



¿Qué es el boosting en machine learning?
El boosting es un método utilizado en el machine learning para reducir los errores en el análisis predictivo de datos. Los científicos de datos entrenan el software de machine learning, llamado modelos de machine learning, con datos etiquetados para efectuar predicciones sobre datos no etiquetados. Un único modelo de machine learning puede cometer errores de predicción según la precisión del conjunto de datos de entrenamiento. Por ejemplo, si un modelo de identificación de gatos se entrenó solo con imágenes de gatos blancos, es posible que en ocasiones no identifique un gato de color negro. El boosting intenta solucionar este problema mediante el entrenamiento secuencial de varios modelos para mejorar la precisión del sistema en general.
¿Por qué es importante el boosting?
El boosting mejora la precisión predictiva y el rendimiento de los modelos de machine learning, ya que convierte varios estudiantes débiles en un modelo de aprendizaje fuerte y único. Los modelos de machine learning pueden ser estudiantes débiles o estudiantes fuertes:
Estudiantes débiles
Los estudiantes débiles tienen una precisión de predicción baja, similar a predicciones aleatorias. Son propensos al sobreajuste, es decir, no pueden clasificar datos que varían demasiado de su conjunto de datos original. Por ejemplo, si entrena el modelo para identificar a los gatos como animales que tienen orejas puntiagudas, es probable que el modelo no reconozca a un gato que tenga las orejas dobladas.
Estudiantes fuertes
Los estudiantes fuertes tienen una precisión de predicción más alta. El boosting convierte un sistema de estudiantes débiles en un único sistema de aprendizaje fuerte. Por ejemplo, para identificar la imagen del gato, se combina un estudiante débil que identifica las orejas puntiagudas y otro estudiante que identifica la forma de los ojos. Después de analizar la imagen del animal por las orejas puntiagudas, el sistema la analiza una vez más por la forma de los ojos. Esto mejora la precisión general del sistema.
¿Cómo funciona el boosting?
Para comprender cómo funciona el boosting, describiremos cómo toman decisiones los modelos de machine learning. Si bien existen muchas variaciones en la implementación, los científicos de datos muchas veces utilizan algoritmos de árbol de decisión:
Árboles de decisión
Los árboles de decisión son estructuras de datos en el machine learning que dividen el conjunto de datos en subconjuntos cada vez más pequeños en función de sus características. La idea es que los árboles de decisión dividan los datos reiteradamente hasta que solo quede una clase. Por ejemplo, es posible que el árbol haga una serie de preguntas de sí o no y divida los datos en categorías en cada paso.
Método de conjunto boosting
El boosting crea un modelo de conjunto mediante la combinación secuencial de varios árboles de decisión débiles. Asigna ponderaciones a las salidas de los árboles individuales. Luego, a las clasificaciones incorrectas del primer árbol de decisión les da una ponderación más alta y una entrada al árbol siguiente. Después de numerosos ciclos, el método boosting combina estas reglas débiles en una única regla de predicción poderosa.
Boosting en comparación con bagging
Boosting y bagging son los dos métodos de conjunto comunes que mejoran la precisión de la predicción. La diferencia principal entre estos métodos de aprendizaje es el método de entrenamiento. En el bagging, los científicos de datos mejoran la precisión de los estudiantes débiles mediante el entrenamiento de varios de ellos a la vez y en varios conjuntos de datos. En cambio, el boosting entrena a los estudiantes débiles de forma individual.
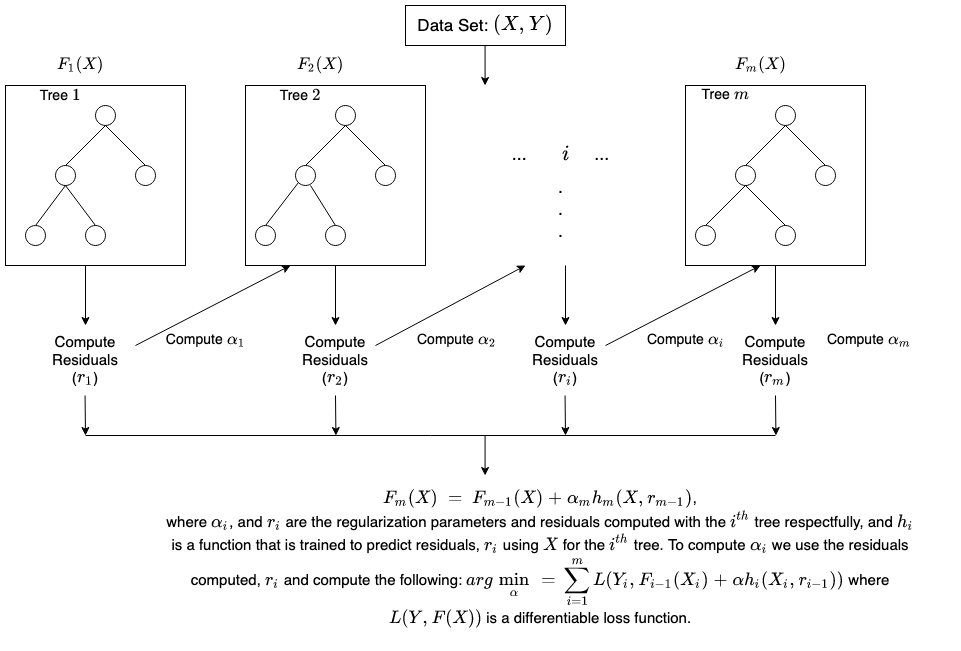
¿Cómo se lleva a cabo el entrenamiento en el boosting?
El método de entrenamiento varía en función del tipo de proceso de boosting denominado algoritmo de boosting. Sin embargo, un algoritmo sigue los siguientes pasos generales para entrenar el modelo de boosting:
Paso 1
El algoritmo de boosting asigna la misma ponderación a cada muestra de datos. Ingresa los datos al primer modelo de machine learning, llamado algoritmo base. El algoritmo base hace predicciones para cada muestra de datos.
Paso 2
El algoritmo de boosting evalúa las predicciones del modelo y aumenta la ponderación de las muestras que presentan un error más significativo. También asigna una ponderación basada en el rendimiento del modelo. Un modelo que genera excelentes predicciones tendrá una gran influencia sobre la decisión final.
Paso 3
El algoritmo pasa los datos ponderados al siguiente árbol de decisión.
Paso 4
El algoritmo repite los pasos 2 y 3 hasta que las instancias de errores de entrenamiento estén por debajo de cierto límite.