AWS Partner Network (APN) Blog
A Decade of Evolution at Lemongrass: SAP on AWS Business Continuity
By Ben Lingwood, CIO – Lemongrass
 |
Just utter the phrase “HA/DR” in any IT forum and you’ll likely get 10 different passionate views spanning 15+ years of technology depending on the last time the attendees touched a console.
Of all the workshops I run in my position as CIO at Lemongrass, an AWS Premier Consulting Partner with the SAP on AWS Competency, this is the one that calls on educational, technical, and U.N. Peacekeeper skills in equal measures.
Below are a few facts about HA/DR, which stands for high availability disaster recovery:
- It remains one of the most misunderstood topics in a cloud environment which, when coupled with business requirements evolved from physical “hosting” DNA, typically results in huge overspending.
- Conversely, it’s an area our team at Lemongrass see massive shortcuts being made to create low price points. The cost may be lower, but it puts you in the ironic position of having a technically higher risk solution in your Statement of Work (SOW). Spinning the roulette wheel on your recovery metrics is a high-stakes game.
- There’s a tendency to over-engineer business continuity designs. Keeping it simple and cloud-native usually means there is less to go wrong.
In this post, I will review the top four challenges we have seen repeatedly over 10+ years of migrating SAP workloads to Amazon Web Services (AWS). These challenges arise in customer response documents for moving SAP-centric landscapes to AWS, so I will also review key points to consider when designing business continuity architecture.
1. Shortcuts Come with a (Recovery Point) Health Warning
Over the years, we have seen customers struggle with large price variations in SAP on AWS platform architecture between vendors. One of the culprits here is often the approach to business recovery, as it’s full of tempting commercial shortcuts to offer that winning price point.
Here are some recent real-life examples:
| Compromise | Impacts |
| Stacking Dev, QA DB on the same EC2 instance | Unable to scale independently; cross-version dependency; 2x maintenance downtime impacts. |
| Stacking app servers, DB on the same Prod EC2 instance | Single point of failure on 1x EC2; unable to auto scale or separate apps. |
| “Sacrificial” QA box for production failover | HA event removes production release path; DB load time can be significant (RTO); failback highly complex; compromised resolution path; can be quite a manual process. |
| No cross-regional resilience | While unlikely, relying on single-region storage does not protect from a full regional outage, or more likely, account compromise. |
| Under-sizing (modern compute is “more powerful” myth) | Untrue: SAP provide theSD2Tier benchmark, certified SAPs and HANA sizing. Only do this if you can downsize. If you size below SAP EWA reported sizing, expect an impact. |
| Technical debt assumptions (delete ~10% of DB to squeeze that DB into a cheaper HANA VM) | Make sure it’s functionally validated. If the data volumes are bigger than the appliance, the DB will not be fully loaded into memory on HANA, resulting in large performance deterioration. |
| Snapshots only for recovery images | Lower resolution recovery point images should always include logs and ideally use AWS validated tools such as the AWS Agent. |
| No OS clustering under the assumption that EC2 restart is fine | EC2 restart is not SLA assured, plus SAP (especially HANA) takes time to memory load making this unsuitable for production RTO and performance as a single mechanism. |
| Storage striping, reduced volume sets | Common shortcut. Incorrect disk stripping = large performance impacts across dialogue, batch and peak processing. You need a performing storage strategy. Make sure it passed SAP TDI testing; it’s free, easy, and provides SAP performance assurance. |
| Manual failover required with aggressive RxO | Simply put, the more aggressive the SLA and RxO the less time for human hands; 99.9% and above we believe always requires clustering and auto-failover mechanisms. |
2. Don’t Flood Fill the SLA Requirement Column
Production = 99.95%. In almost all cases, organizations provide a “Production” service level agreement (SLA) as part of their requirements. While this has been the norm in the IT industry since the inception of SLAs, it’s also a very rigid way of architecting.
At Lemongrass, we recommend using a per application business driven recovery as:
- In an agile cloud environment, you can have different business recovery metrics per application.
- Flood filling SLAs across landscape tiers always results in higher pricing.
- It’s an “un-cloudy” way of architecting. If the technology can provide granular design, why block it?
- Many of the AWS components used in the SAP Cloud architecture offer independent high uptime and are often serverless.
- Original constraints of needing high levels of “physical” redundancy do not apply to cloud.
- It’s not all or nothing. Applications can invoke HA or even DR independently from each other.
For a recent large retail customer, which contained a large landscape of 49 individual SAP systems in the production landscape by adopting a granular architecture (which used three different patterns), Lemongrass removed $400,000 per year from the “flood fill” version of the same bill of materials.
3. Think Recovery Point/Time Objective, Not SLAs
Our industry is fixated on SLAs, sometimes unhealthily so. SLAs are usually interpreted as unplanned downtime per month, but Recovery Point and Time metrics (the amount of data you can sustain losing and return to operations time) are the important data points here, as they unlock the ability to adopt fine-grain recovery patterns.
At a high level, there are three main family groups of SAP on AWS recovery design:
- Application restart or building from system images.
- Pilot lights where secondary systems automatically start up on a schedule, synchronize then go back to “sleep” to save costs.
- Active clusters where no data can be lost.
