 솔루션을 구현하기 위해서는 다음과 같은 환경이 준비되어 있어야 합니다.
- Aurora 클러스터 생성 권한 있는 AWS 계정
- Aurora 클러스터에 연결 및 데모 애플리케이션 실행을 위해 다음의 소프트웨어가 설치된 Linux 기반 머신
- AWS CLI version 2(개인 자격 증명 설정 완료)
- Java Development Kit 8 이상
- Gradle 8.14 이상
인프라 설정 옵션
- 옵션 A: AWS Cloud Development Kit(AWS CDK)를 사용한 infrastructure as code(권장)
- 추가 요구 사항: Node.js 20 이상, Maven 3.6 이상
- AWS CDK v2 설치 및 구성:
- 설치: npm install -g aws-cdk(AWS CDK Getting Started Guide)
- bootstrap: cdk bootstrap (AWS CDK Developer Guide)
- IAM 권한: AWS 자격 증명에 iam-policy-cdk.json에 지정된 권한이 필요합니다
- 옵션 B: 수동 설정
- Aurora 클러스터: 읽기 전용 복제본이 하나 이상 있는 Aurora 클러스터 생성
- 보안 그룹: 리포지토리를 클론한 머신에서 5432 포트를 허용
솔루션 구현
개발 환경 설정
이 섹션에서는 샘플 리포지토리를 복제하고 표준 PostgreSQL JDBC 드라이버와 함께 HikariCP 연결 풀링을 사용하는 Java 주문 관리 애플리케이션을 살펴봅니다.
다음 코드를 사용하여 GitHub 리포지토리를 복제합니다.
데모 애플리케이션은 고객이 주문하고, 직원이 주문 상태를 업데이트하고, 관리자가 판매 보고서를 생성하는 온라인 상점의 실제 주문 관리 시스템을 시뮬레이션합니다. 이 시나리오는 혼합 데이터베이스 워크로드의 어려움을 보여줍니다. 결제 처리와 같이 쓰기 작업이 많은 작업은 즉각적인 일관성이 필요하지만, 판매 보고서 생성과 같이 읽기 복제본을 사용하는 읽기 작업이 많은 작업은 약간의 지연이 허용될 수 있습니다.
리포지토리 구조는 다음과 같습니다.

이제 데모 애플리케이션 코드를 로컬에 저장하고 HikariCP 및 표준 PostgreSQL JDBC 드라이버를 사용하는 일반적인 Java 주문 관리 시스템으로서의 구조를 이해했으므로, 다음 단계는 애플리케이션이 연결할 Aurora 데이터베이스 인프라를 구축하는 것입니다.
데이터베이스 인프라 배포
AWS CDK를 사용하는 infrastructure as code 방식의 자동화 스크립트를 통해 읽기 전용 복제본 2개를 가진 Aurora 클러스터를 생성합니다. AWS Advanced JDBC Wrapper의 읽기/쓰기 분할 기능을 시연하기 위해 두 개의 읽기 복제본이 필요합니다. 기본 인스턴스가 쓰기 작업을 처리하는 동안 읽기 작업은 별도의 Reader 인스턴스로 라우팅 됩니다. 제공된 스크립트를 사용하지 않으려면 AWS Management 콘솔을 통해 클러스터를 수동으로 생성할 수 있습니다.
.env 파일을 통한 설정 커스터마이징 (Optional)
기존 AWS 리소스 (예: 특정 VPC 또는 보안 그룹 등)를 사용하거나 리소스 이름을 사용자가 직접 지정하려는 경우 .env 파일을 생성하여 기본 설정을 재정의할 수 있습니다. 기존 AWS 인프라를 사용하지 않으려면 이 단계를 건너뛰고 기본값을 사용할 수 있습니다.
Aurora 클러스터 생성
설치 스크립트를 실행하여 Reader 인스턴스 두 개와 Writer 인스턴스가 있는 Aurora 클러스터를 생성합니다.
클러스터를 성공적으로 생성하면 다음과 같은 출력이 표시됩니다.
애플리케이션 속성 설정
애플리케이션 속성 파일에는 Java 애플리케이션이 Aurora 클러스터에 연결하는 데 사용하는 데이터베이스 연결 세부 정보가 포함되어 있습니다.
