In modern microservices architectures, configuration management remains one of the most challenging operational concerns. Two gaps emerge as organizations scale: handling tenant metadata that changes faster than cache TTL allows, and scaling the metadata service itself without creating a performance bottleneck.
Traditional caching strategies force an uncomfortable trade-off: either accept stale tenant context (risking incorrect data isolation or feature flags), or implement aggressive cache invalidation that sacrifices performance and increases load on your metadata service. When tenant counts grow into the hundreds or thousands, this metadata service itself becomes a scaling challenge, particularly when different configuration types have vastly different access patterns.
The challenge intensifies when you need to support different storage backends for different configuration types. Some require high-frequency access patterns suited for Amazon DynamoDB, while others benefit from the hierarchical organization and built-in versioning of AWS Systems Manager Parameter Store. Traditional solutions often force engineering teams into a corner: either build multiple configuration services (increasing operational overhead), or compromise on performance by using a single storage backend that isn’t optimized for every use case.
In this post, we demonstrate how you can build a scalable, multi-tenant configuration service using the tagged storage pattern, an architectural approach that uses key prefixes (like tenant_config_ or param_config_) to automatically route configuration requests to the most appropriate AWS storage service. This pattern maintains strict tenant isolation and supports real-time, zero-downtime configuration updates through event-driven architecture, alleviating the cache staleness problem.
What you’ll learn:
- Implementing a multi-tenant data model with DynamoDB and Parameter Store
- Using the Strategy pattern for flexible storage backend switching
- Building tenant isolation through JSON Web Token (JWT) claims
- Creating an event-driven auto-refresh mechanism with Amazon EventBridge and AWS Lambda
- Implementing zero-downtime configuration updates with gRPC (a high-performance communication protocol) streaming
- Addressing the cache TTL problem for rapidly-changing tenant metadata
By the end of this post, you’ll understand how to architect a configuration service that handles complex multi-tenant requirements while optimizing for both performance and operational simplicity.
Solution overview
The architecture uses four AWS services orchestrated through a NestJS-based gRPC service to create a reliable, event-driven configuration management system. Let’s first understand the overall architecture before diving into each component’s implementation details.
Architecture components
The following diagram shows the end-to-end architecture of the Multi-Tenant Configuration Service deployed on AWS, from how client requests enter the system to how configuration data is retrieved from the right storage backend.
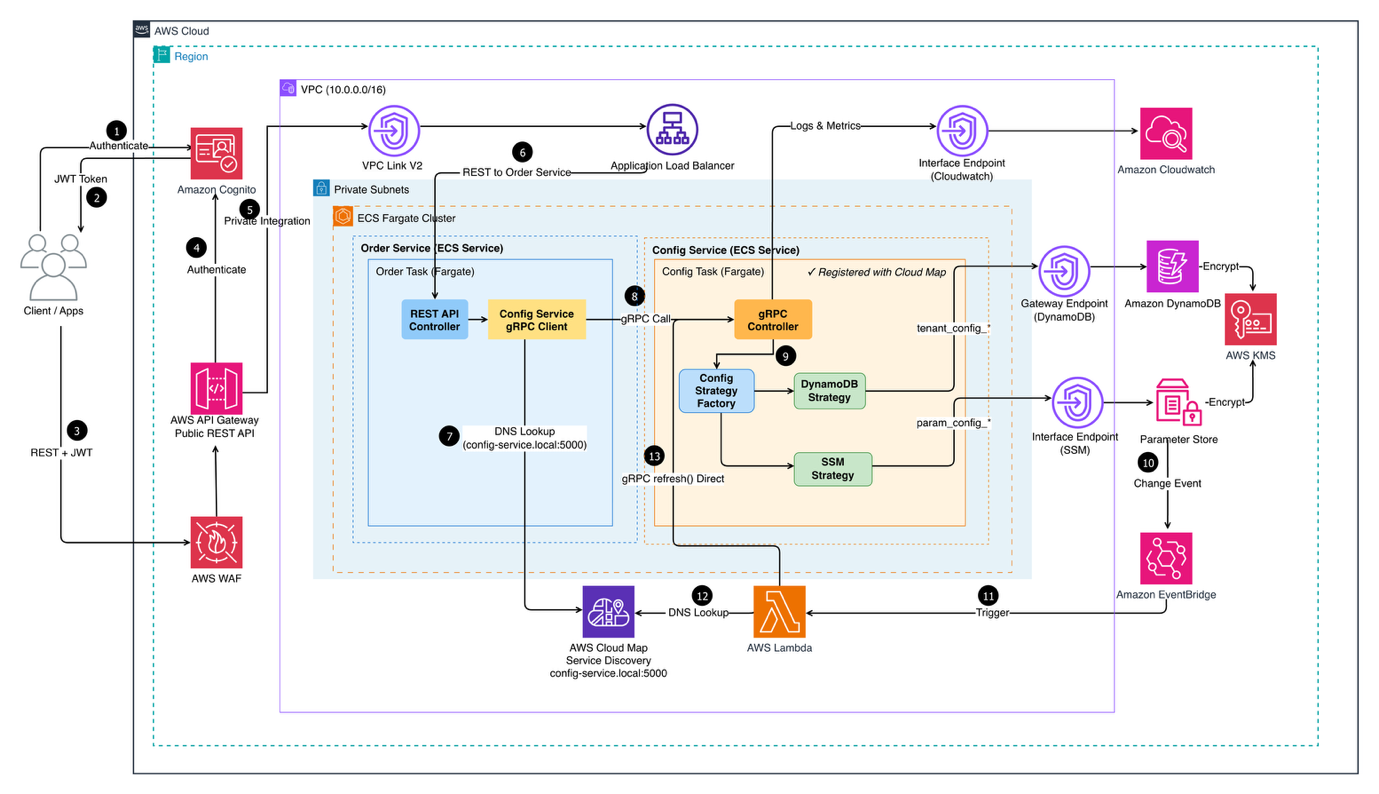
Figure 1: Multi-Tenant Configuration Service Architecture
