AWS Big Data Blog
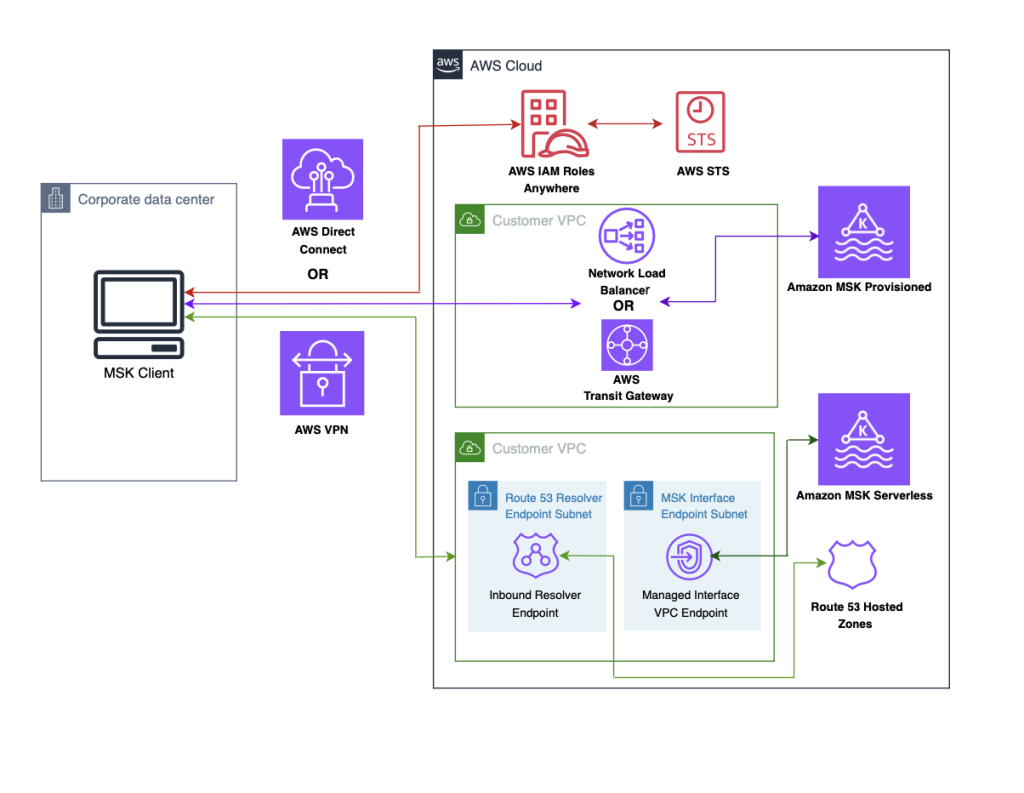
Securely connect Kafka clients running outside AWS to Amazon MSK with IAM Roles Anywhere
In this post, we demonstrate how to use AWS IAM Roles Anywhere to request temporary AWS security credentials, using x.509 certificates for client applications which enables secure interactions with an Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster. The solution described in this post is compatible with both Amazon MSK Provisioned and Serverless clusters.

Amazon Redshift DC2 migration approach with a customer case study
In this post, we share insights from one of our customers’ migration from DC2 to RA3 instances. The customer, a large enterprise in the retail industry, operated a 16-node dc2.8xlarge cluster for business intelligence (BI) and ETL workloads. Facing growing data volumes and disk capacity limitations, they successfully migrated to RA3 instances using a Blue-Green deployment approach, achieving improved ETL query performance and expanded storage capacity while maintaining cost efficiency.

Reducing costs for shuffle-heavy Apache Spark workloads with serverless storage for Amazon EMR Serverless
In this post, we explore the cost improvements we observed when benchmarking Apache Spark jobs with serverless storage on EMR Serverless. We take a deeper look at how serverless storage helps reduce costs for shuffle-heavy Spark workloads, and we outline practical guidance on identifying the types of queries that can benefit most from enabling serverless storage in your EMR Serverless Spark jobs.

Optimize HBase reads with bucket caching on Amazon EMR
In this post, we demonstrate how to improve HBase read performance by implementing bucket caching on Amazon EMR. Our tests reduced latency by 57.9% and improved throughput by 138.8%. This solution is particularly valuable for large-scale HBase deployments on Amazon S3 that need to optimize read performance while managing costs.

Kinesis On-demand Advantage saves 60%+ on streaming costs
On November 4, 2025, Amazon Kinesis Data Streams introduced On-demand Advantage mode, a capability that enables on-demand streams to handle instant throughput increases at scale and cost optimization for consistent streaming workloads. Historically, you had to choose between provisioned mode, which required managing stream capacity, and on-demand mode, which automatically scaled capacity, but this new offering removes the need to think about stream type at all. In this post, we show three real-world scenarios comparing different usage patterns and demonstrate how On-demand Advantage mode can optimize your streaming costs while maintaining performance and flexibility.

How Razorpay achieved 11% performance improvement and 21% cost reduction with Amazon EMR
In this post, we explore how Razorpay, India’s leading FinTech company, transformed their data platform by migrating from a third-party solution to Amazon EMR, unlocking improved performance and significant cost savings. We’ll walk through the architectural decisions that guided this migration, the implementation strategy, and the measurable benefits Razorpay achieved.

