September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Search engines provide the means to retrieve relevant content from a collection of content. However, this can be challenging if certain exact words aren’t entered. You need to find the right item from a catalog of products, or the correct provider from a list of service providers, for example. The most common method of specifying your query is through a text box. If you enter the wrong terms, you won’t match the right items, and won’t get the best results.
Synonyms enable better search results by matching words that all match to a single indexable term. In Amazon OpenSearch Service, you can provide synonyms for keywords that your application’s users may look for. For example, your website may provide medical practitioner searches, and your users may search for “child’s doctor” instead of “pediatrician.” Mapping the two words together enables either search term to match documents that contain the term “pediatrician.” You can achieve similar search results by using synonym files. Amazon OpenSearch Service custom packages allow you to upload synonym files that define the synonyms in your catalog. One best practice is to manage the synonyms in Amazon Relational Database Service (Amazon RDS). You then need to deploy the synonyms to your Amazon OpenSearch Service domain. You can do this with AWS Lambda and Amazon Simple Storage Service (Amazon S3).
In this post, we discuss an approach using Amazon Aurora and Lambda functions to automate updating synonym files for improved search results.
Overview of solution
Amazon OpenSearch Service is a fully managed service that makes it easy to deploy, secure, and run Elasticsearch cost-effectively and at scale. You can build, monitor, and troubleshoot your applications using the tools you love, at the scale you need. The service supports open-source Elasticsearch API operations, managed Kibana, integration with Logstash, and many AWS services with built-in alerting and SQL querying.
The following diagram shows the solution architecture. One Lambda function pushes files to Amazon S3, and another function distributes the updates to Amazon OpenSearch Service.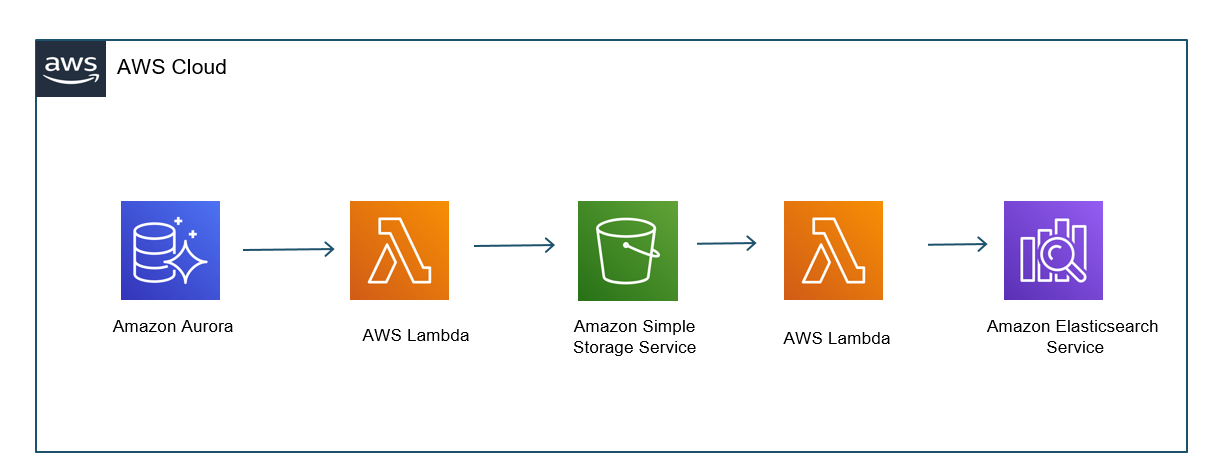
Walkthrough overview
For search engineers, the synonym file’s content is usually stored within a database or in a data lake. You may have data in tabular format in Amazon RDS (in this case, we use Amazon Aurora MySQL). When updates to the synonym data table occur, the change triggers a Lambda function that pushes data to Amazon S3. The S3 event triggers a second function, which pushes the synonym file from Amazon S3 to Amazon OpenSearch Service. This architecture automates the entire synonym file update process.