Client applications authenticate via Amazon Cognito and pass through AWS WAF before reaching Amazon API Gateway. Traffic is then routed through a VPC Link to an Application Load Balancer, which distributes requests across two core microservices running on Amazon Elastic Container Service (Amazon ECS) on AWS Fargate within private subnets :
- Order Service— handles incoming REST requests and delegates configuration lookups to the Config Service via gRPC
- Config Service— exposes a gRPC API and uses a Config Strategy Factory to dynamically select the appropriate storage backend (DynamoDB or Parameter Store) based on the request
Service discovery is managed by AWS Cloud Map, while Amazon CloudWatch centralizes logs and metrics across services.
The system is organized into four interconnected layers, each addressing a specific aspect of the configuration management challenge:
1. Storage layer – multi-backend strategy
The storage layer strategically uses two complementary AWS services, each optimized for different configuration access patterns and requirements.
- Amazon DynamoDB: Stores tenant-specific configurations. These are settings unique to each customer, such as payment gateway preferences or feature flags. With single-digit millisecond latency, DynamoDB handles high-frequency reads efficiently. The schema uses composite keys (
TENANT#{tenantId} as partition key, CONFIG#{configType} as sort key) for efficient tenant-scoped queries and built-in multi-tenant isolation at the data model level.
- AWS Systems Manager Parameter Store: manages shared parameters. These are configuration values used across multiple services or tenants, such as API endpoints, database connection strings, and region-specific settings. Unlike tenant-specific configs that change frequently, these parameters are relatively static but benefit from hierarchical organization. The path structure (
/config-service/{tenantId}/{service}/{parameter}) enables bulk retrieval operations, reducing the number of API calls needed during service initialization from dozens to a single request.
2. Service layer – gRPC with strategy pattern
A NestJS-based microservice implements the configuration retrieval logic using gRPC for high-performance, type-safe communication. This choice significantly reduces network bandwidth and improves response times for service-to-service communication where compatibility with web browsers isn’t a requirement.
At the core is a Strategy Pattern implementation that determines the optimal storage backend based on configuration key prefixes. This pattern simplifies the addition of new storage backends (like Amazon Simple Storage Service (Amazon S3) for large configuration files) without modifying the core service logic.
3. Authentication layer – Amazon Cognito
User authentication flows through Amazon Cognito with custom attributes:
custom:tenantId (immutable) – Tenant identifier embedded in JWTcustom:role (mutable) – User role for authorization
Critical security design: The service never accepts tenantId from request parameters. Instead, it extracts the tenant context from validated JWT tokens, making sure requests cannot access other tenants’ data even if they attempt to manipulate request payloads.
