AWS Big Data Blog
Category: Amazon EMR on EKS

Use Karpenter to speed up Amazon EMR on EKS autoscaling
Amazon EMR on Amazon EKS is a deployment option for Amazon EMR that allows organizations to run Apache Spark on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, the Spark jobs run on the Amazon EMR runtime for Apache Spark. This increases the performance of your Spark jobs so that they run faster […]

Get a quick start with Apache Hudi, Apache Iceberg, and Delta Lake with Amazon EMR on EKS
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can keep your data as is in your object store or file-based storage without having to first structure the data. Additionally, you can run different types of analytics against your loosely formatted data […]

Design considerations for Amazon EMR on EKS in a multi-tenant Amazon EKS environment
Many AWS customers use Amazon Elastic Kubernetes Service (Amazon EKS) in order to take advantage of Kubernetes without the burden of managing the Kubernetes control plane. With Kubernetes, you can centrally manage your workloads and offer administrators a multi-tenant environment where they can create, update, scale, and secure workloads using a single API. Kubernetes also […]
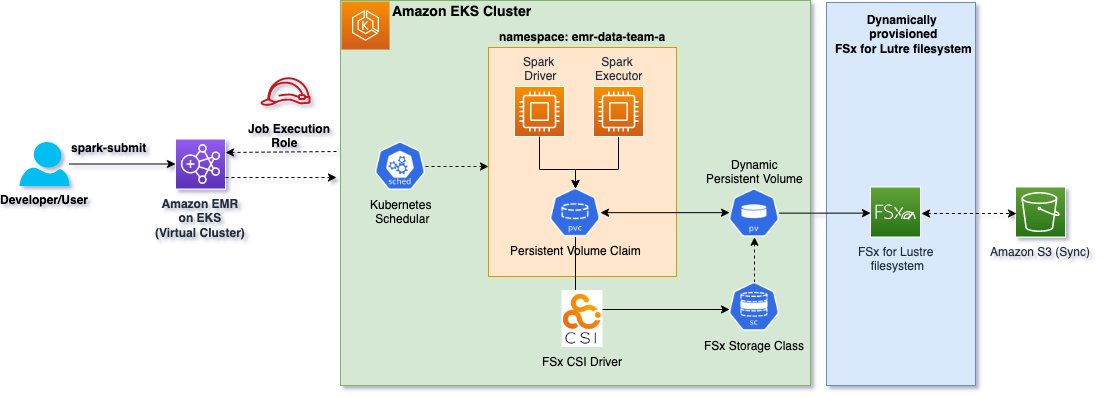
Run Apache Spark with Amazon EMR on EKS backed by Amazon FSx for Lustre storage
September 2023: This post was reviewed and updated for accuracy to reflect recent improvements and changes. Traditionally, Spark workloads have been run on a dedicated setup like a Hadoop stack with YARN or MESOS as a resource manager. Starting from Apache Spark 2.3, Spark added support for Kubernetes as a resource manager. The new Kubernetes […]