To achieve this architecture, we complete the following high-level steps:
- Create a stored procedure to trigger the Lambda function.
- Write a Lambda function to verify data changes and push them to Amazon S3.
- Write a Lambda function to update the synonym file in Amazon OpenSearch Service.
- Test the data flow.
We discuss each step in detail in the next sections.
Prerequisites
Make sure you complete the following prerequisites:
- Configure an Amazon OpenSearch Service domain. We use a domain running Elasticsearch version 7.9 for this architecture.
- Set up an Aurora MySQL database. For more information, see Configuring your Amazon Aurora DB cluster.
Create a stored procedure to trigger a Lambda function
You can invoke a Lambda function from an Aurora MySQL database cluster using a native function or a stored procedure.
The following script creates an example synonym data table:
CREATE TABLE SynonymsTable (
SynID int NOT NULL AUTO_INCREMENT,
Base_Term varchar(255),
Synonym_1 varchar(255),
Synonym_2 varchar(255),
PRIMARY KEY (SynID)
)
You can now populate the table with sample data. To generate sample data in your table, run the following script:
INSERT INTO SynonymsTable(Base_Term, Synonym_1, Synonym_2)
VALUES ( 'danish', 'croissant', 'pastry')
Create a Lambda function
You can use two different methods to send data from Aurora to Amazon S3: a Lambda function or SELECT INTO OUTFILE S3.
To demonstrate the ease of setting up integration between multiple AWS services, we use a Lambda function that is called every time a change occurs that must be tracked in the database table. This function passes the data to Amazon S3. First create an S3 bucket where you store the synonym file using the Lambda function.
When you create your function, make sure you give the right permissions using an AWS Identity and Access Management (IAM) role for the S3 bucket. These permissions are for the Lambda execution role and S3 bucket where you store the synonyms.txt file. By default, Lambda creates an execution role with minimal permissions when you create a function on the Lambda console. The following is the Python code to create the synonyms.txt file in S3:
import boto3
import json
import botocore
from botocore.exceptions import ClientError
s3_resource = boto3.resource('s3')
filename = 'synonyms.txt'
BucketName = '<<provide your bucket name>>
local_file = '/tmp/test.txt'
def lambda_handler(event, context):
S3_data = (("%s,%s,%s \n") %(event['Base_Term'], event['Synonym_1'], event['Synonym_2']))
# open a file and append new line
try:
obj=s3_resource.Bucket(BucketName).download_file(local_file,filename)
except ClientError as e:
if e.response['Error']['Code'] == "404":
# create a new file if file does not exits
s3_resource.meta.client.put_object(Body=S3_data, Bucket= BucketName,Key=filename)
else:
# append file
raise
with open('/tmp/test.txt', 'a') as fd:
fd.write(S3_data)
s3_resource.meta.client.upload_file('/tmp/test.txt', BucketName, filename)
Note the Amazon Resource Name (ARN) of this Lambda function to use in a later step.
Give Aurora permissions to invoke a Lambda function
To give Aurora permissions to invoke your function, you must attach an IAM role with the appropriate permissions to the cluster. For more information, see Invoking a Lambda function from an Amazon Aurora DB cluster.
When you’re finished, the Aurora database has access to invoke a Lambda function.
Create a stored procedure and a trigger in Aurora
To create a new stored procedure, return to MySQL Workbench. Change the ARN in the following code to your Lambda function’s ARN before running the procedure:
DROP PROCEDURE IF EXISTS Syn_TO_S3;
DELIMITER ;;
CREATE PROCEDURE Syn_TO_S3 (IN SysID INT,IN Base_Term varchar(255),IN Synonym_1 varchar(255),IN Synonym_2 varchar(255)) LANGUAGE SQL
BEGIN
CALL mysql.lambda_async('<<Lambda-Funtion-ARN>>,
CONCAT('{ "SysID ": "', SysID,
'", "Base_Term" : "', Base_Term,
'", "Synonym_1" : "', Synonym_1,
'", "Synonym_2" : "', Synonym_2,'"}')
);
END
;;
DELIMITER
When this stored procedure is called, it invokes the Lambda function you created.