4. Event-driven refresh layer
Traditional configuration updates present a dilemma: how do you keep services synchronized without compromising performance or causing downtime?
Polling approaches continuously check for changes, generating unnecessary API calls that cost money even when nothing changes. They also introduce delays. Services don’t see updates until the next poll cycle, which could be seconds or minutes later.
Service restart approaches cause downtime, drop active connections, and disrupt user sessions. For SaaS applications serving customers 24/7, restart-based updates are unacceptable.
The event-driven refresh layer addresses both problems by implementing a reactive architecture where Amazon EventBridge monitors Parameter Store for changes and triggers AWS Lambda to update the service’s local cache. This achieves configuration updates within seconds while users experience no interruption.
Technical implementation
The following sections detail the implementation, starting with the data model, which serves as the backbone for tenant isolation and efficient querying.
A. Multi-tenant data model
The foundation of tenant isolation begins with the data model. Using DynamoDB’s composite key structure, we achieve both tenant isolation and efficient querying without requiring separate tables per tenant.
DynamoDB schema design:
The following example shows a tenant-specific configuration stored in DynamoDB, illustrating how composite keys enable both isolation and efficient access:
{
"pk": "TENANT#acme-corp",
"sk": "CONFIG#payment-gateway",
"config": {
"providers": [
{
"name": "Stripe",
"apiEndpoint": "https://api.stripe.com",
"retryPolicy": "exponential"
}
]
},
"isActive": true,
"version": 2,
"createdAt": "2024-01-15T10:30:00Z",
"updatedAt": "2024-02-20T14:45:00Z"
}
Key schema decisions:
- Partition key pattern:
TENANT#{tenantId} makes sure tenant data is co-located, enabling efficient tenant-scoped queries while maintaining logical separation.
- Sort key pattern:
CONFIG#{configType} allows querying specific configuration types within a tenant’s data. The CONFIG# prefix enables future expansion with other entity types (for example, METADATA#, AUDIT#).
- Soft deletion: The
isActive boolean flag supports soft deletion, maintaining audit trails while excluding inactive configurations from queries.
- Versioning: The version field tracks configuration changes, supporting rollback capabilities and change history.
Parameter store organization:
Parameters follow a hierarchical structure that mirrors the multi-tenant model. This example demonstrates the path structure:
/config-service/
├── acme-corp/
│ ├── api/
│ │ ├── api-key
│ │ └── endpoint
│ └── database/
│ └── connection-string
└── globex-inc/
├── api/
│ ├── api-key
│ └── endpoint
└── database/
└── connection-string
This structure provides several benefits:
- Bulk retrieval using path prefix (
GetParametersByPath API)
- Clear ownership and access control through AWS Identity and Access Management (AWS IAM) policies
- Environment separation (dev/staging/prod) at the path level
- Automatic parameter versioning and change tracking
Advanced: Multi-dimensional tenant context
For organizations with multiple services requiring different configuration scopes, consider introducing a second dimension in the partition key:
PK = "TENANT#acme-corp|SERVICE#order-service"
SK = "CONFIG#payment-gateway"
This multi-dimensional approach enables service-level isolation where the Order service sees only billing API configurations while the Reporting service doesn’t have access to payment gateway settings. It also provides efficient service-scoped queries, retrieve configurations for a specific service with PK = TENANT#acme-corp|SERVICE#order-service and SK begins with CONFIG#. The second dimension can represent business units, geographic regions, or a logical boundary that aligns with access control requirements, making this pattern particularly valuable when fine-grained access control beyond tenant-level isolation is needed. For detailed guidance on multi-tenant DynamoDB modelling patterns, see amazon-dynamodb-data-modeling-for-multi-tenancy-part-2.
B. Strategy pattern for storage flexibility
The system decides which storage backend to use for each configuration request. The Strategy Pattern is a design approach that allows a program to choose different behaviors at runtime based on context. Think of it like a traffic controller that examines each request and directs it to the appropriate service.
Why use the strategy pattern?
