How was this content?
- Learn
- How Amazon SageMaker helps Widebot provide Arabic sentiment analysis
How Amazon SageMaker helps Widebot provide Arabic sentiment analysis
Startups are familiar with the importance of creating great customer experiences. Sentiment analysis is one tool that helps with this. It categorizes data as positive, negative, or neutral based on machine learning techniques such as text analysis and natural language processing (NLP). Companies use sentiment analysis to measure the satisfaction of clients for a target product or service.
Sentiment analysis can be particularly challenging to accomplish on Arabic end-users: People across the Middle East and North Africa (MENA) region speak more than 20 dialects of the Arabic language, with Modern Standard Arabic being the most common language.
In this blog post, we explain how Widebot uses Amazon Sagemaker to successfully implement a sentiment classifier. Widebot is one of the leading Arabic-focused conversational artificial intelligence (AI) chatbot platforms in the MENA region. Their sentiment classifier supports Modern Standard Arabic, as well as Egyptian dialect Arabic, with high accuracy when tested on multiple datasets from different domains.
Widebot’s model can be easily tuned after being given a few hundreds of samples from the new domain or dataset. That makes the solution generic and adaptable to different domains and use cases.
The characteristics of a successful chatbot
Chatbots are a useful tool for managing and improving customer experiences, as well as automating tasks so that employees can focus on work critical to their company’s mission. Startups, in particular, are familiar with the value of using managed services so that they can spend their time on the tasks that matter most to their success.
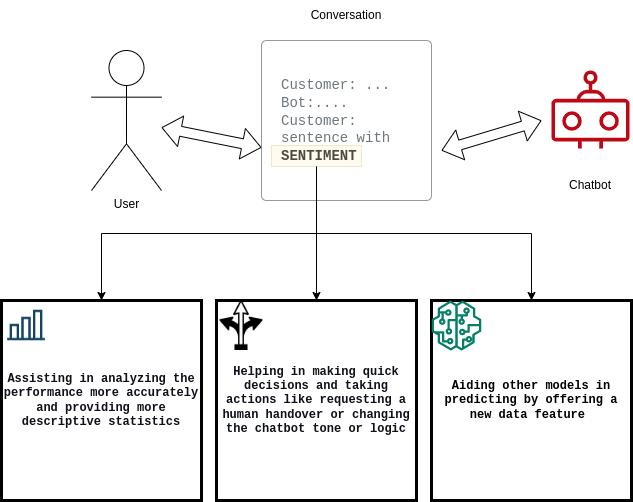
It’s important for chatbots to quantify satisfied or unsatisfied customers, as well as document the conversion rate from satisfied-to-unsatisfied (or vice versa). To meet these requirements, Widebot’s solution:
- Helps users to analyze the performance of their chatbot system
- Improves the decision-making of the chatbot
- Aids other downstream machine learning (ML) models
Technical challenges of building sentiment analysis
Widebot data scientists are always innovating to enhance and optimize their deep learning models to keep up with their customers’ growing expectations. To better serve their Arabic chatbot customers, they worked to develop a new solution for Arabic sentiment analysis deep learning models.
The challenges of this included:
- Model scalability
- Response time
- Massive concurrency requests
- The running cost
As is the case for many startups, they initially deployed the model on self-managed infrastructure and general-purpose servers. However, as their startup grew, they couldn’t efficiently scale the model to accommodate for the growing data and spikes on concurrent requests.
Widebot began looking for a solution to help them focus on building the models quickly, without devoting undue time to managing and scaling the underlying infrastructure and machine learning operations (MLOps) workflows.
Model deployment on Amazon SageMaker
Widebot chose SageMaker because it provides a broad selection of ML infrastructure and model deployment options to meet all their ML inference needs. SageMaker makes it easy for startups to deploy ML models at the best price performance.
“Fortunately, we found that Amazon SageMaker gives us full ownership and control throughout the model development lifecycle. SageMaker’s simple and powerful tools allow us to automate and standardize the MLOps practice to build, train, deploy, and manage models more easily and quickly than was possible through our self-managed infrastructure,” said Mohamed Mostafa, co-founder and Chief Technology Officer (CTO), Widebot.
The Widebot team are now able to focus on building and enhancing their ML models to meet their customer expectations, while SageMaker takes care of setting up and managing instances, software version compatibilities, and patching versions. SageMaker also provides built-in metrics and logs for endpoints to keep monitoring the model health and performance.
Amazon SageMaker Inference Recommender helped Widebot to choose the best compute instance and configuration to deploy their ML models for optimal inference performance and cost. SageMaker Inference Recommender automatically selects the compute instance type, instance count, container parameters, and model optimizations for inference to maximize performance and minimize cost.