Removing complexity to improve business performance: How Bridgewater Associates built a scalable, secure, Spark-based research service on AWS
This is a guest post co-written by Sergei Dubinin, Oleksandr Ierenkov, Illia Popov and Joel Thompson, from Bridgewater. Bridgewater’s core mission is to understand how the world works by analyzing the drivers of markets and turning that understanding into high-quality portfolios and investment advice for our clients. Within Bridgewater Technology, we strive to make our […]
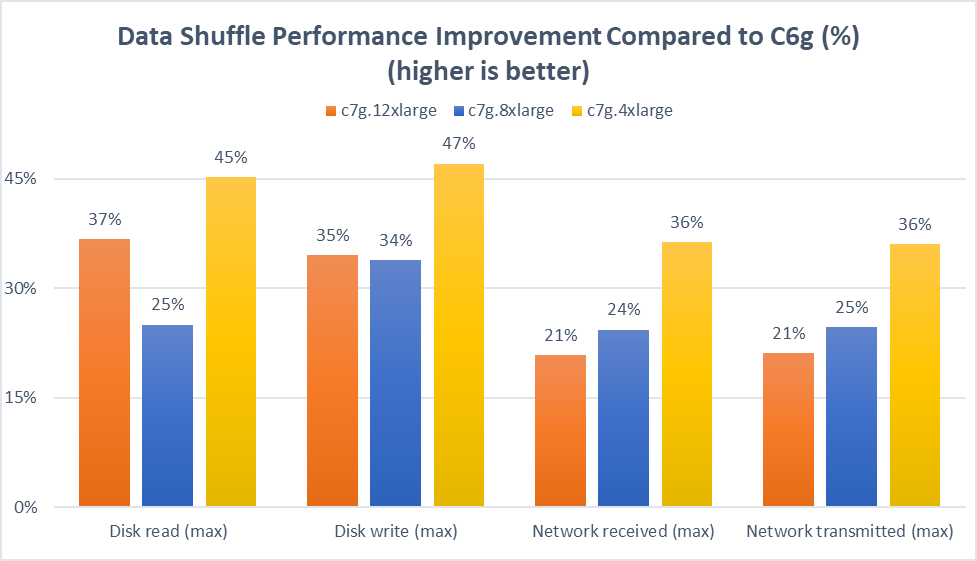
Amazon EMR on EKS gets up to 19% performance boost running on AWS Graviton3 Processors vs. Graviton2
Amazon EMR on EKS is a deployment option that enables you to run Spark workloads on Amazon Elastic Kubernetes Service (Amazon EKS) easily. It allows you to innovate faster with the latest Apache Spark on Kubernetes architecture while benefiting from the performance-optimized Spark runtime powered by Amazon EMR. This deployment option elects Amazon EKS as […]
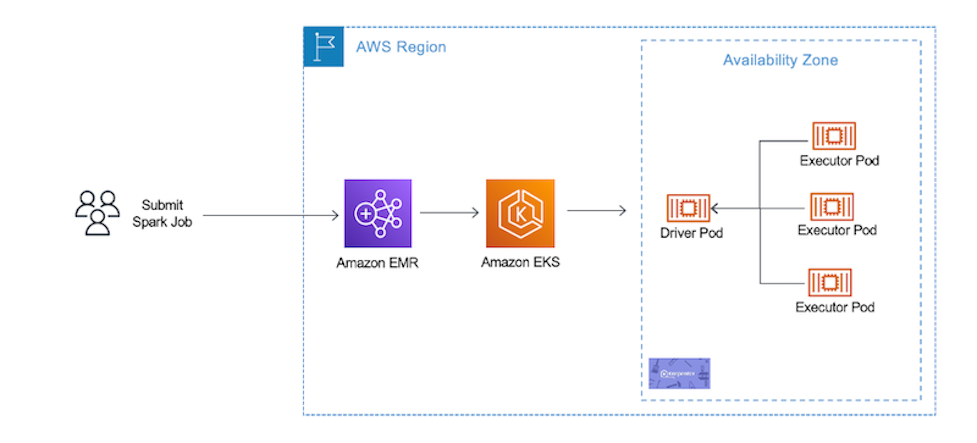
Design patterns to manage Amazon EMR on EKS workloads for Apache Spark
Amazon EMR on Amazon EKS enables you to submit Apache Spark jobs on demand on Amazon Elastic Kubernetes Service (Amazon EKS) without provisioning clusters. With EMR on EKS, you can consolidate analytical workloads with your other Kubernetes-based applications on the same Amazon EKS cluster to improve resource utilization and simplify infrastructure management. Kubernetes uses namespaces to provide isolation between […]

Stream Amazon EMR on EKS logs to third-party providers like Splunk, Amazon OpenSearch Service, or other log aggregators
Spark jobs running on Amazon EMR on EKS generate logs that are very useful in identifying issues with Spark processes and also as a way to see Spark outputs. You can access these logs from a variety of sources. On the Amazon EMR virtual cluster console, you can access logs from the Spark History UI. […]

Amazon EMR on Amazon EKS provides up to 61% lower costs and up to 68% performance improvement for Spark workloads
Amazon EMR on Amazon EKS is a deployment option offered by Amazon EMR that enables you to run Apache Spark applications on Amazon Elastic Kubernetes Service (Amazon EKS) in a cost-effective manner. It uses the EMR runtime for Apache Spark to increase performance so that your jobs run faster and cost less. In our benchmark […]

How SailPoint solved scaling issues by migrating legacy big data applications to Amazon EMR on Amazon EKS
This post is co-written with Richard Li from SailPoint. SailPoint Technologies is an identity security company based in Austin, TX. Its software as a service (SaaS) solutions support identity governance operations in regulated industries such as healthcare, government, and higher education. SailPoint distinguishes multiple aspects of identity as individual identity security services, including cloud governance, […]