AWS Partner Network (APN) Blog
Simplify Workload Monitoring Using Amazon CloudWatch Anomaly Detection
By Pramod Prabhushankar, Sr. Developer – DXC Technology
By Sagayaraj Arulanandam, Delivery Lead, Hybrid Cloud – DXC Technology
By Dhiraj Thakur, Solutions Architect – AWS
 |
| DXC Technology |
 |
DXC Technology is an IT services company using the power of technology to build better futures for customers, colleagues, communities, and the environment.
Customers considering advanced monitoring solutions based on machine learning (ML) to reduce false alarm notifications choose DXC as their implementation partner due to its vast domain experience across industry verticals and deep cloud technology expertise.
DXC’s status as an AWS Premier Tier Services Partner and Managed Cloud Service Provider (MSP) with over 3,000 AWS Certifications drives its ability to help customers who use Amazon Web Services (AWS) to harness the power of innovation and drive their business transformation.
One of DXC’s customers, a large global pharmaceutical company, was spending a large part of its cloud budget on infrastructure support and maintenance. DXC created a monitoring solution for the customer on AWS using anomaly detection alarms powered by machine learning. This solution helped the customer save effort in handling false incidents.
In this post, we will discuss on how DXC analyzed the challenges faced by the customer and how the proposed monitoring solution solves the problem.
Existing Monitoring Challenges
The customer had an existing static alarms-based monitoring solution with the following challenges:
- Used a fixed value threshold and did not support the dynamic range of threshold.
- Lacked the capability to automatically learn trends from historical data.
- Generated several false alarm notifications.
- Alarm configuration was difficult to calibrate correctly and is use-case dependent. It also needs frequent updates based on evolving access patterns.
Solution Architecture
DXC implemented a solution powered by machine learning that uses AWS services including Amazon CloudWatch, Amazon Simple Notification Service (Amazon SNS), and ServiceNow for incident management.

Figure 1 – AWS architecture.
The solution includes CloudWatch anomaly detection which is used to create the alarms. Amazon SNS sends the notification to users and triggers the ServiceNow incidents.
CloudWatch Anomaly Detection
When anomaly detection is enabled for a metric, CloudWatch applies statistical and machine learning algorithms. These algorithms continuously analyze system and application metrics, determine normal baselines and surface anomalies with minimal user intervention.
The algorithms generate an anomaly detection model, which in turn generates a range of expected values that represent normal metric behavior.

Figure 2 – Anomaly detection alarm for CPU utilization.
Anomaly Detection Threshold
When anomaly detection is enabled for a metric, CloudWatch applies ML algorithms to the metric’s past data to create a model of the metric’s expected values.
The model assesses both trends and hourly, daily, and weekly patterns of the metric. The algorithm trains on up to two weeks of metric data, but you can enable anomaly detection on a metric even if the metric doesn’t have a full two weeks of data.
DXC specified a standard value for the anomaly detection threshold that CloudWatch uses along with the model to determine the “normal” range of values for the metric. A higher value for the anomaly detection threshold produces a thicker band of “normal” values.
The ML model is specific to a metric and statistic. For example, if DXC enables anomaly detection for a metric using the AVG statistic, the model is specific to the AVG statistic.

Figure 3 – Metric and statistic.
When CloudWatch creates a model for common AWS services metrics, it ensures the band doesn’t extend outside of logical values. For example, a band for a statistic that can’t be negative will never extend below zero, and a band for a percentage metric will stay between zero and 100.
After a model is created, CloudWatch anomaly detection continually evaluates the model and adjusts it to ensure it’s as accurate as possible. This includes retraining the model to adjust if the metric values evolve over time or have sudden changes, and includes predictors to improve the models of metrics that are seasonal, spiky, or sparse.
Evaluating an Alarm
When an alarm is created, DXC’s solution specifies three settings to enable CloudWatch to determine when to change the alarm state:
- Period: This is the length of time to evaluate the metric to create each individual data point for an alarm. It is expressed in seconds. If you choose one minute as the period, the alarm evaluates the metric once per minute.
- Evaluation periods: This is the number of the most recent periods, or data points, to evaluate when determining alarm state.
- Data points to alarm: This is the number of data points within the evaluation periods that must be breaching to activate the ALARM state. The breaching data points don’t have to be consecutive, but they must all be within the last number of data points equal to evaluation period.
Alarm Actions
DXC can specify what actions an alarm takes when it changes state between the OK, ALARM, and INSUFFICIENT_DATA states. The most common type of alarm action is to notify one or more people by sending a message to an Amazon SNS topic.
Steps to Configure Anomaly Detection Alarms
- Open Amazon CloudWatch and click on All alarms and Create alarm.

