AWS Big Data Blog
Querying Amazon Kinesis Streams Directly with SQL and Spark Streaming
Amo Abeyaratne is a Big Data consultant with AWS Professional Services
Introduction
What if you could use your SQL knowledge to discover patterns directly from an incoming stream of data? Streaming analytics is a very popular topic of conversation around big data use cases. These use cases can vary from just accumulating simple web transaction logs to capturing high volume, high velocity and high variety of data emitted from billions of devices such as Internet of things. Most of these introduce a data stream at some point into your data processing pipeline and there is a plethora of tools that can be used for managing such streams. Sometimes, it comes down to choosing a tool that you can adopt faster with your existing skillset.
In this post, we focus on some key tools available within the Apache Spark application ecosystem for streaming analytics. This covers how features like Spark Streaming, Spark SQL, and HiveServer2 can work together on delivering a data stream as a temporary table that understands SQL queries.

This post guides you through how to access data that is ingested to an Amazon Kinesis stream, micro-batch them in specified intervals, and present each micro-batch as a table that you can query using SQL statements. The advantage in this approach is that application developers can modify SQL queries instead of writing Spark code from scratch, when there are requests for logic changes or new questions to be asked from the incoming data stream.
Spark Streaming, Dstreams, SparkSQL, and DataFrames
Before you start building the demo application environment, get to know how the components work within the Spark ecosystem. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of batched results. For more information, see the Spark Streaming Programming Guide.

