AWS Big Data Blog
Category: Analytics

Under the Hood of Server-Side Encryption for Amazon Kinesis Streams
Customers are using Amazon Kinesis Streams to ingest, process, and deliver data in real time from millions of devices or applications. Use cases for Kinesis Streams vary, but a few common ones include IoT data ingestion and analytics, log processing, clickstream analytics, and enterprise data bus architectures. Within milliseconds of data arrival, applications (KCL, Apache […]

Analysis of Top-N DynamoDB Objects using Amazon Athena and Amazon QuickSight
If you run an operation that continuously generates a large amount of data, you may want to know what kind of data is being inserted by your application. The ability to analyze data intake quickly can be very valuable for business units, such as operations and marketing. For many operations, it’s important to see what […]
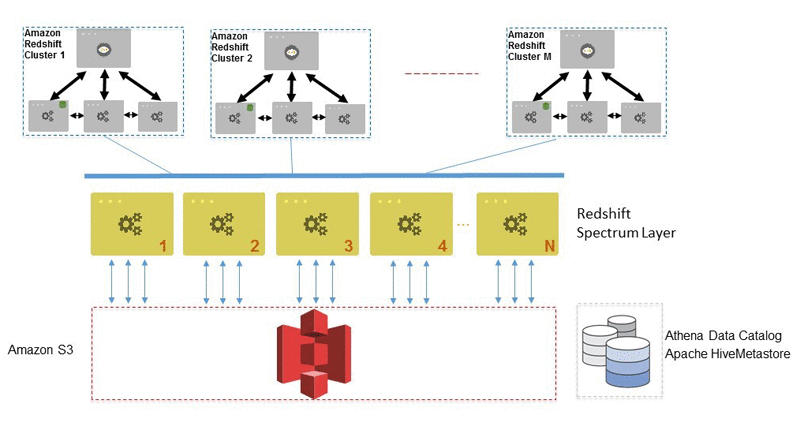
Best Practices for Amazon Redshift Spectrum
November 2022: This post was reviewed and updated for accuracy. Amazon Redshift Spectrum enables you to run Amazon Redshift SQL queries on data that is stored in Amazon Simple Storage Service (Amazon S3). With Amazon Redshift Spectrum, you can extend the analytic power of Amazon Redshift beyond the data that is stored natively in Amazon […]
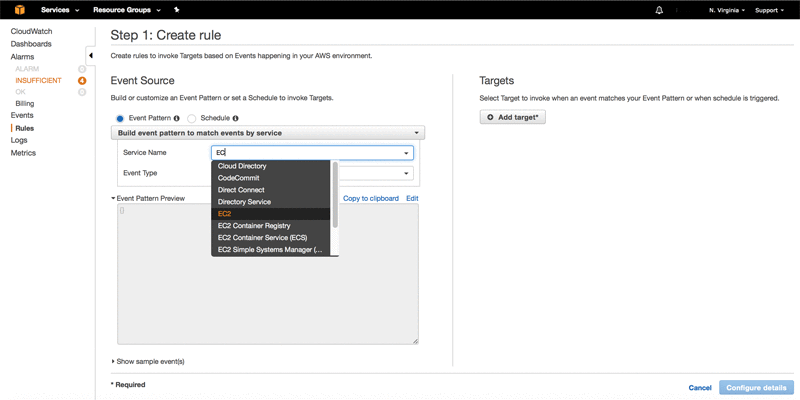
Visualize and Monitor Amazon EC2 Events with Amazon CloudWatch Events and Amazon Kinesis Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Monitoring your AWS environment is important for security, performance, and cost control purposes. For example, by monitoring […]
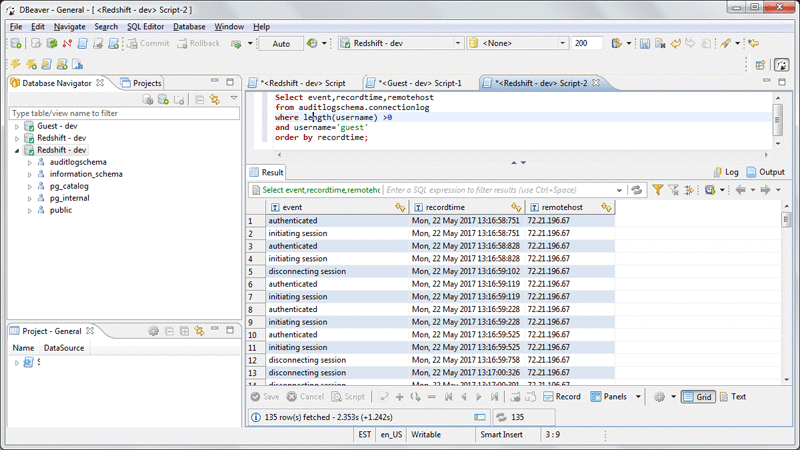
Analyze Database Audit Logs for Security and Compliance Using Amazon Redshift Spectrum
In this post, we’ll demonstrate querying the Amazon Redshift audit data logged in S3 to provide answers to common use cases described preceding.