Create a trigger TR_SynonymTable_CDC on the table SynonymTable. When a new record is inserted, this trigger calls the Syn_TO_S3 stored procedure. See the following code:
DROP TRIGGER IF EXISTS TR_Synonym_CDC;
DELIMITER ;;
CREATE TRIGGER TR_Synonym_CDC
AFTER INSERT ON SynonymsTable
FOR EACH ROW
BEGIN
SELECT NEW.SynID, NEW.Base_Term, New.Synonym_1, New.Synonym_2
INTO @SynID, @Base_Term, @Synonym_1, @Synonym_2;
CALL Syn_TO_S3(@SynID, @Base_Term, @Synonym_1, @Synonym_2);
END
;;
DELIMITER ;
If a new row is inserted in SynonymsTable, the Lambda function that is mentioned in the stored procedure is invoked.
Verify that data is being sent from the function to Amazon S3 successfully. You may have to insert a few records, depending on the size of your data, before new records appear in Amazon S3.
Update synonyms in Amazon OpenSearch Service when a new synonym file becomes available
Amazon OpenSearch Service lets you upload custom dictionary files (for example, stopwords and synonyms) for use with your cluster. The generic term for these types of files is packages. Before you can associate a package with your domain, you must upload it to an S3 bucket. For instructions on uploading a synonym file for the first time and associating it to an Amazon OpenSearch Service domain, see Uploading packages to Amazon S3 and Importing and Associating packages.
To update the synonyms (package) when a new version of the synonym file becomes available, we complete the following steps:
- Create a Lambda function to update the existing package.
- Set up an S3 event notification to trigger the function.
Create a Lambda function to update the existing package
We use a Python-based Lambda function that uses the Boto3 AWS SDK for updating the Elasticsearch package. For more information about how to create a Python-based Lambda function, see Building Lambda functions with Python. You need the following information before we start coding for the function:
- The S3 bucket ARN where the new synonym file is written
- The Amazon OpenSearch Service domain name (available on the Amazon OpenSearch Service console)

- The package ID of the Elasticsearch package we’re updating (available on the Amazon OpenSearch Service console)

You can use the following code for the Lambda function:
import logging
import boto3
import os
# Elasticsearch client
client = boto3.client('es')
# set up logging
logger = logging.getLogger('boto3')
logger.setLevel(logging.INFO)
# fetch from Environment Variable
package_id = os.environ['PACKAGE_ID']
es_domain_nm = os.environ['ES_DOMAIN_NAME']
def lambda_handler(event, context):
s3_bucket = event["Records"][0]["s3"]["bucket"]["name"]
s3_key = event["Records"][0]["s3"]["object"]["key"]
logger.info("bucket: {}, key: {}".format(s3_bucket, s3_key))
# update package with the new Synonym file.
up_response = client.update_package(
PackageID=package_id,
PackageSource={
'S3BucketName': s3_bucket,
'S3Key': s3_key
},
CommitMessage='New Version: ' + s3_key
)
logger.info('Response from Update_Package: {}'.format(up_response))
# check if the package update is completed
finished = False
while finished == False:
# describe the package by ID
desc_response = client.describe_packages(
Filters=[{
'Name': 'PackageID',
'Value': [package_id]
}],
MaxResults=1
)
status = desc_response['PackageDetailsList'][0]['PackageStatus']
logger.info('Package Status: {}'.format(status))
# check if the Package status is back to available or not.
if status == 'AVAILABLE':
finished = True
logger.info('Package status is now Available. Exiting loop.')
else:
finished = False
logger.info('Package: {} update is now Complete. Proceed to Associating to ES Domain'.format(package_id))
# once the package update is completed, re-associate with the ES domain
# so that the new version is applied to the nodes.
ap_response = client.associate_package(
PackageID=package_id,
DomainName=es_domain_nm
)
logger.info('Response from Associate_Package: {}'.format(ap_response))
return {
'statusCode': 200,
'body': 'Custom Package Updated.'
