AWS Big Data Blog
Run a Spark SQL-based ETL pipeline with Amazon EMR on Amazon EKS
| This blog post has been translated into the following languages: |
Increasingly, a business’s success depends on its agility in transforming data into actionable insights, which requires efficient and automated data processes. In the previous post – Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS, we described a common productivity issue in a modern data architecture. To address the challenge, we demonstrated how to utilize a declarative approach as the key enabler to improve efficiency, which resulted in a faster time to value for businesses.
Generally speaking, managing applications declaratively in Kubernetes is a widely adopted best practice. You can use the same approach to build and deploy Spark applications with open-source or in-house build frameworks to achieve the same productivity goal.
For this post, we use the open-source data processing framework Arc, which is abstracted away from Apache Spark, to transform a regular data pipeline to an “extract, transform, and load (ETL) as definition” job. The steps in the data pipeline are simply expressed in a declarative definition (JSON) file with embedded declarative language SQL scripts.
The job definition in an Arc Jupyter notebook looks like the following screenshot.

This representation makes ETL much easier for a wider range of personas: analysts, data scientists, and any SQL authors who can fully express their data workflows without the need to write code in a programming language like Python.
In this post, we explore some key advantages of the latest Amazon EMR deployment option Amazon EMR on Amazon EKS to run Spark applications. We also explain its major difference from the commonly used Spark resource manager YARN, and demonstrate how to schedule a declarative ETL job with EMR on EKS. Building and testing the job on a custom Arc Jupyter kernel is out of scope for this post. You can find more tutorials on the Arc website.
Why choose Amazon EMR on Amazon EKS?
The following are some of the benefits of EMR on EKS:
- Simplified architecture by unifying workloads – EMR on EKS enables us to run Apache Spark workloads on Amazon Elastic Kubernetes Service (Amazon EKS) without provisioning dedicated EMR clusters. If you have an existing Amazon EKS landscape in your organization, it makes sense to unify analytical workloads with other Kubernetes-based applications on the same Amazon EKS cluster. It improves resource utilization and significantly simplifies your infrastructure management.
- More resources to share with a smaller JVM footprint – A major difference in this deployment option is the resource manager shift from YARN to Kubernetes and from a Hadoop cluster manager to a generic containerized application orchestrator. As shown in the following diagram, each Spark executor runs as a YARN container (compute and memory unit) in Hadoop. Broadly, YARN creates a JVM in each container requested by Hadoop applications, such as Apache Hive. When you run Spark on Kubernetes, it keeps your JVM footprint minimal, so that the Amazon EKS cluster can accommodate more applications, resulting in more spare resources for your analytical workloads.

- Efficient resource sharing and cost savings – With the YARN cluster manager, if you want to reuse the same EMR cluster for concurrent Spark jobs to reduce cost, you have to compromise on resource isolation. Additionally, you have to pay for compute resources that aren’t fully utilized, such as a master node, because only Amazon EMR can use these unused compute resources. With EMR on EKS, you can enjoy the optimized resource allocation feature by sharing them across all your applications, which reduces cost.
- Faster EMR runtime for Apache Spark – One of the key benefits of running Spark with EMR on EKS is the faster EMR runtime for Apache Spark. The runtime is a performance-optimized environment, which is available and turned on by default on Amazon EMR release 5.28.0 and later. In our performance tests using TPC-DS benchmark queries at 3 TB scale, we found EMR runtime for Apache Spark 3.0 provides a 1.7 times performance improvement on average, and up to 8 times improved performance for individual queries over open-source Apache Spark 3.0.0. It means you can run your Apache Spark applications faster and cheaper without requiring any changes to your applications.
- Minimum setup to support multi-tenancy – While taking advantage of Spark’s Dynamic Resource Allocation, auto scaling in Amazon EKS, high availability with multiple Availability Zones, you can isolate your workloads for multi-tenancy use cases, with a minimum configuration required. Additionally, without any infrastructure setup, you can use an Amazon EKS cluster to run a single application that requires different Apache Spark versions and configurations, for example for development vs test environments.
Cost effectiveness
EMR on EKS pricing is calculated based on the vCPU and memory resources used from the time you start to download your Amazon EMR application image until the Spark pod on Amazon EKS stops, rounded up to the nearest second. The following screenshot is an example of the cost in the us-east-1 Region.