Without the Strategy Pattern, handling multiple storage backends would require complex conditional logic throughout the code base. Different tenant metadata has vastly different access patterns. Routing to optimized backends alleviates both DynamoDB cost explosions (for rarely-changing configs) and Parameter Store throttling (for high-frequency reads), addressing the scaling gap. A naive implementation might look something like this and it’s worth pausing to understand why this approach breaks down.
Every time you add a new storage backend, say, AWS Secrets Manager or Amazon S3, you’re forced to reach back into this function and bolt on another else if. The storage logic becomes tightly coupled to your service layer, making it harder to test each backend in isolation and nearly impossible to swap one out without risking regressions elsewhere.
Implementation strategy
The Strategy Pattern encapsulates storage-specific logic into separate, interchangeable strategy classes. This code demonstrates how the factory examines keys and selects strategies:
Key prefix mapping:
tenant_config_* → Routes to Amazon DynamoDB for tenant-specific, high-frequency access patternsparam_config_* → Routes to AWS Systems Manager Parameter Store for shared, hierarchical parameters
With this approach, adding a new storage backend requires only:
- Creating a new strategy class implementing the
ConfigStrategy interface
- Adding one line to the
keyStrategyMap with the new prefix and strategy
- No changes to existing strategies or calling code
This design helps protect technology investments. As requirements evolve and new AWS services become relevant, the system adapts without major rewrites.
Multi-layer caching strategy
Different configurations benefit from different caching approaches. The pattern implements different caching strategies optimized for each configuration type’s access patterns and business requirements:
- High-frequency tenant configurations (accessed thousands of times per minute) use application-level caching with short Time-To-Live (TTL) values. This significantly reduces database queries while maintaining reasonably fresh data.
- Shared parameters (accessed frequently but change rarely) use in-memory caching with event-driven invalidation. The cache only refreshes when EventBridge detects an actual change, alleviating unnecessary API calls.
Cache Security Considerations
The implementation uses a shared in-memory Map with tenant-prefixed keys (tenantId:serviceName:configKey). Cached values are configuration metadata (API endpoints, feature flags, thresholds), not sensitive data like credentials or PII. Sensitive values remain in Parameter Store with SecureString encryption and are retrieved on-demand, not cached. Even in edge cases, downstream access controls (JWT validation, DynamoDB composite keys) act as the final enforcement boundary.
For teams handling more sensitive configuration payloads, consider Amazon ElastiCache (Redis OSS) or Valkey with key-prefix isolation and encryption at rest/in transit, though this adds 1-3ms network latency versus sub-millisecond in-memory access.
C. Authentication and tenant isolation
Tenant isolation is enforced at multiple layers, starting with JWT-based authentication and custom authorization guards.
Cognito JWT validation flow:
- Client authenticates with Cognito and receives JWT token
- Request includes JWT in Authorization: Bearer {token} header
CognitoJwtGuard validates token signature against Cognito JSON Web Key Sets (JWKS) endpoint- Guard extracts
custom:tenantId claim and attaches to request context
TenantAccessGuard verifies user has access to requested tenant- Service layer uses validated
tenantId for data operations
This implementation demonstrates the secure approach to tenant context extraction:
Why this approach helps prevent unauthorized access:
Consider what happens if an unauthorized user tries to access another tenant’s configuration:
- User authenticates as Tenant A and receives JWT with
custom:tenantId: "tenant-a"
- User attempts to manipulate request to access Tenant B’s data
- The service extracts
tenantId from the JWT (still “tenant-a”), ignoring request parameters
- Query uses the JWT’s tenant ID, so user only sees Tenant A’s data
Advanced: Infrastructure-level credential isolation
The current design enforces tenant isolation at the application layer through JWT extraction and DynamoDB composite keys. The ECS task uses a shared IAM execution role, meaning tenant requests operate under the same AWS credentials. While this approach is sufficient for most multi-tenant applications, teams with stricter compliance requirements (HIPAA, PCI-DSS, FedRAMP) may need infrastructure-level isolation.
For enhanced isolation, consider implementing a Token Vending Machine (TVM) pattern with AWS Security Token Service (STS) to issue temporary, tenant-scoped IAM credentials. This provides infrastructure-level isolation with per-tenant AWS CloudTrail audit trails and principle of least privilege enforcement. However, TVM adds operational complexity (credential caching, STS API costs, token refresh logic) and latency (50-100ms per operation).