제공된 AWS CDK 스크립트(옵션 A)를 사용하여 클러스터를 생성한 경우 스크립트가 Aurora 연결 세부 정보를 사용하여 src/main/resources/application.properties 파일을 자동으로 생성하고 구성합니다. 따라서 스크립트가 이 작업을 수행했으므로 애플리케이션 속성 파일을 생성하거나 구성할 필요가 없습니다.
수동 설정(옵션 B)의 경우, 애플리케이션 속성 파일을 생성하고 구성합니다.
데이터베이스 암호 설정
제공된 AWS CDK 스크립트(옵션 A)를 사용하여 인프라를 구축한 경우: AWS CDK 스크립트가 자동으로 안전한 암호를 생성하여 Secrets Manager에 저장합니다. 다음 명령어를 사용하여 데이터베이스 암호 환경 변수를 설정합니다.
수동 설정(옵션 B)을 사용한 경우:
다음 명령을 실행하여 Aurora 클러스터를 생성 시 지정한 암호를 설정합니다.
읽기 전용 복제본이 있는 Aurora 클러스터를 성공적으로 배포하고 애플리케이션 속성과 데이터베이스 암호를 구성했으므로, 다음 단계는 AWS Advanced JDBC Wrapper의 기능을 보여주는 세 가지 단계를 통해 애플리케이션을 테스트하는 것입니다.
JDBC Wrapper를 사용하여 애플리케이션 구성
이 섹션에서는 JDBC Wrapper로 Java 애플리케이션을 구성하는 세 가지 단계를 설명합니다.
- 1단계: 표준 JDBC 드라이버(기준) — 표준 PostgreSQL JDBC 드라이버로 애플리케이션을 실행
- 2단계: 빠른 장애조치를 지원하는 JDBC Wrapper — 빠른 장애조치 기능을 지원하도록 JDBC Wrapper를 구성
- 3단계: 읽기/쓰기 분할 — 읽기/쓰기 분할을 활성화하여 Aurora 복제본에 읽기를 분산
1단계: 표준 JDBC 드라이버 (기준)
JDBC Wrapper 기능으로 향상시키기 전에 표준 PostgreSQL JDBC 드라이버를 사용하여 애플리케이션을 실행하여 기준선을 설정합니다. 표준 JDBC 동작 확인을 위하여 애플리케이션을 실행합니다.
./gradlew clean run
다음은 샘플 출력입니다.
출력에서 쓰기 작업(주문 생성)과 읽기 작업(주문 내역 조회) 모두 동일한 연결 URL 패턴을 보여줍니다. (→ WRITER jdbc:postgresql://aurora-jdbc-demo.cluster-xxxxxxxxx) 이는 모든 데이터베이스 작업이 Aurora Writer 엔드포인트로 라우팅되는 표준 JDBC 동작을 보여줍니다. 즉, 트랜잭션 작업과 분석 쿼리 모두 동일한 Writer 리소스를 놓고 경쟁합니다. 이는 다음 단계에서 AWS Advanced JDBC Wrapper의 읽기/쓰기 분할 기능으로 해결할 문제입니다.
표준 JDBC 드라이버를 사용하여 기준선을 설정하고 모든 작업이 Aurora Writer 엔드포인트로 라우팅되는 방식을 확인했으므로, 다음 단계는 동일한 기능을 유지하면서 빠른 장애조치와 같은 클라우드 기능을 추가하기 위해 JDBC Wrapper를 사용하도록 애플리케이션을 구성하는 것입니다.
2단계: 빠른 장애 조치를 지원하는 JDBC Wrapper
이제 동일한 기능을 유지하면서 빠른 장애조치와 같은 기능을 추가하기 위해 JDBC Wrapper를 사용하도록 애플리케이션을 변환합니다. 스크립트를 사용하여 표준 JDBC 애플리케이션을 Aurora 및 AWS Cloud Features로 업그레이드하는 데 필요한 변경 사항을 자동으로 적용합니다. 스크립트를 실행하기 전에 애플리케이션이 JDBC Wrapper를 사용하기 위해 어떤 변경이 필요한지 살펴봅니다.
build.gradle (JDBC Wrapper구성 전):
다음 구성은 JDBC Wrapper 기능을 사용하기 위해 필요한 변경을 보여줍니다.
build.gradle (JDBC Wrapper구성 후):
이 변경 사항은 기존 PostgreSQL 드라이버(org.postgresql:postgresql:42.6.0)와 함께 AWS Advanced JDBC Wrapper 라이브러리(software.amazon.jdbc:aws-advanced-jdbc-wrapper:2.5.6)를 추가합니다. Wrapper는 데이터베이스 호출을 가로채서 특정 기능을 추가한 다음 실제 SQL 작업을 PostgreSQL 드라이버에 위임하는 중간 계층 역할을 합니다.