In Spark Streaming, these batches of data are called DStreams (discretized streams), continuous streams of data represented as a sequence of RDDs (Resilient Distributed Datasets), which are Spark’s core abstraction for its data processing model.
Spark SQL, the SQL-like extension for the Spark API also has a programming abstraction called DataFrames, which are distributed collections of data organized into named columns. In this demo, you are making use of Spark’s ability to convert RDDs into DataFrames in order to present them as temporary tables that can be manipulated using SQL queries.
Sample use case and application design
For the purposes of this post, take a simple web analytics application as an example. Imagine that you are providing a simple service that collects, stores, and processes data about user access details for your client websites. For brevity, let’s say it only collects a user ID, web page URL, and timestamp. Although there are many ways of approaching it, this example uses Spark Streaming and Spark SQL to build a solution because you want your developers to be able to run SQL queries directly on the incoming data stream instead of compiling new Spark applications every time there is a new question to be asked.
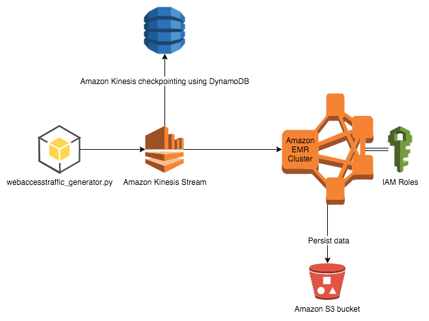
Now take a look at the AWS services used in this application. As shown in the diagram below, you write a Python application that generates sample data and feeds it into an Amazon Kinesis stream. Then, an EMR cluster with Spark installed is used for reading data from the Amazon Kinesis stream. The data is read in micro-batches at predefined intervals. Each micro-batch block is accessible as a temporary table where you can run SQL queries on the EMR master node using the HiveServer2 service. HiveServer2 is a server interface that enables remote clients to execute queries against Hive and retrieve the results. At the same time, those micro-batches are stored in a S3 bucket for persistent longer-term storage as parquet files. These are also mapped as an external table in Hive for later batch processing of workloads.
Create an Amazon Kinesis stream
Use Amazon Kinesis to provide an input stream of data to your application. Amazon Kinesis is a fully managed service for real-time processing of streaming data at massive scale. For your application, the Amazon Kinesis consumer creates an input DStream using the Kinesis Client Library (KCL). For more information, see Developing Amazon Kinesis Streams Consumers Using the Amazon Kinesis Client Library.
If you already have AWS command line tools installed in your desktop, you may run the following command:
aws kinesis create-stream --stream-name mystream --shard-count 1
This creates an Amazon Kinesis stream in your account’s default region. Now, spin up an EMR cluster to run the Spark application.
Create the EMR cluster
With Amazon Elastic MapReduce (Amazon EMR) you can analyze and process vast amounts of data. It does this by distributing the computational work across a cluster of virtual servers running in the Amazon cloud. The cluster is managed using an open-source framework called Hadoop.
You may use the following sample command to create an EMR cluster with AWS CLI tools. Remember to replace myKey with your Amazon EC2 key pair name.
aws emr create-cluster --release-label emr-4.2.0 --applications Name=Spark Name=Hive --ec2-attributes KeyName=myKey --use-default-roles --instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m3.xlarge InstanceGroupType=CORE,InstanceCount=2,InstanceType=m3.xlarge --bootstrap-actions Path=s3://aws-bigdata-blog/artifacts/Querying_Amazon_Kinesis/DownloadKCLtoEMR400.sh,Name=InstallKCLLibs
As the response to this command, you should receive a cluster ID. Note this cluster ID, as you need it when you log in to the master node via SSH. Until the cluster starts up, look at the sample code for the Python application.
Download the Python application
To generate sample data, you can use the AWS SDK for Python, also referred to as boto. You can install boto on your client machine.
The following code sample generates some random user IDs and URLs and gathers the current timestamp. Then it feeds each of those as a single record with comma-separated values into your Amazon Kinesis stream. This simulates an Amazon Kinesis producer application. Please make sure the region and kinesisStreamName variables are changed according to your Amazon Kinesis stream created in the earlier step.
import string
import random
import time
from datetime import datetime
from boto import kinesis
def random_generator(size=6, chars=string.ascii_lowercase + string.digits):
return ''.join(random.choice(chars) for x in range(size))
#connecting to Kinesis stream
region = 'us-east-1'
kinesisStreamName = 'myStream'
kinesis = kinesis.connect_to_region(region)
# generating data and feeding kinesis.
while True:
y = random_generator(10,"techsummit2015")
urls = ['foo.com','amazon.com','testing.com','google.com','sydney.com']
x = random.randint(0,4)
userid = random.randint(25,35)+1200
now = datetime.now()
timeformatted = str(now.month) + "/" + str(now.day) + "/" + str(now.year) + " " + str(now.hour) + ":" +str(now.minute) + ":" + str(now.second)
#building the pay load for kinesis puts.
putString = str(userid)+','+'www.'+urls[x]+'/'+y+','+timeformatted
patitionKey = random.choice('abcdefghij')
# schema of the input string now userid,url,timestamp
print putString
result = kinesis.put_record(kinesisStreamName,putString,patitionKey)
print result
Download the Spark Streaming application
Now that you have created an Amazon Kinesis stream and developed a Python application that feeds sample data to the stream, take a look at the main component of this solution, the Spark Streaming application written using Scala code. Download the sample code for this application.
This is an Amazon Kinesis consumer application developed using the Kinesis Client Library for spark. It captures data ingested through Amazon Kinesis into small batches of data based on the defined batch interval. Those batches (technically, RDDs) are converted to DataFrames and eventually converted to temporary tables. The application code presents such a temporary table through the HiveServer2 instance that is started during its runtime, and the temporary table name is passed as an argument to the application.
Additionally, I have also included an action such as .saveAsTable(“permKinesisTable”,Append) for demonstrating how to persist the batches on HDFS by appending every batch into a permanent table. This table is accessible through the Hive metastore under the name permKinesisTable. Instead of HDFS, you may also create a S3 bucket and point to the S3 location.
KinesisWatch.scala need to be built before it can be deployed on an EMR cluster and run as a Spark application. Use a build tool such as sbt, a simple build tool for Scala or maven. Use the build.sbt file or the .jar file already built and tested on an EMR 4.1.0 cluster to experiment with this functionality.
Run the Spark Streaming application
Now you have everything you need to test this scenario; take a look at the steps required to get the demo up and running.
Log in to the EMR cluster
Replace the cluster ID noted above with the following AWS CLI command to login to your cluster. Also you should point command at your EC2 key-pair-file location we allocated to the cluster instances.
aws emr ssh --cluster-id <Your_cluster_ID> --key-pair-file <path/to/myKey.pem>
Run components on the master node
After you are logged in to the master node, download the scripts and jar files from the repository and start running each component in your application.
Python code
Download this sample Python application. You can run this application on the EMR master node to simulate the process of an external application feeding data into Amazon Kinesis. On the master node, you may run the following commands on SSH terminal to start it:
# wget https://s3.amazonaws.com/aws-bigdata-blog/artifacts/Querying_Amazon_Kinesis/webaccesstraffic_generator.py # python webaccesstraffic_generator.py
Now you may see entries being ingested in your screen, similar to the following:

Sample Spark Streaming application
After the Python simulator has started feeding the Amazon Kinesis stream, the next step is to download the Spark Streaming application that you built and compiled into a .jar file and submit it to the Spark cluster as a job using the commands given below. Open a new SSH terminal to the master node and run this on a separate session:
# wget https://s3.amazonaws.com/aws-bigdata-blog/artifacts/Querying_Amazon_Kinesis/kinesis-test_2.11-1.0.jar # export HIVE_SERVER2_THRIFT_PORT=10002 # spark-submit --verbose --master local[*] --class "org.apache.spark.examples.streaming.KinesisWatch" --jars /usr/lib/spark/extras/lib/amazon-kinesis-client-1.2.1.jar file:///home/hadoop/kinesis-test_2.11-1.0.jar "test-spark-streaming" "myStream" "https://kinesis.us-east-1.amazonaws.com" "10000" "userid url timestamp" "," "inputkinesis"
Note that inside this Spark application, you are also starting an instance of HiveServer2. This is a server interface that enables remote clients to execute queries against Hive and retrieve the results. The current implementation, based on Thrift RPC, is an improved version of HiveServer and supports multi-client concurrency and authentication. You are allocating a port for this service to start up during runtime by setting the environment variable HIVE_SERVER2_THRIFT_PORT.
This sample application provides you with the ability to pass in as arguments a batch interval (such as 10000ms), a schema string for the incoming data through Amazon Kinesis, a delimiter (such as “,”) and a table name for the temporary table (such as “inputkinesis”). This is something you can change at your discretion in order to make your Spark application more generic and portable between different use cases. See the appendix for descriptions of each argument passed into the application.
After the streaming application has started, you may see something similar to this on your screen. In the Scala code, the displayed number is the output for “SELECT count(*) FROM tempTableName” command embedded in the code. Because you defined the micro-batch interval as 10000ms, every 10 seconds you should see a count of the records populated into this temporary table.

Testing the Application
The next step is to run a SQL query through a JDBC connection to test the functionality of your demo application. Now the Amazon Kinesis stream is ingested with records by your Python script and the Spark Streaming application is capturing it in 10-second intervals. It also presents those small batches as temporary tables via HiveServer2. How can you connect to HiveServer2 service?
Open a new SSH terminal again to keep things simple and try the following commands. Beeline is a tool comes that bundled with the Hive applications stack within Hadoop. It is based on SQLLine, which is a Java console-based utility for connecting to relational databases and executing SQL commands. The following commands use Beeline and connect to the temporary tables generated as the Amazon Kinesis stream gets populated with data.
# beeline # beeline>!connect jdbc:hive2://localhost:10002
When prompted for a user name, type “spark” and press Enter. Leave the password as blank and press Enter. Now you should be able to run SQL queries in the prompt, as shown below. Note that ‘isTemporary’ is marked true for the “inputkinesis” table.

To access this JDBC connection from outside your cluster, you may use an SSH tunnel to forward the local port to a remote port on your client computer:
ssh -i @<keyName@>-L 10002:<master-node-dns-or-ip>:10002 hadoop@<master-node-dns-or- ip@>
This allows you to access these tables via external tools installed on your laptop. However, please note that these temporary tables are not compatible with Tableau at this stage.
Conclusion
In this post, I discussed how a sample Spark streaming application can be used to present a micro-batch of data in the form of a temporary table, accessible via JDBC. This enables you to use external SQL based to query streaming data directly on an Amazon Kinesis stream.
This feature comes in handy as it allows you to run SQL queries against recent data (within the batch interval window) and at the same time gives the ability to join them with persisted previous batch data using SQL statements. As this approach provides you a platform to dynamically query your stream, it saves the hassle of having to rewrite and rebuild spark code every time you need to ask a new questions from your data.
By running this on AWS you have the ability to scale Amazon Kinesis in to multiple shards based on your throughput requirements. Also you can dynamically scale EMR clusters to improve the processing times based on demand.
Once the testing is completed, do not forget to terminate your EMR cluster and delete the Amazon Kinesis stream.
Appendix
Spark Streaming application command line arguments
Usage: KinesisWatch <app-name> <stream-name> <endpoint-url> <batch-length-ms> <schmaString> <inputDelimiter> <tempTableName> <app-name>Name of the consumer app, used to track the read data in DynamoDB. <stream-name> Name of the Amazon Kinesis stream. <endpoint-url> Endpoint of the Amazon Kinesis Analytics service (e.g., https://kinesis.us-east-1.amazonaws.com). <batch-length-ms> Duration of each batch for the temp table view taken directly from the stream, in milliseconds. <schmaString> Schema for CSV inputs via Amazon Kinesis. Block within double quotes (e.g., "custid date value1 value2" for a 4-column DataFrame). This has to match the input data. <inputDelimiter> Character to split the data into fields in each row of the stream (e.g., ","). <tempTableName> Name of the tempTable accessible via JDBC Hive ThriftServer2 for the duration of the batch.
If you have a question or suggestion, please leave a comment below.
AWS Big Data Support Engineer Troy Rose contributed to this post.
Related:
Visualizing Real-time, Geotagged Data with Amazon Kinesis