Consider this as a next step when compliance auditors require infrastructure-level separation rather than a baseline requirement.
This design helps prevent cross-tenant access attempts at the infrastructure level, addressing a common security issue.
D. Zero-downtime auto-refresh mechanism
Configuration updates in production systems present a classic operations challenge. This event-driven approach addresses the cache TTL trade-off entirely, configurations update in real-time without polling or staleness windows.
EventBridge integration flow:
1. Parameter Store Change
↓
2. EventBridge Rule (matches /config-service/* changes)
↓
3. Lambda Function (extracts tenantId from path)
↓
4. Service Discovery (AWS Cloud Map queries for healthy instances)
↓
5. gRPC Refresh Call (direct service-to-service invocation)
↓
6. In-Memory Cache Update (zero-downtime)
↓
7. Updated Configuration Active (no connection drops)
Key benefits:
- Zero downtime: No service restarts required. Connections remain active
- Reactive updates: Only triggers when changes occur (no wasteful polling)
- Cost efficient: Minimizes SSM API calls through caching and event-driven refresh
- Audit trail: EventBridge provides complete change history and monitoring
When to use this pattern?
The tagged storage pattern isn’t universally applicable. Like most architectural approaches, it has ideal use cases where the benefits significantly outweigh the implementation complexity. Consider this pattern when your application matches these characteristics:
- Multi-tenant SaaS requiring strict tenant isolation and regulatory compliance benefit significantly. The pattern’s infrastructure-level isolation through JWT claims and data model design provides security commitments that application-level isolation cannot match.
- Microservices architectures with complex configuration requirements across dozens of services find value in the centralized management and flexible storage routing.
- Organizations managing configurations across multiple storage backends and environments (dev, staging, production, DR) appreciate the hierarchical organization and path-based access control that Parameter Store provides, combined with DynamoDB’s performance for high-frequency access.
- High-throughput applications (1000+ requests/second) needing sub-millisecond response times use DynamoDB Accelerator (DAX) for in-memory caching. While DynamoDB offers excellent single-digit millisecond latency, DAX delivers microsecond read latency, typically 5-10x faster for cached data. This makes a substantial difference at scale.
- Teams prioritizing operational simplicity value the event-driven refresh mechanism that avoids manual deployment coordination.
Getting started
Ready to implement the Tagged Storage Pattern in your organization?
Start with a pilot project focusing on a single microservice and gradually expand the pattern across your architecture. The modular design means that you can realize benefits incrementally while building confidence in the approach.
Implementation steps:
- Design your data model: Define DynamoDB schema and Parameter Store hierarchy
- Set up Amazon Cognito: Configure user pool with custom tenant attributes
- Build the service layer: Implement Strategy Pattern for storage routing
- Add event-driven refresh: Configure EventBridge rules and Lambda function
- Test tenant isolation: Verify JWT validation and cross-tenant access deterrence
- Deploy and monitor: Establish CloudWatch dashboards and operational procedures
You can find the complete code for this solution, including AWS CloudFormation templates, deployment and testing scripts, in the GitHub – Configuration Management Service.
To avoid incurring ongoing charges, delete the resources you created during this walkthrough. For detailed cleanup instructions including step-by-step commands and verification steps, see the Infrastructure Cleanup Guide.
Conclusion
Building a multi-tenant configuration service requires careful consideration of storage patterns, security boundaries, and operational requirements. The tagged storage pattern demonstrated in this post provides a flexible, scalable foundation that addresses these challenges through:
- Intelligent storage routing: The Strategy Pattern provides optimal backend selection per configuration type, allowing DynamoDB for tenant-specific settings and SSM Parameter Store for shared parameters.
- Zero-downtime updates: Event-driven architecture through EventBridge and Lambda avoids service restarts and polling overhead so that configurations refresh immediately upon changes.
- Strong tenant isolation: JWT-based authentication with custom claims makes sure tenant boundaries are enforced at the infrastructure level, not application logic, helping prevent cross-tenant access attempts.
- Operational simplicity: In-memory caching, combined with event-driven refresh, can reduce API costs while maintaining microsecond response times.
- Cost efficiency: Pay-per-request billing, aggressive caching, and Spot instances help keep operational costs minimal even at scale.
Additional resources
About the authors