Widebot also uses various AWS services to build their architecture, including Amazon Simple Storage Service (Amazon S3), AWS Lambda, Amazon API Gateway, and Amazon Elastic Container Registry (ECR):
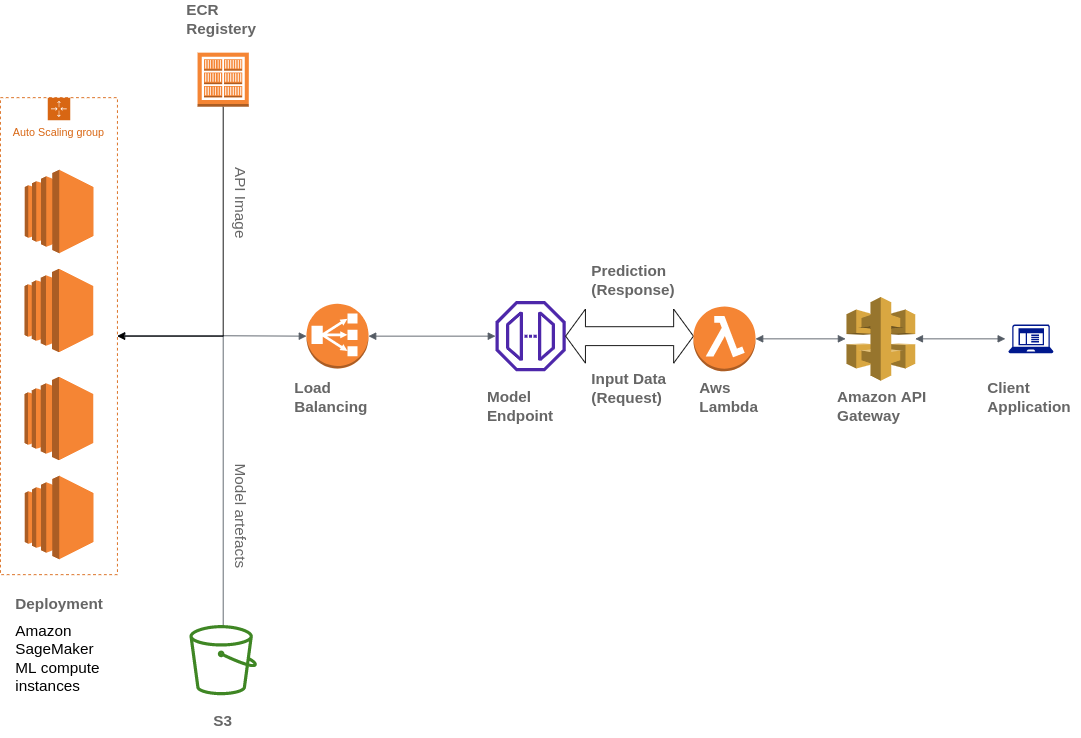
Widebot was looking for a solution to securely publish the ML models they developed for their customers as an API endpoint. They used API Gateway, a fully managed service, to publish, maintain, monitor, and secure the API endpoints of the ML models deployed on SageMaker. API Gateway is used as an external-facing, single point of entry for SageMaker endpoints that makes them easily and securely accessible from clients.
Clients interact with the SageMaker inference endpoint by sending an API request to the API Gateway endpoint. The API Gateway maps client requests to the corresponding SageMaker inference endpoint and invokes the endpoint to obtain an inference from the model. Subsequently, the API Gateway receives the response from the SageMaker endpoint and maps it back, in a response sent to the client.
Solution overview
How did Widebot build a successful new solution for Arabic sentiment analysis deep learning models? Here are the steps they followed:
Datasets collection and preparation
Collect tens of thousands of data samples from different data sources (both public and in-house).
Review the datasets carefully, apply data labeling, and improved the data quality by removing irrelevant samples.
The data team conducts an annotation process, using Amazon SageMaker Ground Truth to annotate enough samples from different domains and writing styles to enrich the dataset used.
Send samples through the preprocessing pipeline, before training the model using deep learning to classify the input text as positive, negative, or neutral, with the probability of each.
Building and training the model
Use a Convolutional Neural Network (CNN) model trained using Keras and TensorFlow.
Apply many iterations to test different preprocessing pipelines, architectures, and tokenizers, until reaching the architecture that yields the best results on different sample datasets and from different domains.
Use a native preprocessing pipeline developed in-house to remove unnecessary information from the text: dates, URLs, mentions, email addresses, punctuation (except for ‘!?’), and numbers.
Apply Arabic text normalization steps, like stripping diacritics and normalizing some letters that users used interchangeably, like (ء أ ئ ؤ إ) or yaa (ي ى) or other characters.
Apply light stemming on the text that removes some suffixes and prefixes and reduces some inflated words into their stem (for example, (التعيينات) reduced into (تعيين)).
Save the model, preprocessor, hyper-parameters, and tokenizers using serialization and export them as .h5 and .pickle files.
Deploying the model on Amazon SageMaker
Wrap the model into an API, the prediction endpoint. That endpoint accepts JSON input from the end user and transforms data into an easier data structure, cleans it, and returns the sentiment results of the input data.
