AWS Architecture Blog
Things to Consider When You Build a GraphQL API with AWS AppSync
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Co-authored by George Mao
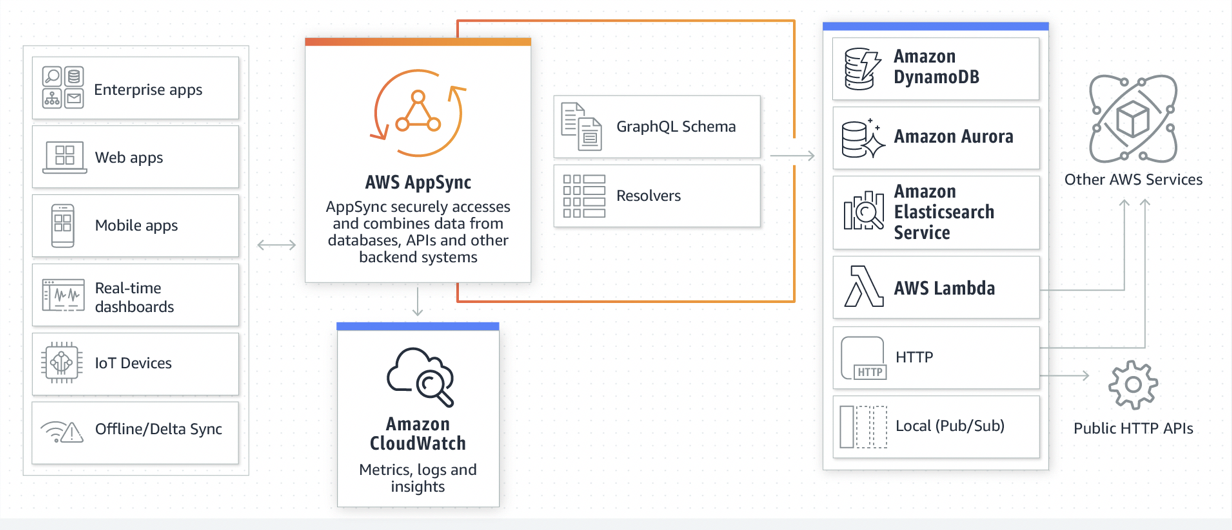
When building a serverless API layer in AWS (one that provides a custom grammar for your serverless resources), your choices include Amazon API Gateway (REST) and AWS AppSync (GraphQL). We’ve discussed the differences between REST and GraphQL in our first post of this series and explored REST APIs in our second post. This post will dive deeper into GraphQL implementation with AppSync.
Note that the GraphQL specification is focused on grammar and expected behavior, and is light on implementation details. Therefore, each GraphQL implementation approaches these details in a different way. While this blog post speaks to architectural principles, it will also discuss specific features AppSync for practical advice.
Schema vs. Resolver Complexity
All GraphQL APIs are defined by their schema. The schema contains operation definitions (Queries, Mutations, and Subscriptions), as well as data definitions (Data and Input Types). Since GraphQL tools provide introspection, your Schema also becomes your API documentation. So, as your Schema grows, it’s important that it’s consistent and adheres to best practices (such as the use of Input Types for mutations).
Clients will love using your API if they can do what they want with as little work as possible. A good rule of thumb is to put any necessary complexity in the resolver rather than in the client code. For example, if you know client applications will need “Book” information that includes the cover art and current sales ranking – all from different data sources – you can build a single data type that combines them:

In this case, the complexity associated with assembling that data should be handled in the resolver, rather than forcing the client code to make multiple calls and manipulate the returned data.
Mapping data storage to schema gets more complex when you are accessing legacy data services: internal APIs, external REST services, relational database SQL, and services with custom protocols or libraries. The other end of the spectrum is new development, where some architects argue they can map their entire schema to a single source. In practice, your mapping should consider the following:
- Should slower data sources have a caching layer?
- Do your most frequently used operations have low latency?
- How many layers (services) does a request touch?
- Can high latency requests be modeled asynchronously?
With AppSync, you have the option to use Pipeline Resolvers, which execute reusable functions within a resolver context. Each function in the pipeline can call one of the native resolver types.
Security
Public APIs (ones with an external endpoint) provide access to secured resources. The first line of defense is authorization – restricting who can call an operation in the GraphQL Schema. AppSync has four methods to authenticate clients:
- API keys: Since the API key does not reference an identity and is easily compromised, we recommend it be used for development only.
- IAMs: These are standard AWS credentials that are often used for server-side processes. A common example is assigning an execution role to a AWS Lambda function that makes calls to AppSync.
- OIDC Tokens: These are time-limited and suitable for external clients.
- Cognito User Pool Tokens: These provide the advantages of OIDC tokens, and also allow you to use the @auth transform for authorization.
Authorization in GraphQL is handled in the resolver logic, which allows field-level access to your data, depending on any criteria you can express in the resolver. This allows flexibility, but also introduces complexity in the form of code.
AppSync Resolvers use a Request/Response template pattern similar to API Gateway. Like API Gateway, the template language is Apache Velocity. In an AppSync resolver, you have the ability to examine the incoming authentication information (such as the IAM username) in the context variable. You can then compare that username against an owner field in the data being retrieved.
AppSync provides declarative security using the @auth and @model transforms. Transforms are annotations you add to your schema that are interpreted by the Amplify Toolchain. Using the @auth transform, you can apply different authentication types to different operations. AppSync will automatically generate resolver logic for DynamoDB, based on the data types in your schema. You can also define field-level permissions based on identity. Get detailed information.
Performance
To get a quantitative view of your API’s performance, you should enable field-level logging on your AppSync API. Doing so will automatically emit information into CloudWatch Logs. Then you can analyze AppSync performance with CloudWatch Logs Insights to identify performance bottlenecks and the root cause of operational problems, such as:
- Resolvers with the maximum latency
- The most (or least) frequently invoked resolvers
- Resolvers with the most errors
Remember, choice of resolver type has an impact on performance. When accessing your data sources, you should prefer a native resolver type such as Amazon DynamoDB or Amazon Elasticsearch using VTL templates. The HTTP resolver type is very efficient, but latency depends on the performance of the downstream service. Lambda resolvers provide flexibility, but have the performance characteristics of your application code.
AppSync also has another resolver type, the Local Resolver, which doesn’t interact with a data source. Instead, this resolver invokes a mutation operation that will result in a subscription message being sent. This is useful in use cases where AppSync is used as a message bus, or in cases where the data has been modified by an external source, and notifications must be sent without modifying the data a second time.
GraphQL Subscriptions
One of the reasons customers choose GraphQL is the power of Subscriptions. These are notifications that are sent immediately to clients when data has changed by a mutation. AppSync subscriptions are implemented using Websockets, and are directly tied to a mutation in the schema. The AppSync SDKs and AWS Amplify Library allow clients to subscribe to these real-time notifications.
AppSync Subscriptions have many uses outside standard API CRUD operations. They can be used for inter-client communication, such as a mobile or web chat application. Subscription notifications can also be used to provide asynchronous responses to long-running requests. The initial request returns quickly, while the full result can be sent via subscription when it’s complete (local resolvers are useful for this pattern).
Subscriptions will only be received if the client is currently running, connected to the server, and is subscribed to the target mutation. If you have a mobile client, you may want to augment these notifications with mobile or web push notifications.
Summary
The choice of using a GraphQL API brings many advantages, especially for client developers. While basic considerations of Security and Performance are important (as they are in any solution), GraphQL APIs require some thought and planning around Schema and Resolver organization, and managing their complexity.