AWS Big Data Blog
Category: AWS Big Data

Build a Community of Analysts with Amazon QuickSight
Imagine you’ve just landed your dream job. You’ve always liked tackling the hardest problems and you’ve got one now: You’ll work for a chain of coffee shops that’s struggling against fierce competition, tight budgets, and low morale. But there’s a new management team in place. As head of business intelligence (BI), you think you can […]

Scale Your Amazon Kinesis Stream Capacity with UpdateShardCount
Allan MacInnis is a Kinesis Solution Architect for Amazon Web Services Starting today, you can easily scale your Amazon Kinesis streams to respond in real time to changes in your streaming data needs. Customers use Amazon Kinesis to capture, store, and analyze terabytes of data per hour from clickstreams, financial transactions, social media feeds, and […]

re:Invent 2016: AWS Big Data & Machine Learning Sessions
Roy Ben-Alta is Sr. Business Development Manager at AWS – Big Data & Machine Learning Updated December 9, 2016 with links to session videos. We can’t believe that there are just a couple of weeks left before re:Invent 2016. If you are attending this year, you will want to check out our Big Data sessions! […]
Use Apache Flink on Amazon EMR
Today we are making it even easier to run Flink on AWS as it is now natively supported in Amazon EMR 5.1.0. EMR supports running Flink-on-YARN so you can create either a long-running cluster that accepts multiple jobs or a short-running Flink session in a transient cluster that helps reduce your costs by only charging you for the time that you use.

Month in Review: October 2016
Another month of big data solutions on the Big Data Blog. Take a look at our summaries below and learn, comment, and share. Thanks for reading! Building Event-Driven Batch Analytics on AWS Modern businesses typically collect data from internal and external sources at various frequencies throughout the day. In this post, you learn an elastic […]

Using pgpool and Amazon ElastiCache for Query Caching with Amazon Redshift
In this blog post, we’ll use a real customer scenario to show you how to create a caching layer in front of Amazon Redshift using pgpool and Amazon ElastiCache.
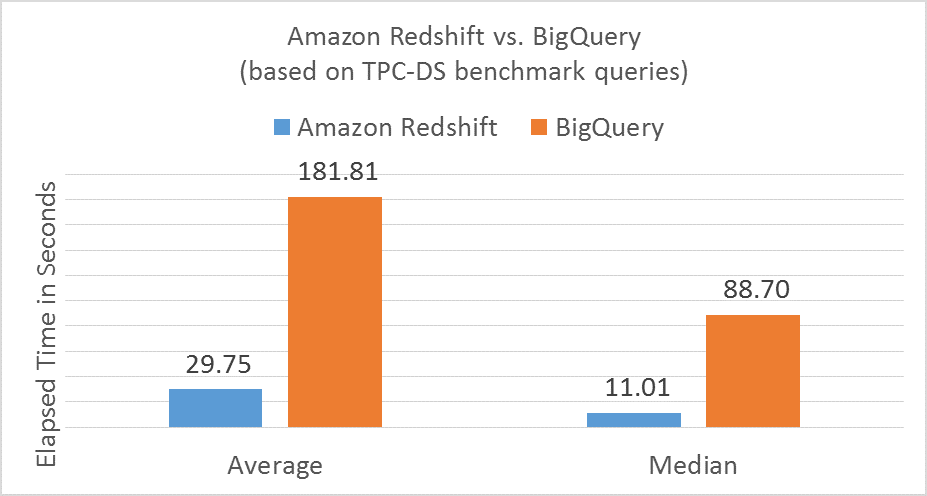
Fact or Fiction: Google BigQuery Outperforms Amazon Redshift as an Enterprise Data Warehouse?
Publishing misleading performance benchmarks is a classic old guard marketing tactic. It’s not surprising to see old guard companies (like Oracle) doing this, but we were kind of surprised to see Google take this approach, too. So, when Google presented their BigQuery vs. Amazon Redshift benchmark results at a private event in San Francisco on September 29, 2016, it piqued our interest and we decided to dig deeper.

Running sparklyr – RStudio’s R Interface to Spark on Amazon EMR
This post was last updated July 7th, 2021 (original version by Tom Zeng). The Sparklyr package by RStudio has made processing big data in R a lot easier. Sparklyr is an R interface to Spark, it allows using Spark as the backend for dplyr – one of the most popular data manipulation packages. Sparklyr also […]

Optimize Amazon S3 for High Concurrency in Distributed Workloads
In today’s blog post, I will discuss how to optimize Amazon S3 for an architecture commonly used to enable genomic data analyses. This optimization is important to my work in genomics because, as genome sequencing continues to drop in price, the rate at which data becomes available is accelerating.

How Eliza Corporation Moved Healthcare Data to the Cloud
In this post, I discuss some of the practical challenges faced during the implementation of the data lake for Eliza and the corresponding details of the ways we solved these issues with AWS. The challenges we faced involved the variety of data and a need for a common view of the data.