Seven Tips for Using S3DistCp on Amazon EMR to Move Data Efficiently Between HDFS and Amazon S3
Although it’s common for Amazon EMR customers to process data directly in Amazon S3, there are occasions where you might want to copy data from S3 to the Hadoop Distributed File System (HDFS) on your Amazon EMR cluster. Additionally, you might have a use case that requires moving large amounts of data between buckets or regions. In these use cases, large datasets are too big for a simple copy operation.

Amazon QuickSight Adds Support for Amazon Redshift Spectrum
In April, we announced Amazon Redshift Spectrum in the AWS Blog. Redshift Spectrum is a new feature of Amazon Redshift that allows you to run complex SQL queries against exabytes of data in Amazon without having to load and transform any data. We’re happy to announce that Amazon QuickSight now supports Redshift Spectrum. Starting today, […]
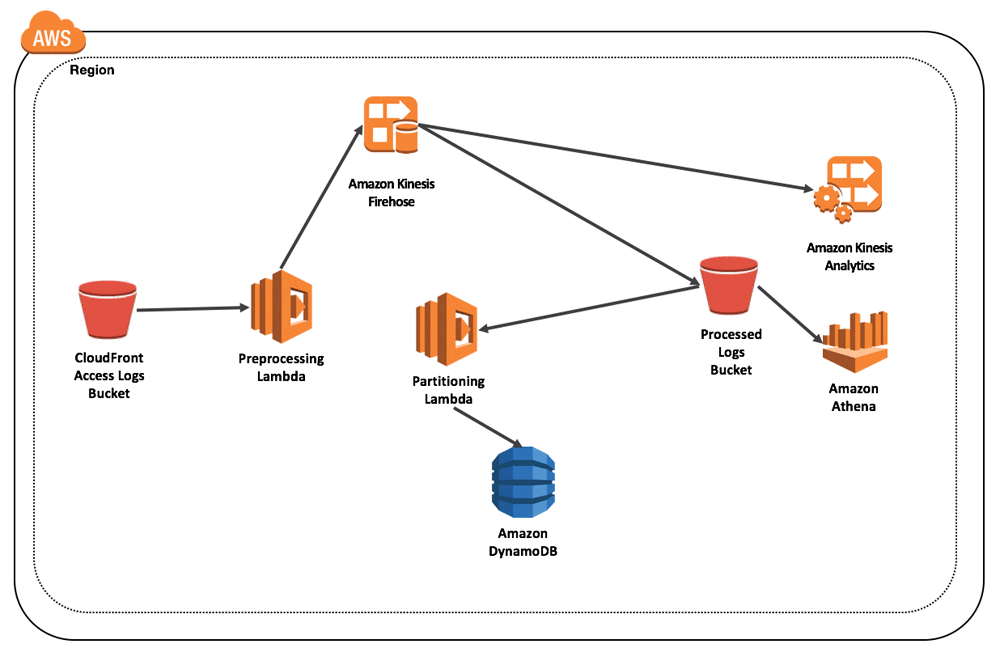
Build a Serverless Architecture to Analyze Amazon CloudFront Access Logs Using AWS Lambda, Amazon Athena, and Amazon Kinesis Analytics
