AWS Big Data Blog

Author: Muthu Pitchaimani
Muthu Pitchaimani is a Search Specialist. He helps build applications and solutions that need searching for large scale data. Muthu is based out of Austin, Texas.
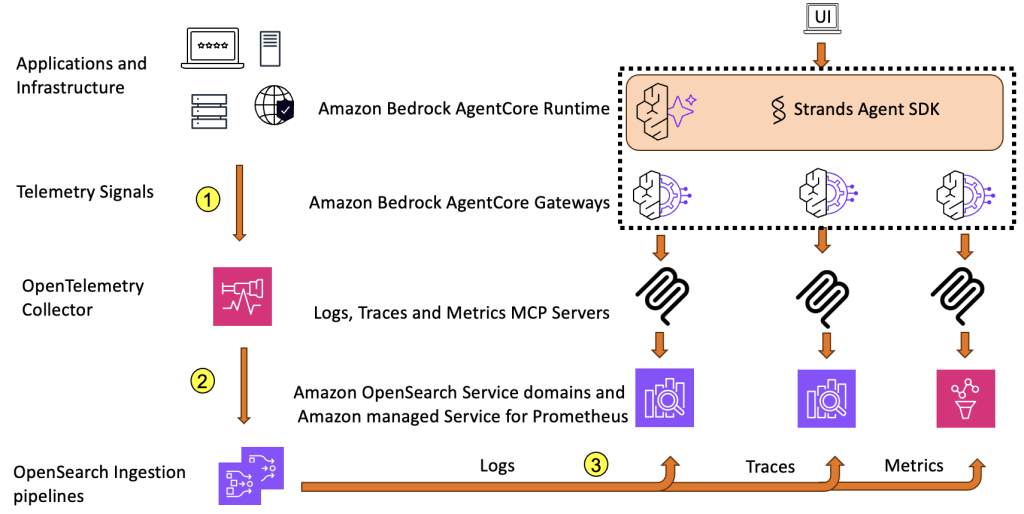
Reduce Mean Time to Resolution with an observability agent
In this post, we present an observability agent using OpenSearch Service and Amazon Bedrock AgentCore that can help surface root cause and get insights faster, handle multiple query-correlation cycles, and ultimately reduce MTTR even further.

Trusted identity propagation using IAM Identity Center for Amazon OpenSearch Service
Now, by using trusted identity propagation, IAM Identity Center provides a new, direct method for accessing data in OpenSearch Service. In this post, we outline how you can take advantage of this new access method to simplify data access using the OpenSearch UI and still maintain robust role-based access control for your OpenSearch data.

OpenSearch UI: Six months in review
OpenSearch UI has been adopted by thousands of customers for various use cases since its launch in November 2024. Exciting customer stories and feedback have helped shape our feature improvements. As we complete 6 months since its general availability, we are sharing major enhancements that have improved OpenSearch UI’s capability, especially in observability and security analytics, in this post.

Introducing Amazon Q Developer in Amazon OpenSearch Service
today we introduced Amazon Q Developer support in OpenSearch Service. With this AI-assisted analysis, both new and experienced users can navigate complex operational data without training, analyze issues, and gain insights in a fraction of the time. In this post, we share how to get started using Amazon Q Developer in OpenSearch Service and explore some of its key capabilities.

Achieve cross-Region resilience with Amazon OpenSearch Ingestion
In this post, we outline two solutions that provide cross-Region resiliency without needing to reestablish relationships during a failback, using an active-active replication model with Amazon OpenSearch Ingestion (OSI) and Amazon Simple Storage Service (Amazon S3). These solutions apply to both OpenSearch Service managed clusters and OpenSearch Serverless collections. We use OpenSearch Serverless as an example for the configurations in this post.

Introducing self-managed data sources for Amazon OpenSearch Ingestion
Enterprise customers increasingly adopt Amazon OpenSearch Ingestion (OSI) to bring data into Amazon OpenSearch Service for various use cases. These include petabyte-scale log analytics, real-time streaming, security analytics, and searching semi-structured key-value or document data. OSI makes it simple, with straightforward integrations, to ingest data from many AWS services, including Amazon DynamoDB, Amazon Simple Storage […]

Use Amazon OpenSearch Ingestion to migrate to Amazon OpenSearch Serverless
Amazon OpenSearch Serverless is an on-demand auto scaling configuration for Amazon OpenSearch Service. Since its release, the interest for OpenSearch Serverless had been steadily growing. Customers prefer to let the service manage its capacity automatically rather than having to manually provision capacity. Until now, customers have had to rely on using custom code or third-party […]

Introducing persistent buffering for Amazon OpenSearch Ingestion
Amazon OpenSearch Ingestion is a fully managed, serverless pipeline that delivers real-time log, metric, and trace data to Amazon OpenSearch Service domains and OpenSearch Serverless collections. Customers use Amazon OpenSearch Ingestion pipelines to ingest data from a variety of data sources, both pull-based and push-based. When ingesting data from pull-based sources, such as Amazon Simple […]

Introducing Amazon MSK as a source for Amazon OpenSearch Ingestion
Ingesting a high volume of streaming data has been a defining characteristic of operational analytics workloads with Amazon OpenSearch Service. Many of these workloads involve either self-managed Apache Kafka or Amazon Managed Streaming for Apache Kafka (Amazon MSK) to satisfy their data streaming needs. Consuming data from Amazon MSK and writing to OpenSearch Service has been a challenge for customers. AWS Lambda, custom code, Kafka Connect, and Logstash have been used for ingesting this data. These methods involve tools that must be built and maintained. In this post, we introduce Amazon MSK as a source to Amazon OpenSearch Ingestion, a serverless, fully managed, real-time data collector for OpenSearch Service that makes this ingestion even easier.

Generate security insights from Amazon Security Lake data using Amazon OpenSearch Ingestion
Amazon Security Lake centralizes access and management of your security data by aggregating security event logs from AWS environments, other cloud providers, on premise infrastructure, and other software as a service (SaaS) solutions. By converting logs and events using Open Cybersecurity Schema Framework, an open standard for storing security events in a common and shareable format, […]