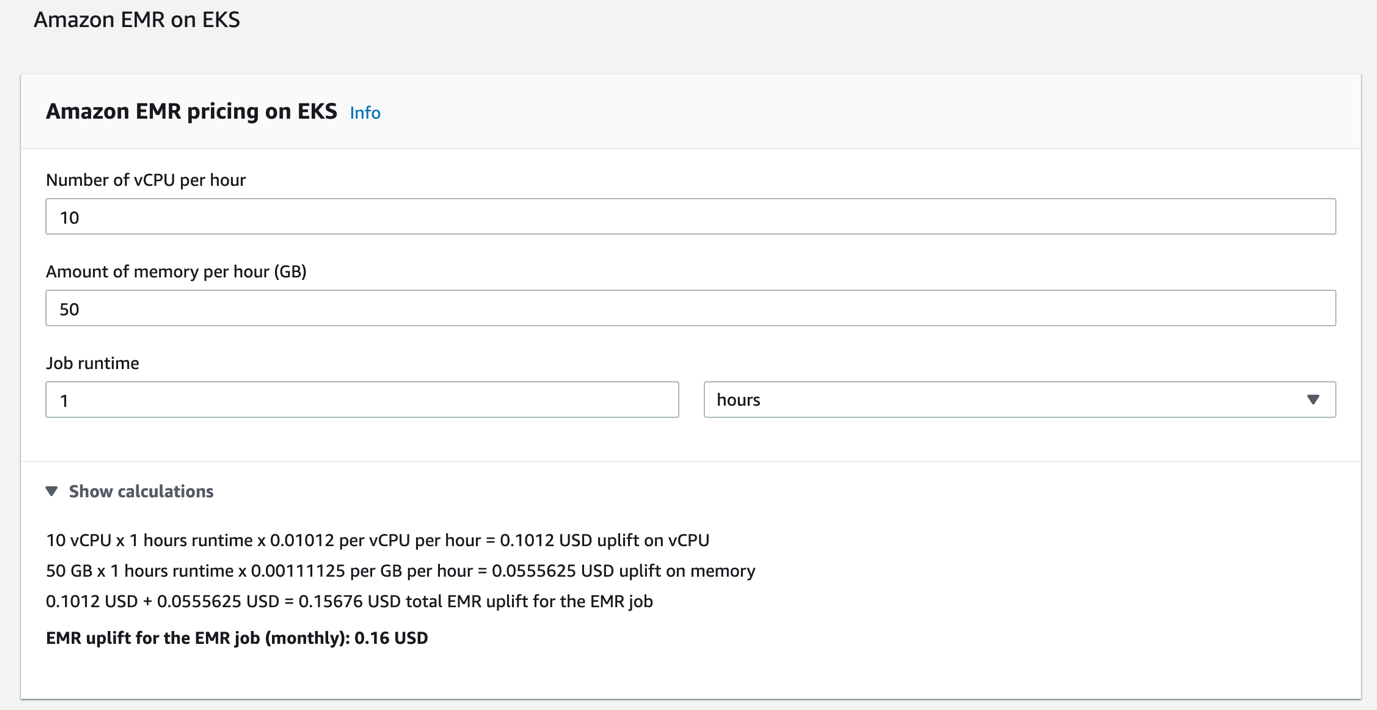
The Amazon EMR uplift price is in addition to the Amazon EKS pricing and any other services used by Amazon EKS, such as EC2 instances and EBS volumes. You pay $0.10 per hour for each Amazon EKS cluster that you use. However, you can use a single Amazon EKS cluster to run multiple applications by taking advantage of Kubernetes namespaces and AWS Identity and Access Management (IAM) security policies.
While the application runs, your resources are allocated and removed automatically by the Amazon EKS auto scaling feature, in order to eliminate over-provisioning or under-utilization of these resources. It enables you to lower costs because you only pay for the resources you use.
To further reduce the running cost for jobs that aren’t time-critical, you can schedule Spark executors on Spot Instances to save up to 90% over On-Demand prices. In order to maintain the resiliency of your Spark cluster, it is recommended to run driver on a reliable On-Demand Instance, because the driver is responsible for requesting new executors to replace failed ones when an unexpected event happens.