Create a Docker image that contains the code, all dependencies, and instructions required to build and run the components in any environment.
Upload the model artifacts to an Amazon S3 bucket and the Docker image to Amazon ECR.
Deploy the model using SageMaker, selecting the image location in Amazon ECR and the artifacts URI in the Amazon S3 bucket.
Create an endpoint using SageMaker and leverage API Gateway to publish the endpoint to their clients.
Type and volume of data
To build their model, Widebot’s data consists of approximately 100,000 different messages for training and 20,000 messages for validation and testing. The messages:
- Came from different industries, such as e-commerce, food and beverage, and financial services.
- Included reviews for different services or products. For example, hotel reviews, booking reviews, restaurant reviews, and company reviews.
- Ranged in tone from very formal language to the use of severe profane words.
- Were written in both Egyptian dialect and Modern Standard Arabic.
- Were classified into one of three classes: negative, neutral, or positive.
The following table shows sample messages:
| Example | Sentiment | Confidence |
| الخدمة لديكم مناسبة “Your service is good” | positive | 0.8471 |
| شكرا لحسن تعاونكم “Thank you for your cooperation ” | positive | 0.9688 |
| الخدمة والتعامل لديكم دون المستوى “Your service is substandard” | negative | 0.8982 |
| حالة الجو سيئة جدا “The weather is very bad” | negative | 0.9737 |
| سأعاود الإتصال بكم وقت لاحق “I will contact you later” | neutral | 0.8255 |
| أريد الإستعلام عن الخدمات “I want to inquire about the services” | neutral | 0.9728 |
Results Summary
Widebot tested their model against different Arabic text datasets in various dialects. These metrics were measured using datasets with thousands of samples. The F1-score is used to measure the model’s accuracy with the different datasets. The macro and weighted averages of the F1 score are used to measure overall precision and performance.
The model accuracy
The testing dataset (20,679 samples in the ratio 5004:1783:13892)
| Negative F1 | Neutral F1 | Positive F1 | Overall accuracy | Macro average | Weighted average |
| 89.9 | 79.4 | 95.1 | 92.5 | 88.1 | 92.5 |
The model response time
Widebot measured the response time using the average (AVG), minimum (MIN), and maximum (MAX) seconds per response (sec./response):
- AVG: 0.106 sec./response
- MIN: 0.088 sec./response
- MAX: 0.957 sec./response
The following compares the response-time metric between using a general-purpose compute platform and using Amazon SageMaker for model hosting, when deploying the same datasets with an average payload size of 2 KB.
| Total response time | Total response timeGeneral compute platform(EC2 instances: p2.xlarge) | Amazon SageMaker(SageMaker instances: ml.m4.xlarge) |
| Average | 0.202 sec./response | 0.106 sec./response |
| Minimum | 0.097 sec./response | 0.088 sec./response |
| Maximum | 8.458 sec./response | 0.957 sec./response |
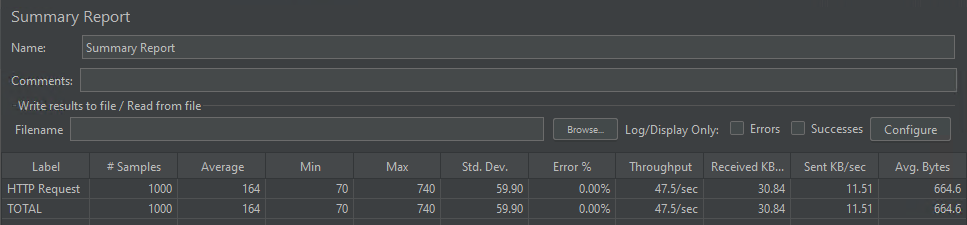
The model concurrency
The model was able to handle 1,000 concurrent requests served on average in 164 milliseconds.
Conclusion
This post shows how AWS services helped Widebot to build a comprehensive solution to extract sentiments from chat text in different Arabic dialects, using a deep learning model hosted on SageMaker.
SageMaker helped Widebot innovate faster and deploy their sentiment classifier to solve the complex ML problem of extracting sentiments from Arabic conversational text and to publish this as a public RESTful endpoint for clients to access easily and securely via the API Gateway.
This approach could be useful for many similar use cases, where customers want to build, train and deploy their ML model on SageMaker and then publish the model inference endpoint for their customers in a simple yet secure way, using the API Gateway.
If you are interested in reading more on linguistic diversity and how to fine tune pre-trained transformer-based language models on Amazon SageMaker, you can read this blogpost.

Mohamed Mostafa
Mohamed Mostafa is co-founder and CTO at WideBot. He is passionate about applying modern engineering practices and developing high-quality software to improve users’ experience.

Ahmed Azzam
Ahmed Azzam is a Senior Solutions Architect based in Dubai, UAE. He is passionate about helping startups not only architect and develop scalable applications but also think big on innovative solutions using AWS services.
How was this content?