위의 코드 변경 외에도 데이터베이스 연결 설정이 포함된 application.properties 파일의 JDBC URL도 업데이트해야 합니다. 다음 구성은 표준 JDBC의 현재 구성을 보여줍니다.
JDBC Wrapper를 사용하도록 구성하기 전:
db.url=jdbc:postgresql://aurora-jdbc-demo.cluster-abc123.us-east-1.rds.amazonaws.com:5432/postgres다음 구성은 JDBC Wrapper를 사용하도록 구성한 후 필요한 변경 사항을 보여줍니다.
JDBC Wrapper를 사용하도록 구성한 후:
db.url=jdbc:aws-wrapper:postgresql://aurora-jdbc-demo.cluster-abc123.us-east-1.rds.amazonaws.com:5432/postgresaws-wrapper: 접두사는 드라이버 관리자에게 JDBC Wrapper 기능을 사용하도록 지시합니다.
DatabaseConfig.java 파일은 연결 구성을 업데이트합니다. 다음 코드는 표준 JDBC의 현재 구성을 보여줍니다.
JDBC Wrapper를 사용하도록 구성하기 전:
다음 코드는 JDBC Wrapper를 사용하도록 구성한 후 필요한 변경 사항을 보여줍니다.
JDBC Wrapper를 사용하도록 구성한 후:
위 코드는 JDBC URL을 직접 구성 하는 방식에서 JDBC Wrapper를 사용하는 방식으로 전환합니다. 이를 통해 빠른 장애조치 기능을 사용할 수 있으며, 읽기/쓰기 분할과 IAM 인증 같은 고급 기능을 지원합니다. 이러한 클라우드 기능을 추가 하면서도 Wrapper는 모든 실제 데이터베이스 작업을 기본 PostgreSQL 드라이버에 위임합니다. 따라서 애플리케이션의 비즈니스 로직을 변경하지 않고도 Aurora의 클라우드 기능을 제공할 수 있습니다.
위의 모든 변경 사항을 적용하려면 다음 스크립트를 실행한 다음 애플리케이션을 실행합니다.
./demo.sh aws-jdbc-wrapper
위의 스크립트는 JDBC Wrapper를 변경하고 Java 애플리케이션을 실행합니다. 이전과 동일한 출력이 표시되지만, 이제 JDBC Wrapper 기능이 포함됩니다.
연결 풀 이름이 StandardPostgresPool에서 AWSJDBCPool로 변경되었고, 로그에 AWS JDBC Wrapper 연결 풀이 초기화되었다는 메시지가 표시되어 애플리케이션이 현재 JDBC Wrapper를 사용하고 있음을 확인할 수 있습니다. 연결 유형은 software.amazon.jdbc.wrapper.ConnectionWrapper가 기본 org.postgresql.jdbc.PgConnection을 래핑하고 있음을 알 수 있는데, 이는 Wrapper가 PostgreSQL 드라이버에 위임하면서 데이터베이스 호출을 가로채고 있음을 보여줍니다.
운영에서는 여전히 Aurora Writer 엔드포인트를 사용하지만, 비즈니스 로직을 변경하지 않아도 애플리케이션이 빠른 장애조치 기능을 사용할 수 있습니다.
Aurora Writer 엔드포인트에서 모든 작업을 유지하면서 빠른 장애조치 기능이 있는 JDBC Wrapper를 사용하도록 애플리케이션을 성공적으로 구성했으므로, 다음 단계는 읽기/쓰기 분할을 구성하여 Aurora 복제본에 읽기 작업을 분산하고 성능을 최적화합니다.
3단계: 읽기/쓰기 분할 활성화
이제 연결 라우팅을 활성화하여 JDBC Wrapper 읽기/쓰기 기능을 구현합니다. 연결 라우팅을 사용하면 roundRobin, fastestResponse 같은 Reader 선택 전략에 따라 쓰기가 Aurora 기본 인스턴스로 이동하고 읽기가 Aurora 복제본에 분산됩니다. 자세한 구성 정보는 Reader Selection Strategies을 참조합니다.