Kubernetes comes with a YAML specification called a pod template that can help you to assign Spark driver and executor pods to Spot or On-Demand EC2 instances. You define nodeSelector rules in pod templates, then upload to Amazon Simple Storage Service (Amazon S3). Finally, at the job submission, specify the Spark properties spark.kubernetes.driver.podTemplateFile and spark.kubernetes.executor.podTemplateFile to point to the pod templates in Amazon S3.
For example, the following is the code for executor_pod_template.yaml:
The following is the code for driver_pod_template.yaml:
The following is the code for the Spark job submission:
Beginning with Amazon EMR versions 5.33.0 or 6.3.0, Amazon EMR on EKS supports the Amazon S3-based pod template feature. If you’re using an unsupported Amazon EMR version, such as EMR 6.1.0, you can use the pod template feature without Amazon S3 support. Make sure your Spark version is 3.0 or later, and copy the template files into your custom Docker image. The job submit script is changed to the following:
Serverless compute option: AWS Fargate
The sample solution runs on an Amazon EKS cluster with AWS Fargate. Fargate is a serverless compute engine for Amazon EKS and Amazon ECS. It makes it easy for you to focus on building applications because it removes the need to provision and manage EC2 instances or managed node groups in EKS. Fargate runs each task or pod in its own kernel, providing its own isolated compute environment. This enables your application to have resource isolation and enhanced security by design.
With Fargate, you don’t need to be an expert in Kubernetes operations. It automatically allocates the right amount of compute, eliminating the need to choose instances and scale cluster capacity, so the Kubernetes Cluster Autoscaler is no longer required to increase your cluster’s compute capacity.
In our instance, each Spark executor or driver is provisioned by a separate Fargate pod, to form a Spark cluster dedicated to an ETL pipeline. You only need to specify and pay for resources required to run the application—no more concerns about complex cluster management, queues, and isolation trade-offs.
Other Amazon EC2 options
In addition to the serverless choice, EMR on EKS can operate on all types of EKS clusters. For example, Amazon EKS managed node groups with Amazon Elastic Compute Cloud (Amazon EC2) On-Demand and Spot Instances.
Previously, we mentioned placing a Spark driver pod on an On-Demand Instance to reduce interruption risk. To further improve your cluster stability, it’s important to understand the Kubernetes high availability and restart policy features. These allow for exciting new possibilities, not only in computational multi-tenancy, but also in the ability of application self-recovery, for example relaunching a Spark driver on Spot or On-Demand instances. For more information and an example, see the GitHub repo.
As of this writing, our test result shows that a Spark driver can’t restart on failure with the EMR on EKS deployment type. So be mindful when designing a Spark application with the minimum downtime need, especially for a time-critical job. We recommend the following:
- Diversify your Spot requests – Similar to Amazon EMR’s instance fleet, EMR on EKS allows you to deploy a single application across multiple instance types to further enhance availability. With Amazon EC2 Spot best practices, such as capacity rebalancing, you can diversify the Spot request across multiple instance types within each Availability Zone. It limits the impact of Spot interruptions on your workload, if a Spot Instance is reclaimed by Amazon EC2. For more details, see Running cost optimized Spark workloads on Kubernetes using EC2 Spot Instances.
- Increase resilience – Repeatedly restarting a Spark application compromises your application performance or the length of your jobs, especially for time-sensitive data processes. We recommend the following best practice to increase your application resilience:
- Ensure your job is stateless so that it can self-recover without waiting for a dependency.
- If a checkpoint is required, for example in a stateful Spark streaming ETL, make sure your checkpoint storage is decoupled from the Amazon EKS compute resource, which can be detached and attached to your Kubernetes cluster via the persistent volume claims (PVCs), or simply use S3 Cloud Storage.
- Run the Spark driver on the On-Demand Instance defined by a pod template. It adds an extra layer of resiliency to your Spark application with EMR on EKS.