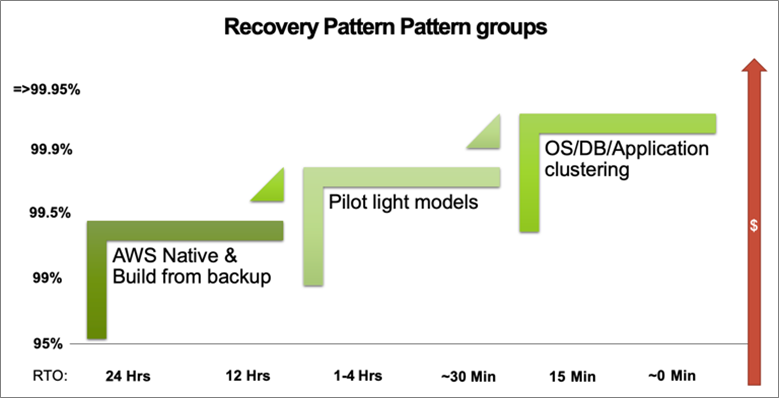
Figure 1 – SAP on AWS recovery pattern groups.
There are a whole family of patterns within each of these areas, but it’s the RTO/RPO that really drives their use and the associated cost. Back to my second point outlined above, selecting a combination of pilot lights and full clusters (usually for systems of record) is a proven way to optimize pricing.
4. Know the Science
Be a science-first organization. Knowing the science of the solution being presented to you will help you meet your recovery targets is important. It’s the difference between knowing why a deal that seems too good to be true probably is, versus being woken up by an incident at three in the morning (we’ve all been there).
Simply put, if any one of the layers in the architecture is unbalanced, then the SLA is an “insurance policy” and not a Well-Architected design. I like to think of it as:
Overall uptime and recovery = AWS Region x EC2 SLA x Storage SLA(s) x OS up x DB Up x SAP CI/MSG + App.
With this in mind, you can look at each layer in the architecture and determine if there’s a failure point.
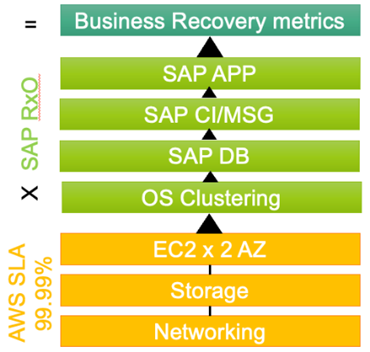
Figure 2 – SAP architecture layers.
Hang On—That’s HA, Not DR
This topic is a big can of worms. If my HA system is in a secondary AWS Availability Zone, is data synchronous, is geographically isolated, and is capable of running production operations, if anything in the primary site goes wrong, is it also DR?
The answer is: it all depends on your origination’s risk perspective. I recommend using AWS Well-Architected best practices, clearly articulated to your vendors, or you’ll end up with mixed architecture interpretations of risk, SLA, and recovery (and usually some of those earlier shortcuts).
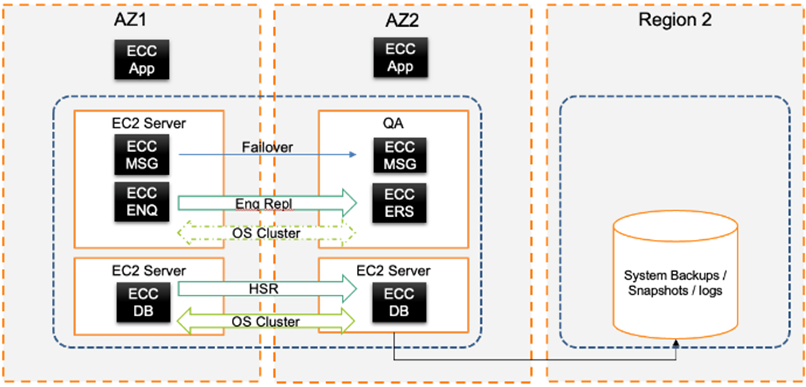
Figure 3 – Example of SAP on AWS architecture that follows best practices.
Conclusion
After a decade of migrating SAP workloads to AWS, our main business continuity design takeaways and learnings are quite simple.
- Make sure you are architecturally aware of what’s being proposed to you so that you can spot any design shortcuts that render the design an insurance policy versus a Well-Architected design.
- Use the flexibility the AWS Cloud can offer you. Each application can have different designs and recoverability so you get maximum design coverage where you need it and save money where you don’t.
- Focus on recovery time and point metrics, as they influence the design per application more accurately than an overall SLA.
At Lemongrass, our thinking is that a regionally resilient design is more than sufficient for many organizations, as it meets and exceeds what is typically run on-premises today.
We couple this with the backup images/snaps being replicated into a second region “just in case” so we have an image from which to rebuild the landscape. It’s the sweet spot between too much (compute) and too little (+risk), plus it protects against root account compromise in a public cloud.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Lemongrass – AWS Partner Spotlight
Lemongrass is an AWS Premier Consulting Partner and leading SAP on AWS service provider with a focus on implementation, migration, operation, innovation, and automation.
Contact Lemongrass | Partner Overview | AWS Marketplace
*Already worked with Lemongrass? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.