Nowadays, it’s common for a web server to be fronted by a global content delivery service, like Amazon CloudFront. This type of front end accelerates delivery of websites, APIs, media content, and other web assets to provide a better experience to users across the globe. The insights gained by analysis of Amazon CloudFront access logs […]
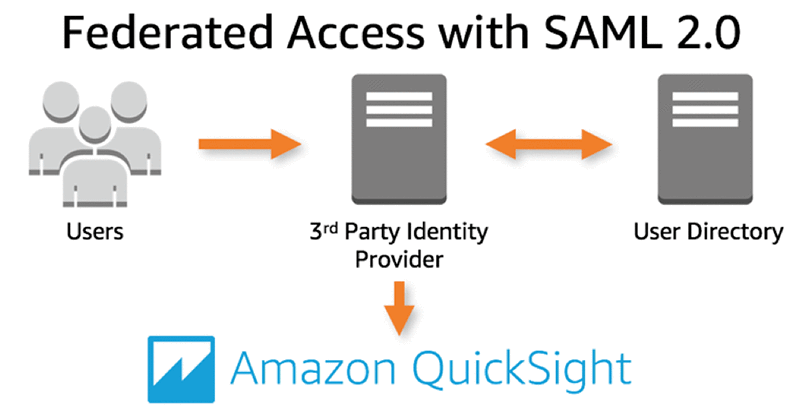
Amazon QuickSight Now Supports Federated Single Sign-On Using SAML 2.0
Since launch, Amazon QuickSight has enabled business users to quickly and easily analyze data from a wide variety of data sources with superfast visualization capabilities enabled by SPICE (Superfast, Parallel, In-memory Calculation Engine). When setting up Amazon QuickSight access for business users, administrators have a choice of authentication mechanisms. These include Amazon QuickSight–specific credentials, AWS […]
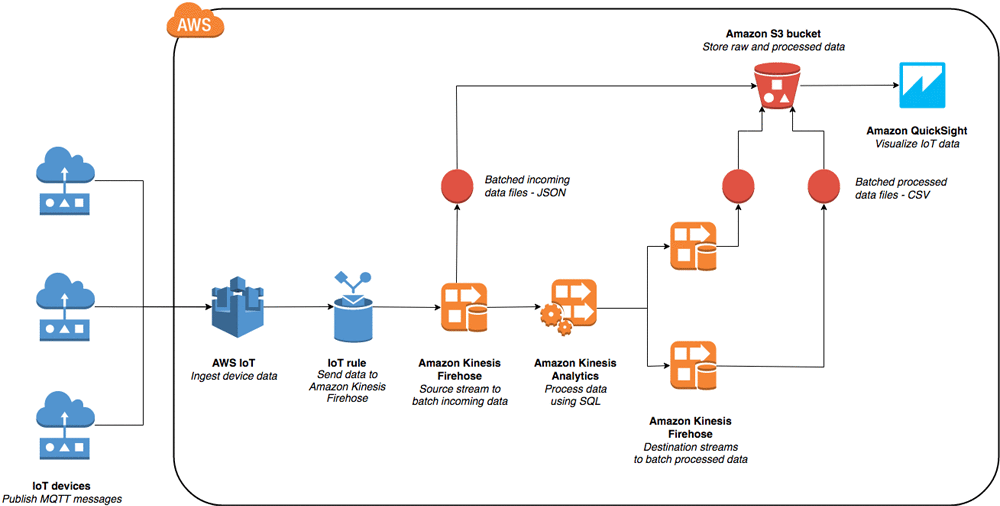
Build a Visualization and Monitoring Dashboard for IoT Data with Amazon Kinesis Analytics and Amazon QuickSight
April 2024: The solution presented in this post is deprecated. Customers across the world are increasingly building innovative Internet of Things (IoT) workloads on AWS. With AWS, they can handle the constant stream of data coming from millions of new, internet-connected devices. This data can be a valuable source of information if it can be […]