Security
EMR on EKS inherits the fine-grained security feature IAM roles for service accounts, (IRSA), offered by Amazon EKS. This means your data access control is no longer at the compute instance level, instead it’s granular at the container or pod level and controlled by an IAM role. The token-based authentication approach allows us to use one of the AWS default credential providers WebIdentityTokenCredentialsProvider to exchange the Kubernetes-issued token for IAM role credentials. It makes sure our applications deployed with EMR on EKS can communicate to other AWS services in a secure and private channel, without the need to store a long-lived AWS credential pair as a Kubernetes secret.
To learn more about the implementation details, see the GitHub repo.
Solution overview
In this example, we introduce a quality-aware design with the open-source declarative data processing Arc framework to abstract Spark technology away from you. It makes it easy for you to focus on business outcomes, not technologies.
We walk through the steps to run a predefined Arc ETL job with the EMR on EKS approach. For more information, see the GitHub repo.
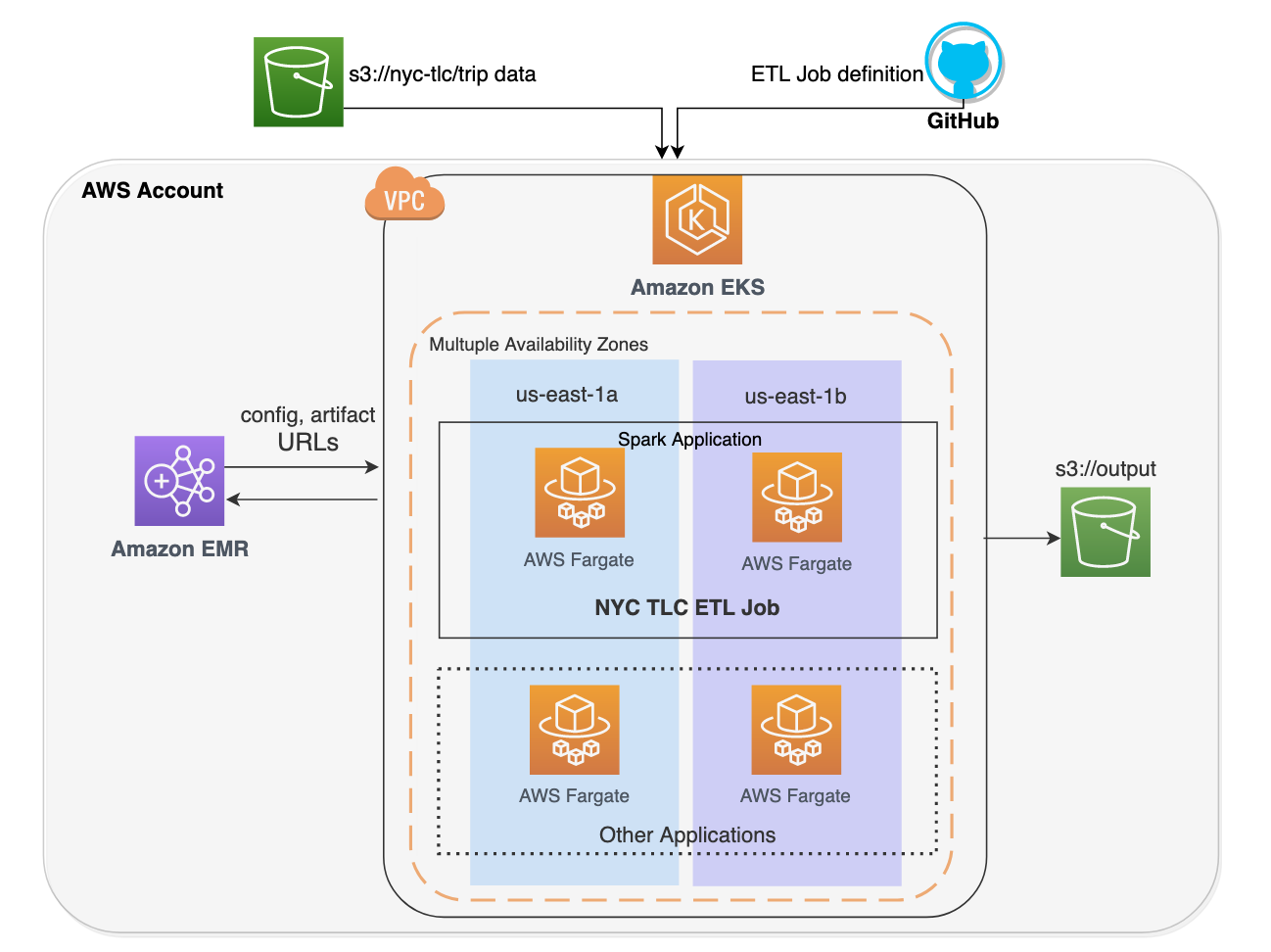
The sample solution launches a serverless Amazon EKS cluster, loads TLC green taxi trip records from a public S3 bucket, applies dataset schema, aggregates the data, and outputs to an S3 bucket as Parquet file format. The sample Spark application is defined as a Jupyter notebook green_taxi_load.ipynb powered by Arc, and the metadata information is defined in green_taxi_schema.json.
