AWS Big Data Blog
Category: Intermediate (200)
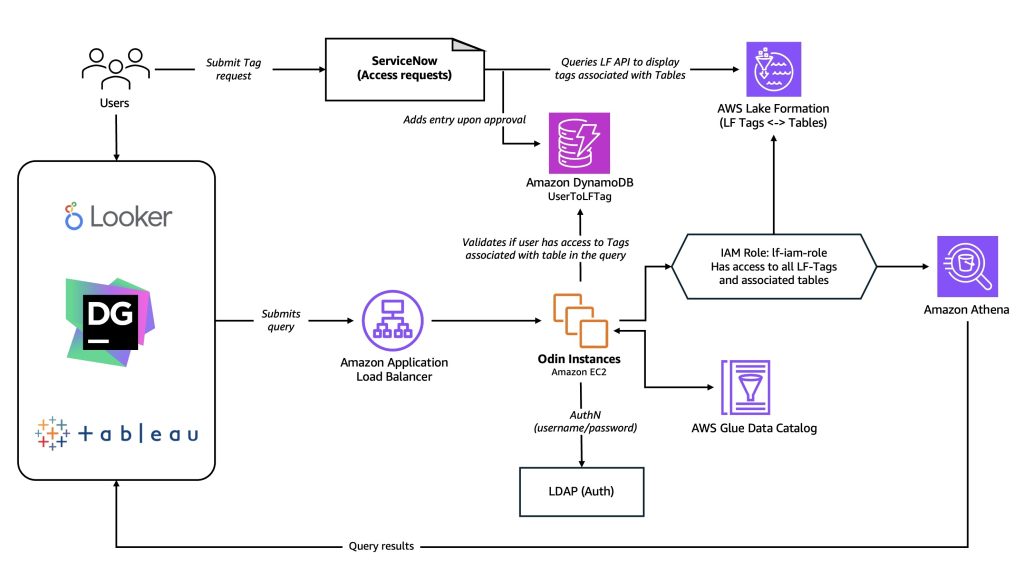
How Twilio secured their multi-engine query platform with AWS Lake Formation
Twilio is a cloud communications platform that provides programmable APIs and tools for developers to easily integrate voice, messaging, email, video, and other communication features into their applications and customer engagement workflows. In this blog series we discuss how we built a multi-engine query platform at Twilio. The first part introduces the use case that led us to build a new platform and why we selected Amazon Athena alongside our open-source Presto implementation. This second part discusses how Twilio’s query infrastructure platform integrates with AWS Lake Formation to provide fine-grained access control to all their data.

Amazon OpenSearch Serverless introduces collection groups to optimize cost for multi-tenant workloads
Today, we’re excited to announce the general availability of the collection groups feature for Amazon OpenSearch Serverless. With this feature you can reduce compute costs for multi-tenant workloads while creating secure tenant boundaries through per-tenant encryption, giving you the flexibility to balance cost efficiency with the exact level of isolation and security your applications requires.

Improving order history search using semantic search with Amazon OpenSearch Service
If you’ve ever shopped on Amazon, you’ve used Your Orders. This feature maintains your complete order history dating back to 1995, so you can track and manage every purchase you’ve made. The order history search feature lets you find your past purchases by entering keywords in the search bar. Beyond just finding items, it provides a straightforward way to repurchase the same or similar items, saving you time and effort. In this post, we show you how the Your Orders team improved order history search by introducing semantic search capabilities on top of our existing lexical search system, using Amazon OpenSearch Service and Amazon SageMaker.

Verisk cuts processing time and storage costs with Amazon Redshift and lakehouse
Verisk, a catastrophe modeling SaaS provider serving insurance and reinsurance companies worldwide, cut processing time from hours to minutes-level aggregations while reducing storage costs by implementing a lakehouse architecture with Amazon Redshift and Apache Iceberg. If you’re managing billions of catastrophe modeling records across hurricanes, earthquakes, and wildfires, this approach eliminates the traditional compute-versus-cost trade-off by separating storage from processing power. In this post, we examine Verisk’s lakehouse implementation, focusing on four architectural decisions that delivered measurable improvements.

Amazon OpenSearch Service 101: T-shirt size your domain for e-commerce search
While general sizing guidelines for OpenSearch Service domains are covered in detail in OpenSearch Service documentation, in this post we specifically focus on T-shirt-sizing OpenSearch Service domains for e-commerce search workloads. T-shirt sizing simplifies complex capacity planning by categorizing workloads into sizes like XS, S, M, L, XL based on key workload parameters such as data volume and query concurrency.

Amazon Athena adds 1-minute reservations and new capacity control features
Amazon Athena is a serverless interactive query service that makes it easy to analyze data using SQL. With Athena, there’s no infrastructure to manage, you simply submit queries and get results. Capacity Reservations is a feature of Athena that addresses the need to run critical workloads by providing dedicated serverless capacity for workloads you specify. In this post, we highlight three new capabilities that make Capacity Reservations more flexible and easier to manage: reduced minimums for fine-grained capacity adjustments, an autoscaling solution for dynamic workloads, and capacity cost and performance controls.

Amazon OpenSearch Ingestion 101: Set CloudWatch alarms for key metrics
This post provides an in-depth look at setting up Amazon CloudWatch alarms for OpenSearch Ingestion pipelines. It goes beyond our recommended alarms to help identify bottlenecks in the pipeline, whether that’s in the sink, the OpenSearch clusters data is being sent to, the processors, or the pipeline not pulling or accepting enough from the source. This post will help you proactively monitor and troubleshoot your OpenSearch Ingestion pipelines.

Secure Apache Spark writes to Amazon S3 on Amazon EMR with dynamic AWS KMS encryption
When processing data at scale, many organizations use Apache Spark on Amazon EMR to run shared clusters that handle workloads across tenants, business units, or classification levels. In such multi-tenant environments, different datasets often require distinct AWS Key Management Service (AWS KMS) keys to enforce strict access controls and meet compliance requirements. At the same […]

Enable strategic data quality management with AWS Glue DQDL labels
AWS Glue DQDL labels add organizational context to data quality management by attaching business metadata directly to validation rules. In this post, we highlight the new DQDL labels feature, which enhances how you organize, prioritize, and operationalize your data quality efforts at scale. We show how labels such as business criticality, compliance requirements, team ownership, or data domain can be attached to data quality rules to streamline triage and analysis. You’ll learn how to quickly surface targeted insights (for example, “all high-priority customer data failures owned by marketing” or “GDPR-related issues from our Salesforce ingestion pipeline”) and how DQDL labels can help teams improve accountability and accelerate remediation workflows.

Unlock granular resource control with queue-based QMR in Amazon Redshift Serverless
With Amazon Redshift Serverless queue-based Query Monitoring Rules (QMR), administrators can define workload-aware thresholds and automated actions at the queue level—a significant improvement over previous workgroup-level monitoring. You can create dedicated queues for distinct workloads such as BI reporting, ad hoc analysis, or data engineering, then apply queue-specific rules to automatically abort, log, or restrict queries that exceed execution-time or resource-consumption limits. By isolating workloads and enforcing targeted controls, this approach protects mission-critical queries, improves performance predictability, and prevents resource monopolization—all while maintaining the flexibility of a serverless experience. In this post, we discuss how you can implement your workloads with query queues in Redshift Serverless.