AWS Architecture Blog
Category: Compute

Considerations for modernizing Microsoft SQL database service with high availability on AWS
Many organizations have applications that require Microsoft SQL Server to run relational database workloads: some applications can be proprietary software that the vendor mandates Microsoft SQL Server to run database service; the other applications can be long-standing, home-grown applications that included Microsoft SQL Server when they were initially developed. When organizations migrate applications to AWS, […]
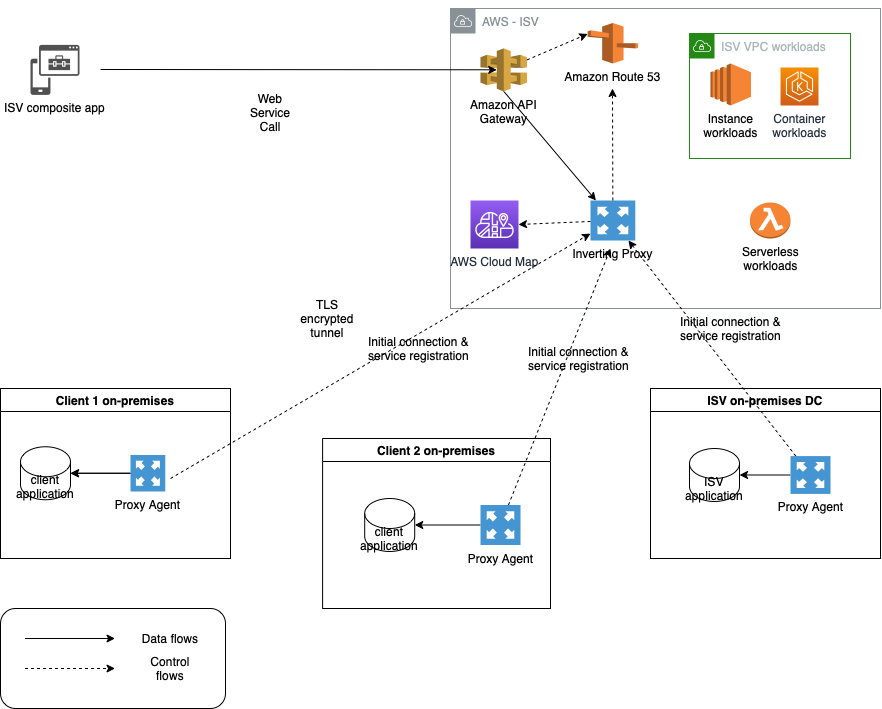
Implementing lightweight on-premises API connectivity using inverting traffic proxy
This post will explore the use of lightweight application inversion proxy as a solution for multi-point hybrid or multi-cloud, API-level connectivity for cases where AWS Direct Connect or VPN may not be practical. Then, we will present a sample solution and explain how it addresses typical challenges involved in this space. Defining the issue Large […]

Disaster recovery with AWS managed services, Part 2: Multi-Region/backup and restore
In part 1 of this series, we introduced a disaster recovery (DR) concept that uses managed services through a single AWS Region strategy. In part two, we introduce a multi-Region backup and restore approach. With this approach, you can deploy a DR solution in multiple Regions, but it will be associated with longer RPO/RTO. Using a […]

Modernization pathways for a legacy .NET Framework monolithic application on AWS
Organizations aim to deliver optimal technological solutions based on their customers’ needs. Although they may be at any stage in their cloud adoption journey, businesses often end up managing and building monolithic applications. However, there are many challenges to this solution. The internal structure of a monolithic application makes it difficult for developers to maintain code. […]

Use direct service integrations to optimize your architecture
When designing an application, you must integrate and combine several AWS services in the most optimized way for an effective and efficient architecture: Optimize for performance by reducing the latency between services Optimize for costs operability and sustainability, by avoiding unnecessary components and reducing workload footprint Optimize for resiliency by removing potential point of failures […]

Throttling a tiered, multi-tenant REST API at scale using API Gateway: Part 2
In Part 1 of this blog series, we demonstrated why tiering and throttling become necessary at scale for multi-tenant REST APIs, and explored tiering strategy and throttling with Amazon API Gateway. In this post, Part 2, we will examine tenant isolation strategies at scale with API Gateway and extend the sample code from Part 1. […]

Throttling a tiered, multi-tenant REST API at scale using API Gateway: Part 1
Many software-as-a-service (SaaS) providers adopt throttling as a common technique to protect a distributed system from spikes of inbound traffic that might compromise reliability, reduce throughput, or increase operational cost. Multi-tenant SaaS systems have an additional concern of fairness; excessive traffic from one tenant needs to be selectively throttled without impacting the experience of other […]

Let’s Architect! Serverless architecture on AWS
Serverless architecture and computing allow you and your teams to focus on delivering business value in place of investing time tweaking the infrastructure characteristics. AWS is not only providing serverless computing as a service, but share that half of our new applications built by Amazon are using AWS Lambda, as noted by Andy Jassy in […]
Let’s Architect! Using open-source technologies on AWS
With open-source technology, authors make software available to the public, who can view, use, or change it and add new features or support new capabilities. Open-source technology promotes collaboration across different teams, organizations, and people because the process often includes different perspectives and ideas, which typically results a stronger solution. It can be difficult to […]

Building a serverless cloud-native EDI solution with AWS
Electronic data interchange (EDI) is a technology that exchanges information between organizations in a structured digital form based on regulated message formats and standards. EDI has been used in healthcare for decades on the payer side for determination of coverage and benefits verification. There are different standards for exchanging electronic business documents, like American National […]