The following diagram illustrates our solution architecture.
Launch Amazon EKS
Provisioning takes approximately 20 minutes.
To get started, open AWS CloudShell in the us-east-1 Region. Run the following command to provision the new cluster eks-cluster, backed by Fargate. Then build the EMR virtual cluster emr-on-eks-cluster:
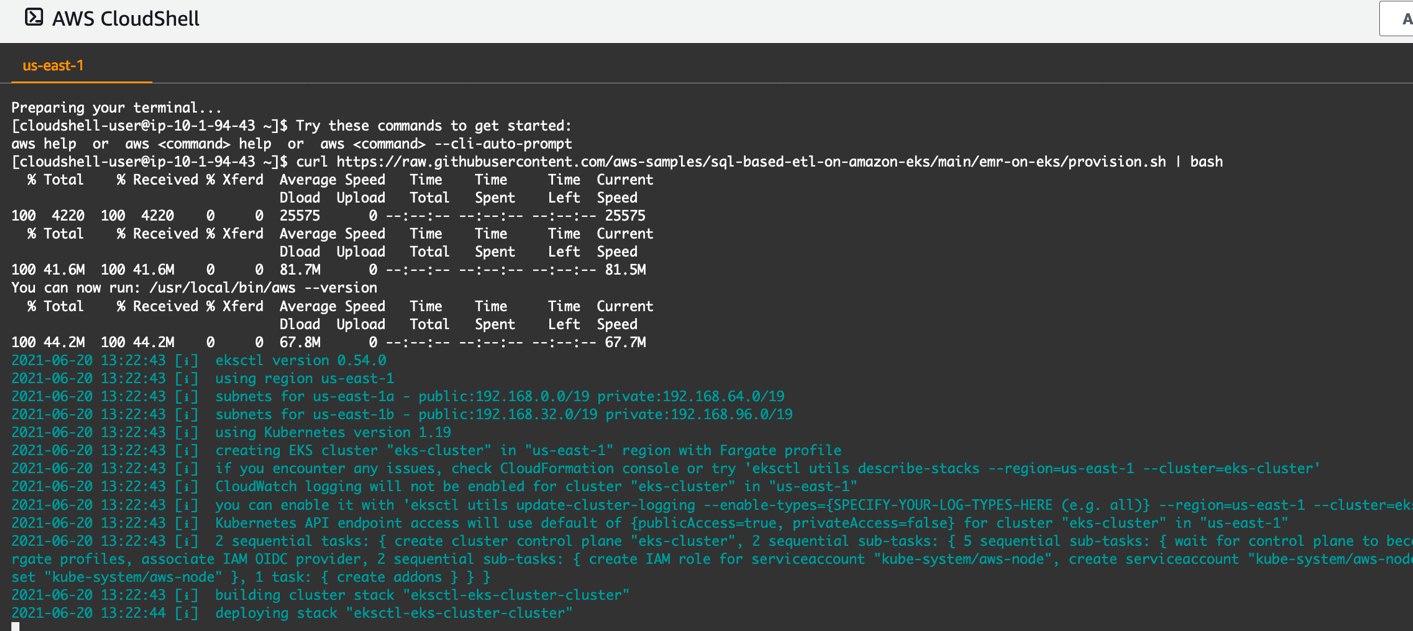
At the end of the provisioning, the shell script automatically creates an EMR virtual cluster by the following command. It registers Amazon EMR with the newly created Amazon EKS cluster. The dedicated namespace on the EKS is called emr.