JDBC Wrapper를 사용하는 HikariCP의 성능 고려 사항
데모 애플리케이션은 다양한 사용 사례를 보여주기 위해 외부 HikariCP 연결 풀링을 사용합니다. 하지만 읽기/쓰기 작업이 빈번한 프로덕션 애플리케이션의 경우 JDBC Wrapper의 내부 연결 풀링을 사용하는 것이 좋습니다. 현재 JDBC Wrapper는 내부 연결 풀을 만들고 유지하는 데 HikariCP를 사용합니다.
내부 및 외부 풀을 사용하여 성능을 테스트하고 읽기/쓰기 분할을 사용하지 않은 경우와의 비교를 포함한 자세한 예제는 세 가지 접근 방식을 보여주는 ReadWriteSplittingSample.java 예를 참조합니다.
Spring Boot/Framework 고려 사항
Spring Boot/Framework를 사용하는 경우, 읽기/쓰기 분할 기능을 사용할 때 성능에 미치는 영향을 고려해야 합니다. 예를 들어 @Transactional(ReadOnly = true) 어노테이션은 Reader와 Writer 연결간 지속적인 전환으로 인해 성능 저하를 유발할 수 있습니다. 이러한 고려 사항과 권장 해결 방법에 대한 자세한 내용은 Limitations when using Spring Boot/Framework을 참조합니다.
읽기/쓰기 분할 사용을 위한 변경 사항
읽기/쓰기 분할을 사용하기 위해 필요한 변경 사항을 살펴봅니다. DatabaseConfig.java 파일에 readWriteSplitting 플러그인을 추가합니다.
다음 코드는 장애조치 기능이 포함된 기존 JDBC Wrapper 구성을 보여 줍니다.
targetProps.setProperty("wrapperPlugins", "failover");
읽기/쓰기 분할 사용을 허용하도록 업데이트된 코드는 다음과 같습니다.
targetProps.setProperty("wrapperPlugins","readWriteSplitting,failover");
OrderDAO.java 파일은 연결을 읽기 전용으로 표시하여 Reader 인스턴스로 라우팅할 수 있도록 합니다.
읽기/쓰기 분할 구성 실행
./demo.sh read-write-splitting다음은 설정을 실행한 후의 샘플 출력입니다.
JDBC Wrapper는 이제 쓰기 작업을 Aurora Writer 엔드포인트(기본 인스턴스)로 라우팅하고, 읽기 작업을 Aurora Reader 엔드포인트(복제 인스턴스)로 라우팅합니다. 읽기/쓰기 분할 플러그인은 다음과 같은 이점을 제공합니다.
- 연결 관리 단순화 — 애플리케이션 내에서 읽기와 쓰기 연결을 위한 별도의 연결 풀을 관리할 필요가 없습니다. 애플리케이션에서 Connection#setReadOnly() 메서드를 설정하기만 하면 JDBC Wrapper가 연결을 자동으로 관리합니다.
- 유연한 Reader 선택 전략 — roundRobin, fastestResponse, least connections와 같은 다양한 Reader 선택 전략 중에서 선택하여 특정 애플리케이션 요구 사항 및 워크로드 패턴에 따라 성능을 최적화할 수 있습니다.
- Writer 부하 감소 — 분석 쿼리가 더 이상 트랜잭션 쿼리와 경쟁하지 않습니다.
- 리소스 활용도 향상 — 읽기 트래픽이 여러 복제본에 분산되어 애플리케이션 로직을 변경하지 않고도 각 Aurora 인스턴스가 최적의 워크로드를 처리할 수 있습니다.
정리
나중에 요금이 청구되지 않도록 하려면 이 실습 중에 만든 리소스를 삭제합니다.
AWS CDK 스크립트(옵션 A)를 사용한 경우:
다음 명령을 실행하여 모든 AWS 리소스를 삭제합니다.
리소스를 수동으로 생성한 경우(옵션 B): 생성에 사용한 것과 동일한 방법(AWS Management Console 또는 AWS CLI)을 사용하여 Aurora 클러스터 및 관련 리소스(보안 그룹, DB 서브넷 그룹)를 삭제합니다.
결론
이 게시물에서는 JDBC Wrapper를 사용하여 Aurora의 클라우드 기반 기능으로 자바 애플리케이션을 향상시키는 방법을 살펴보았습니다. 이 게시물에서 소개된 간단한 코드 변경만으로 표준 JDBC 애플리케이션이 빠른 장애조치, 읽기/쓰기 분할, IAM 인증, Secrets Manager 통합, 페더레이션 인증을 사용하도록 변환할 수 있습니다.