How Amplitude implemented natural language-powered analytics using Amazon OpenSearch Service as a vector database
Amplitude is a product and customer journey analytics platform. Our customers wanted to ask deep questions about their product usage. Ask Amplitude is an AI assistant that uses large language models (LLMs). It combines schema search and content search to provide a customized, accurate, low latency, natural language-based visualization experience to end customers. Amplitude’s search architecture evolved to scale, simplify, and cost-optimize for our customers, by implementing semantic search and Retrieval Augmented Generation (RAG) powered by Amazon OpenSearch Service. In this post, we walk you through Amplitude’s iterative architectural journey and explore how we address several critical challenges in building a scalable semantic search and analytics platform.
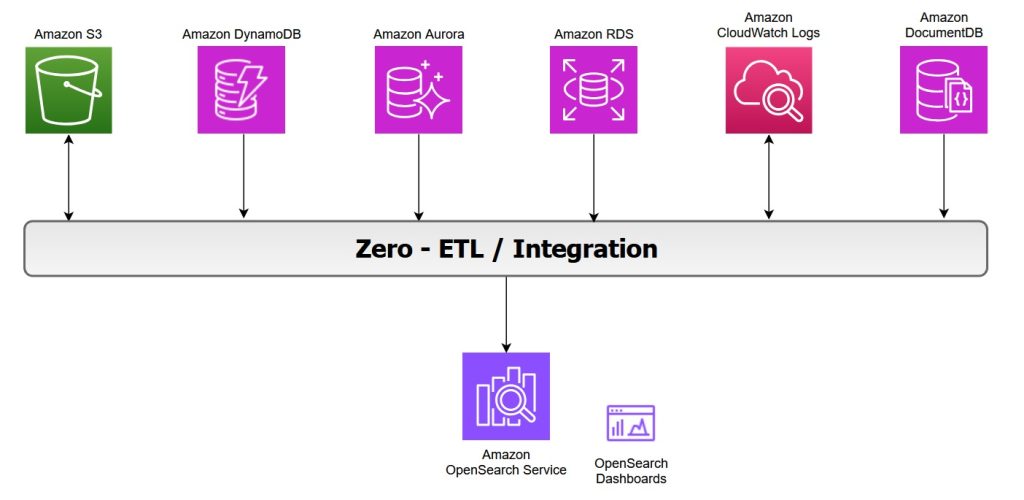
Zero-ETL integrations with Amazon OpenSearch Service
OpenSearch Service offers zero-ETL integrations with other Amazon Web Service (AWS) services, enabling seamless data access and analysis without the need for maintaining complex data pipelines. Zero-ETL refers to a set of integrations designed to minimize or eliminate the need to build traditional extract, transform, load (ETL) pipelines. In this post, we explore various zero-ETL integrations available with OpenSearch Service that can help you accelerate innovation and improve operational efficiency.
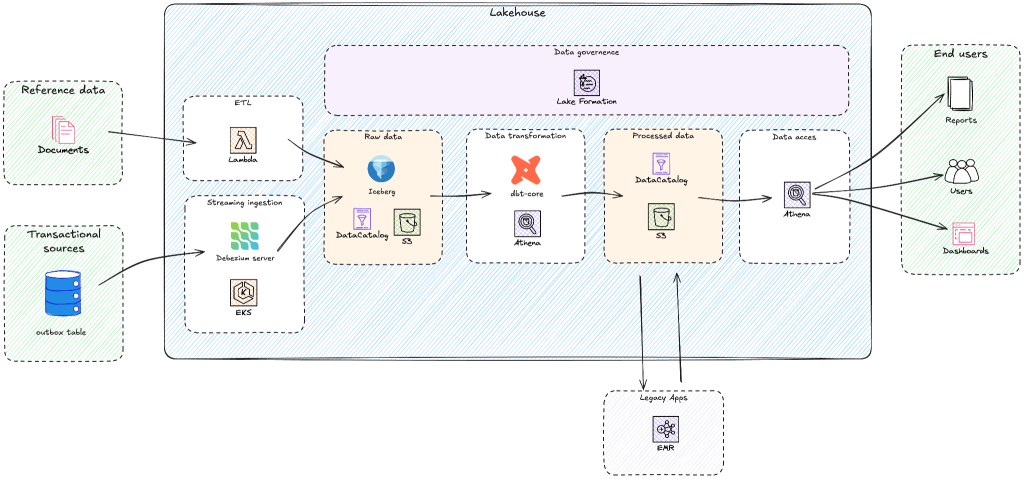
Building a modern lakehouse architecture: Yggdrasil Gaming’s journey from BigQuery to AWS
Yggdrasil Gaming develops and publishes casino games globally, processing massive amounts of real-time gaming data for game performance analytics, player behavior insights, and industry intelligence. Yggdrasil Gaming reduced multi-cloud complexity and built a scalable analytics foundation by migrating from Google BigQuery to AWS analytics services. In this post, you’ll discover how Yggdrasil Gaming transformed their data architecture to meet growing business demands. You will learn practical strategies for migrating from proprietary systems to open table formats such as Apache Iceberg while maintaining business continuity. Yggdrasil worked with GOStack, an AWS Partner, to migrate to an Apache Iceberg-based lakehouse architecture. The migration helped reduce operational complexity and enabled real-time gaming analytics and machine learning.

Set up production-ready monitoring for Amazon MSK using CloudWatch alarms
In this post, I show you how to implement effective monitoring for your Kafka clusters using Amazon MSK and Amazon CloudWatch. You’ll learn how to track critical metrics like broker health, resource utilization, and consumer lag, and set up automated alerts to prevent operational issues.