Deploy the sample ETL job
- When provisioning is complete, submit the sample ETL job to EMR on EKS with a serverless virtual cluster called
emr-on-eks-cluster:

It runs the following job summit command:

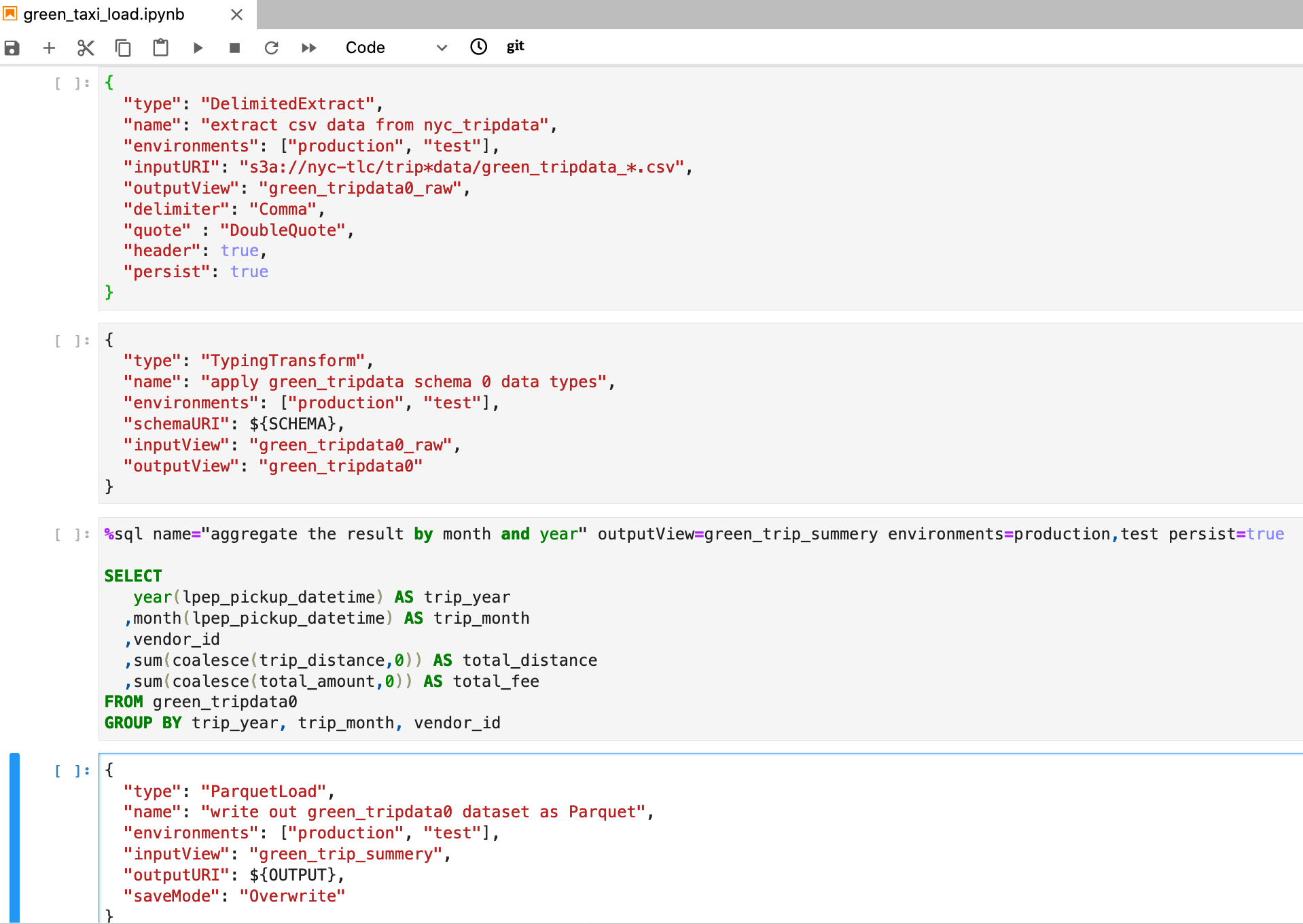
The declarative ETL job can be found on the blogpost’s GitHub repository. This is a screenshot of the job specification:
- Check your job progress and auto scaling status:
- As the job requested 10 executors, it automatically scales the Spark application from 0 to 10 pods (executors) on the EKS cluster. The Spark application automatically removes itself from the EKS when the job is done.