}
The preceding code requires environment variables to be set to the appropriate values and the IAM execution role assigned to the Lambda function.
Set up an S3 event notification to trigger the Lambda function
Now we set up event notification (all object create events) for the S3 bucket in which the updated synonym file is uploaded. For more information about how to set up S3 event notifications with Lambda, see Using AWS Lambda with Amazon S3.
Test the solution
To test our solution, let’s consider an Elasticsearch index (es-blog-index-01) that consists of the following documents:
tennis shoehightopcroissantice cream
A synonym file is already associated with the Amazon OpenSearch Service domain via Amazon OpenSearch Service custom packages and the index (es-blog-index-01) has the synonym file in the settings (analyzer, filter, mappings). For more information about how to associate a file to an Amazon OpenSearch Service domain and use it with the index settings, see Importing and associating packages and Using custom packages with Elasticsearch. The synonym file contains the following data:
danish, croissant, pastry
Test 1: Search with a word present in the synonym file
For our first search, we use a word that is present in the synonym file. The following screenshot shows that searching for “danish” brings up the document croissant based on a synonym match.

Test 2: Search with a synonym not present in the synonym file
Next, we search using a synonym that’s not in the synonym file. In the following screenshot, our search for “gelato” yields no result. The word “gelato” doesn’t match with the document ice cream because no synonym mapping is present for it.

In the next test, we add synonyms for “ice cream” and perform the search again.
Test 3: Add synonyms for “ice cream” and redo the search
To add the synonyms, let’s insert a new record into our database. We can use the following SQL statement:
INSERT INTO SynonymsTable(Base_Term, Synonym_1, Synonym_2)
VALUES ('frozen custard', 'gelato', 'ice cream')
When we search with the word “gelato” again, we get the ice cream document.

This confirms that the synonym addition is applied to the Amazon OpenSearch Service index.
Clean up resources
To avoid ongoing charges to your AWS account, remove the resources you created:
- Delete the Amazon OpenSearch Service domain.
- Delete the RDS DB instance.
- Delete the S3 bucket.
- Delete the Lambda functions.
Conclusion
In this post, we implemented a solution using Aurora, Lambda, Amazon S3, and Amazon OpenSearch Service that enables you to update synonyms automatically in Amazon OpenSearch Service. This provides central management for synonyms and ensures your users can obtain accurate search results when synonyms are changed in your source database.
About the Authors
 Ashwini Rudra is a Solutions Architect at AWS. He has more than 10 years of experience architecting Windows workloads in on-premises and cloud environments. He is also an AI/ML enthusiast. He helps AWS customers, namely major sports leagues, define their cloud-first digital innovation strategy.
Ashwini Rudra is a Solutions Architect at AWS. He has more than 10 years of experience architecting Windows workloads in on-premises and cloud environments. He is also an AI/ML enthusiast. He helps AWS customers, namely major sports leagues, define their cloud-first digital innovation strategy.
 Arnab Ghosh is a Solutions Architect for AWS in North America helping enterprise customers build resilient and cost-efficient architectures. He has over 13 years of experience in architecting, designing, and developing enterprise applications solving complex business problems.
Arnab Ghosh is a Solutions Architect for AWS in North America helping enterprise customers build resilient and cost-efficient architectures. He has over 13 years of experience in architecting, designing, and developing enterprise applications solving complex business problems.
 Jennifer Ng is an AWS Solutions Architect working with enterprise customers to understand their business requirements and provide solutions that align with their objectives. Her background is in enterprise architecture and web infrastructure, where she has held various implementation and architect roles in the financial services industry.
Jennifer Ng is an AWS Solutions Architect working with enterprise customers to understand their business requirements and provide solutions that align with their objectives. Her background is in enterprise architecture and web infrastructure, where she has held various implementation and architect roles in the financial services industry.