Figure 4 – Anomaly alarm creation.
- Select the metrics you want to create the alarm for, such as CPU Utilization.
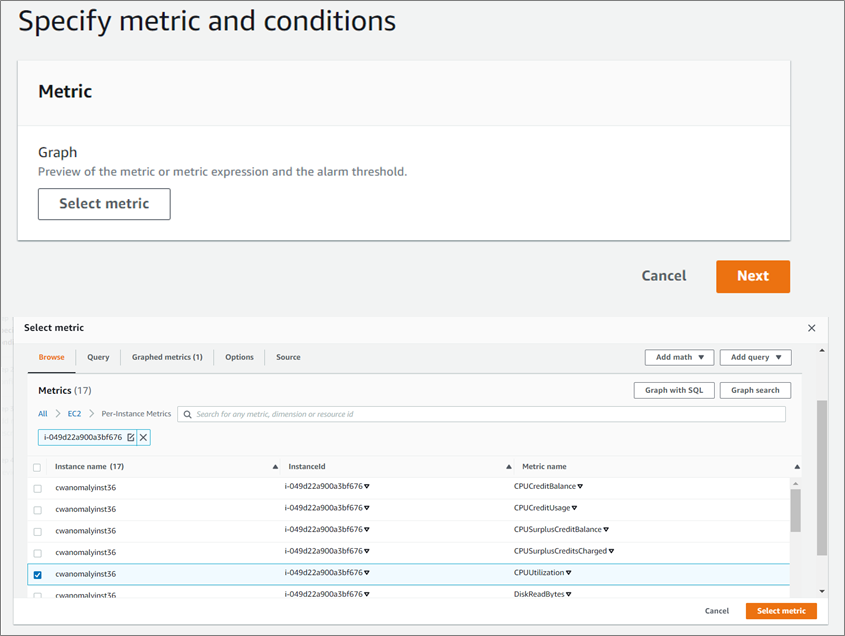
Figure 5 – Select the metrics you want to create the alarm for.
- Provide all of the necessary details in the alarm creation page, choose Threshold type as Anomaly Detection and anomaly detection threshold as 2.
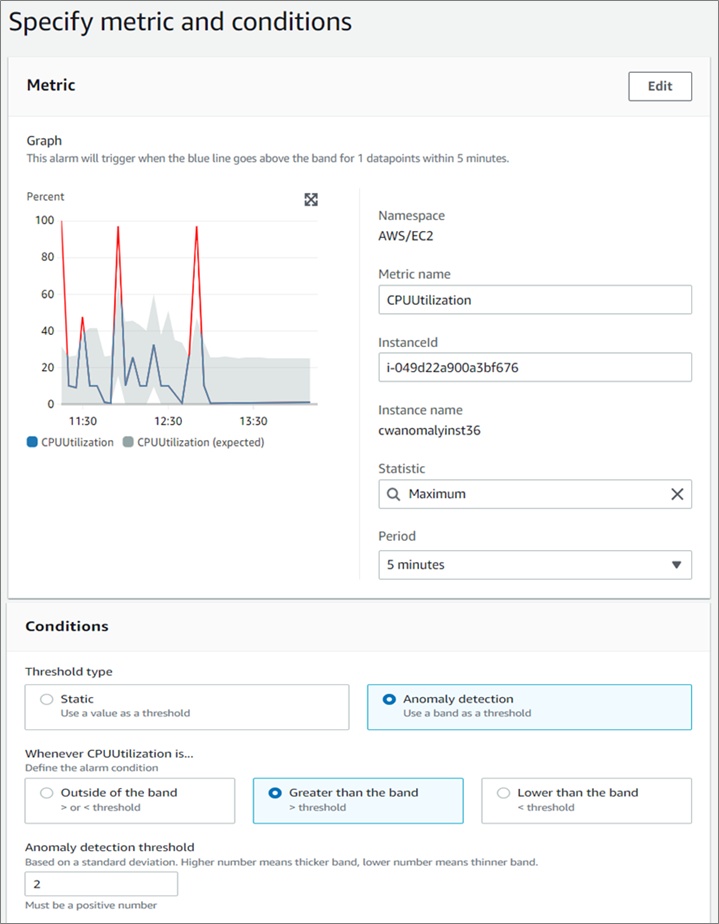
Figure 6 – Provide all of the necessary details in the alarm creation page.
- Click on Additional Configuration and choose 2 data points out of 2 evaluation periods.

