AWS Big Data Blog
Category: Amazon EMR on EKS

Amazon EMR on Amazon EKS provides up to 61% lower costs and up to 68% performance improvement for Spark workloads
Amazon EMR on Amazon EKS is a deployment option offered by Amazon EMR that enables you to run Apache Spark applications on Amazon Elastic Kubernetes Service (Amazon EKS) in a cost-effective manner. It uses the EMR runtime for Apache Spark to increase performance so that your jobs run faster and cost less. In our benchmark […]

How SailPoint solved scaling issues by migrating legacy big data applications to Amazon EMR on Amazon EKS
This post is co-written with Richard Li from SailPoint. SailPoint Technologies is an identity security company based in Austin, TX. Its software as a service (SaaS) solutions support identity governance operations in regulated industries such as healthcare, government, and higher education. SailPoint distinguishes multiple aspects of identity as individual identity security services, including cloud governance, […]
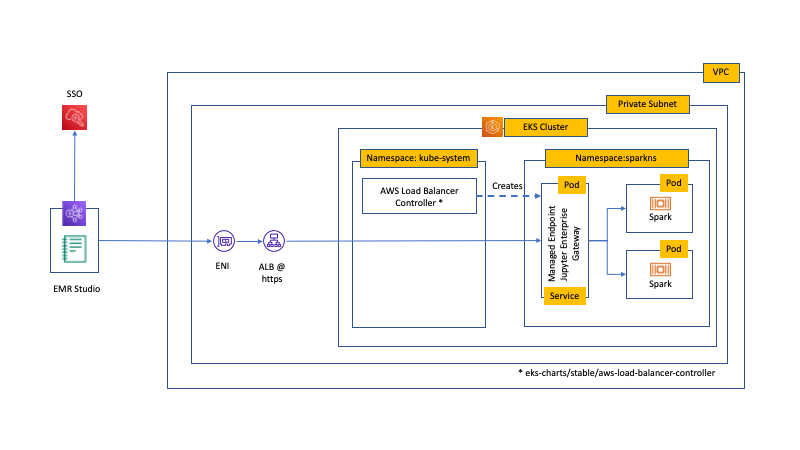
Configure Amazon EMR Studio and Amazon EKS to run notebooks with Amazon EMR on EKS
Amazon EMR on Amazon EKS provides a deployment option for Amazon EMR that allows you to run analytics workloads on Amazon Elastic Kubernetes Service (Amazon EKS). This is an attractive option because it allows you to run applications on a common pool of resources without having to provision infrastructure. In addition, you can use Amazon […]

Reduce costs and increase resource utilization of Apache Spark jobs on Kubernetes with Amazon EMR on Amazon EKS
Amazon EMR on Amazon EKS is a deployment option for Amazon EMR that allows you to run Apache Spark on Amazon Elastic Kubernetes Service (Amazon EKS). If you run open-source Apache Spark on Amazon EKS, you can now use Amazon EMR to automate provisioning and management, and run Apache Spark up to three times faster. […]

Run and debug Apache Spark applications on AWS with Amazon EMR on Amazon EKS
Customers today want to focus more on their core business model and less on the underlying infrastructure and operational burden. As customers migrate to the AWS Cloud, they’re realizing the benefits of being able to innovate faster on their own applications by relying on AWS to handle big data platforms, operations, and automation. Many of […]

Run a Spark SQL-based ETL pipeline with Amazon EMR on Amazon EKS
Increasingly, a business’s success depends on its agility in transforming data into actionable insights, which requires efficient and automated data processes. In the previous post – Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS, we described a common productivity issue in a modern data architecture. To address the challenge, we demonstrated how to utilize a declarative approach as the key enabler to improve efficiency, which resulted in a faster time to value for businesses. Generally speaking, managing applications declaratively in Kubernetes is a widely adopted best practice. You can use the same approach to build and deploy Spark applications with open-source or in-house build frameworks to achieve the same productivity goal.

Manage and process your big data workflows with Amazon MWAA and Amazon EMR on Amazon EKS
Many customers are gathering large amount of data, generated from different sources such as IoT devices, clickstream events from websites, and more. To efficiently extract insights from the data, you have to perform various transformations and apply different business logic on your data. These processes require complex workflow management to schedule jobs and manage dependencies […]

Orchestrate an Amazon EMR on Amazon EKS Spark job with AWS Step Functions
At re:Invent 2020, we announced the general availability of Amazon EMR on Amazon EKS, a new deployment option for Amazon EMR that allows you to automate the provisioning and management of open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With Amazon EMR on EKS, you can now run Spark applications alongside other […]