- Navigate to your Amazon EMR console to view application logs on the Spark History Server.
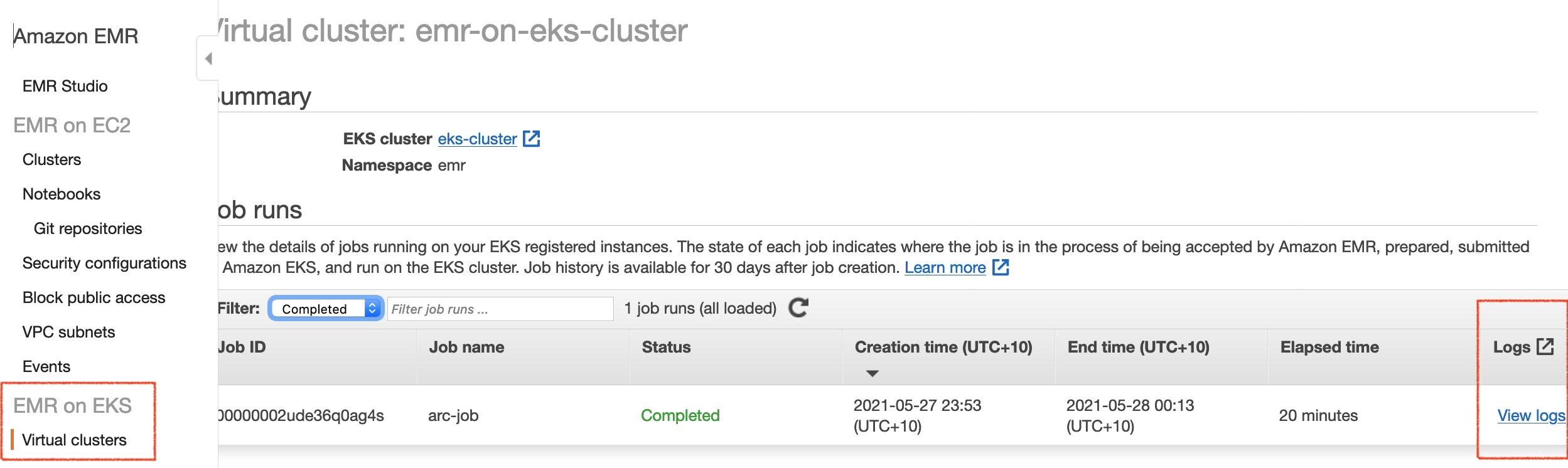
- You can also check the logs in CloudShell, as long as your Spark Driver is running:

Clean up
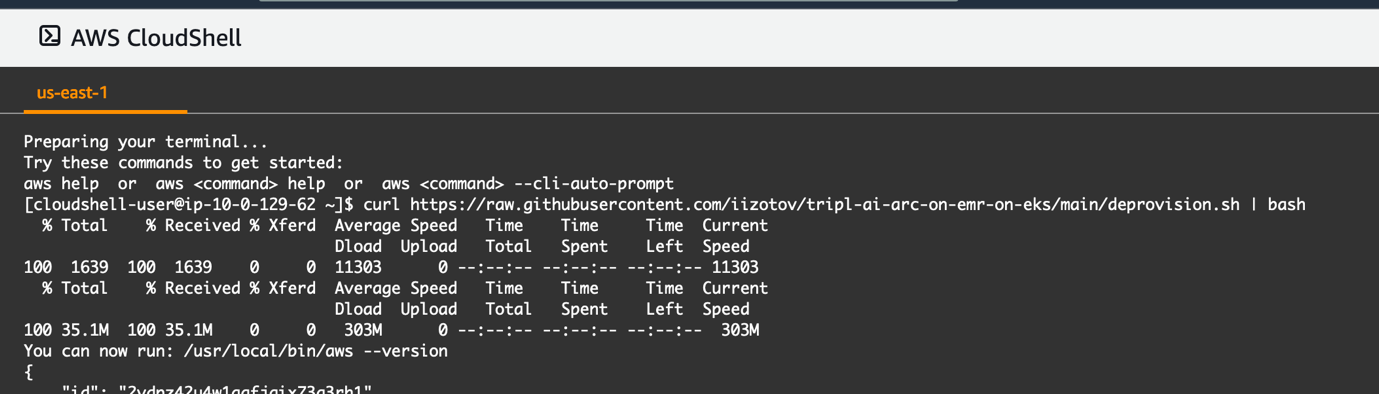
To clean up the AWS resources you created, run the following code:
Region support
At the time of this writing, Amazon EMR on EKS is available in US East (N. Virginia), US West (Oregon), US West (N. California), US East (Ohio), Canada (Central), Europe (Ireland, Frankfurt, and London), and Asia Pacific (Mumbai, Seoul, Singapore, Sydney, and Tokyo) Regions. If you want to use EMR on EKS in a Region that isn’t available yet, check out the open-source Apache Spark on Amazon EKS alternative on aws-samples GitHub. You can deploy the sample solution to your Region as long as Amazon EKS is available. Migrating a Spark workload on Amazon EKS to the fully managed EMR on EKS is easy and straightforward, with minimum changes required. Because the self-contained Spark application remains the same, only the deployment implementation differs.
Conclusion
This post introduces Amazon EMR on Amazon EKS and provides a walkthrough of a sample solution to demonstrate the “ETL as definition” concept. A declarative data processing framework enables you to build and deploy your Spark workloads with enhanced efficiency. With EMR on EKS, running applications built upon a declarative framework maximizes data process productivity, performance, reliability, and availability at scale. This pattern abstracts Spark technology away from you, and helps you to focus on deliverables that optimize business outcomes.
The built-in optimizations provided by the managed EMR on EKS can help not only data engineers with analytical skills, but also analysts, data scientists, and any SQL authors who can fully express their data workflows declaratively in Spark SQL. You can use this architectural pattern to drive your data ownership shift in your organization, from IT to non-IT stakeholders who have a better understanding of business operations and needs.
About the Authors
 Melody Yang is a Senior Analytics Specialist Solution Architect at AWS with expertise in Big Data technologies. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