Figure 7 – Additional configuration.
- Configure the alarm actions. Choose the “In alarm” state and select the required SNS topic for notifications.
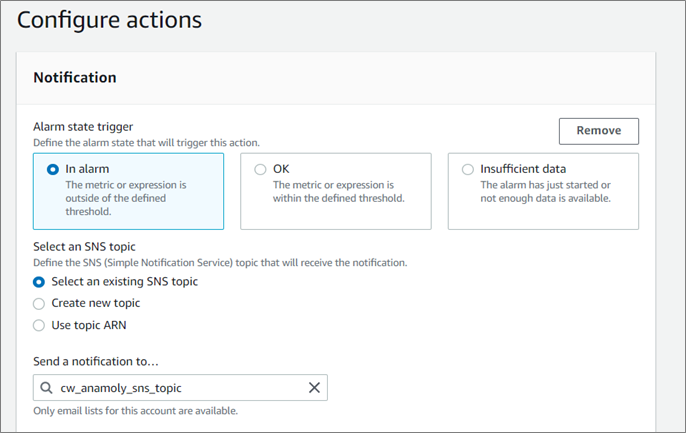
Figure 8 – Configure the alarm actions.
- Provide name, description, and create the alarm.

Figure 9 – Provide name, description, and create the alarm.
Best Practices Learned
- More data for better prediction. You should have enough historical data for the machine learning model to work effectively. Anomaly detection uses up to two weeks of historical data for training.
- Anomaly detection cannot predict black swan events. For example, a sudden burst of traffic over a very short period.
- Exclude black swan events from training datasets while training your model. If you don’t then your model will not give you a predictable confidence band that is truly reflective of your day-to-day access pattern. This feature is ideal for a very predictable usage trend.
- Configure data points carefully. DXC configured two data points for two evaluation periods, which reduces the alarms comparatively.
- Configure data bands creatively. Based on DXC’s analysis, band 2 was configured for a critical system and a higher band for a less critical system.
- Run static and anomaly detection alarms. You can do this as part of a proof of concept (PoC) for some time, compare the result, and tweak accordingly. You can discontinue the static alarm once you achieve the result.
Results Achieved
DXC implemented the solution through the combination of its build approach, adhering to AWS best practices as well as DXC’s own application development approach.
Results achieved for the customer included:
- CloudWatch anomaly detection uses advanced ML capabilities to detect anomalous usage pattern with minimal user intervention.
- New alarm self-adjusts based on the dynamic usage pattern. This helped avoid manual configuration in case a workload access pattern gets evolved.
- Set up proactive monitoring which provides in-time alerts when workload behavior changes unexpectedly.
- Depending on the type of workloads, events/incidents are reduced from ~15% to ~40%. This allows operations to focus on real incidents that require attention, and provides better insights to application owners to manage the performance of their applications.
- ML-enabled usage patterns helped recommend better instance types to resolve performance issues and avoid business escalation. As a result, customers don’t need to project too much into the future, overthinking all the possible ways anomalies may arise.
Conclusion
The key takeaway for DXC Technology from this use case for anomaly detection alarm is the elimination of unnecessary false alarms which reduce the large number of incidents. This helps support teams to reduce spending time on false alarms.
Through AWS managed services, DXC was able to utilize an approach that changed all layers of the solution in a controlled, planned, and tested way—and with rollback possible should any issues occur.
.

.
DXC Technology – AWS Partner Spotlight
DXC Technology is an AWS Premier Tier Services Partner and MSP that understands the complexities of migrating workloads to AWS in large-scale environments, and the skills needed for success.