Melody Yang is a Senior Analytics Specialist Solution Architect at AWS with expertise in Big Data technologies. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
 Shiva Achari is a Senior Data Lab Architect at AWS. He helps AWS customers to design and build data and analytics prototypes via the AWS Data Lab engagement. He has over 14 years of experience working with enterprise customers and startups primarily in the Data and Big Data Analytics space.
Shiva Achari is a Senior Data Lab Architect at AWS. He helps AWS customers to design and build data and analytics prototypes via the AWS Data Lab engagement. He has over 14 years of experience working with enterprise customers and startups primarily in the Data and Big Data Analytics space.
 Daniel Maldonado is an AWS Solutions Architect, specialist in Microsoft workloads and Big Data technologies, focused on helping customers to migrate their applications and data to AWS. Daniel has over 12 years of experience working with Information Technologies and enjoys helping clients reap the benefits of running their workloads in the cloud.
Daniel Maldonado is an AWS Solutions Architect, specialist in Microsoft workloads and Big Data technologies, focused on helping customers to migrate their applications and data to AWS. Daniel has over 12 years of experience working with Information Technologies and enjoys helping clients reap the benefits of running their workloads in the cloud.
 Igor Izotov is an AWS enterprise solutions architect, and he works closely with Australia’s largest financial services organizations. Prior to AWS, Igor held solution architecture and engineering roles with tier-1 consultancies and software vendors. Igor is passionate about all things data and modern software engineering. Outside of work, he enjoys writing and performing music, a good audiobook, or a jog, often combining the latter two.
Igor Izotov is an AWS enterprise solutions architect, and he works closely with Australia’s largest financial services organizations. Prior to AWS, Igor held solution architecture and engineering roles with tier-1 consultancies and software vendors. Igor is passionate about all things data and modern software engineering. Outside of work, he enjoys writing and performing music, a good audiobook, or a jog, often combining the latter two.