AWS Big Data Blog
Code versioning using AWS Glue Studio and GitHub
AWS Glue now offers integration with Git, an open-source version control system widely used across the developer community. Thanks to this integration, you can incorporate your existing DevOps practices on AWS Glue jobs. AWS Glue is a serverless data integration service that helps you create jobs based on Apache Spark or Python to perform extract, transform, and load (ETL) tasks on datasets of almost any size.
Git integration in AWS Glue works for all AWS Glue job types, both visual and code-based. It offers built-in integration with both GitHub and AWS CodeCommit, and makes it easier to use automation tools like Jenkins and AWS CodeDeploy to deploy AWS Glue jobs. AWS Glue Studio’s visual editor now also supports parameterizing data sources and targets for transparent deployments between environments.
Overview of solution
To demonstrate how to integrate AWS Glue Studio with a code hosting platform for version control and collaboration, we use the Toronto parking tickets dataset, specifically the data about parking tickets issued in the city of Toronto in 2019. The goal is to create a job to filter parking tickets based on a specific category and push the code to a GitHub repo for version control. After the job is uploaded on the repository, we make some changes to the code and pull the changes back to the AWS Glue job.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- A GitHub account
- An AWS Identity and Access Management (IAM) user with access to the following services:
- AWS CloudFormation
- AWS Glue
- Amazon Simple Storage Service (Amazon S3)
If the AWS account you use to follow this post uses AWS Lake Formation to manage permissions on the AWS Glue Data Catalog, make sure that you log in as a user with access to create databases and tables. For more information, refer to Implicit Lake Formation permissions.
Launch your CloudFormation stack
To create your resources for this use case, complete the following steps:
- Launch your CloudFormation stack in
us-east-1:

- Under Parameters, for paramBucketName, enter a name for your S3 bucket (include your account number).
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.

- Wait until the creation of the stack is complete, as shown on the AWS CloudFormation console.

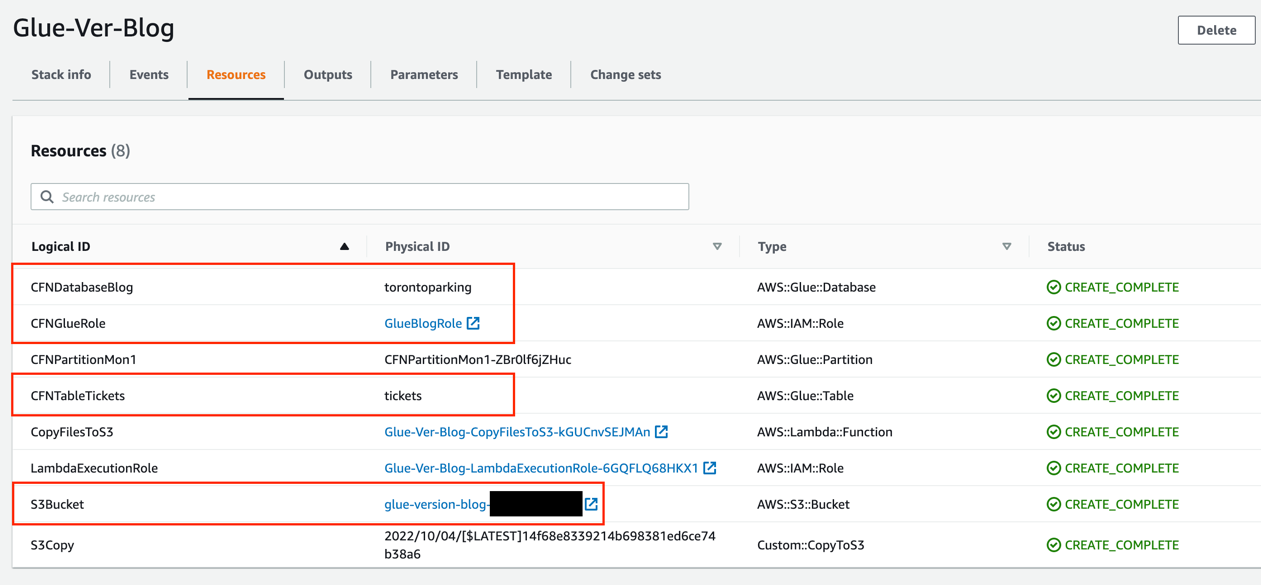
Launching this stack creates AWS resources. You need the following resources from the Outputs tab for the next steps:
- CFNGlueRole – The IAM role to run AWS Glue jobs
- S3Bucket – The name of the S3 bucket to store solution-related files
- CFNDatabaseBlog – The AWS Glue database to store the table related to this post
- CFNTableTickets – The AWS Glue table to use as part of the sample job
Configure the GitHub repository
We use GitHub as the source control system for this post. In order to use it, you need a GitHub account. After the account is created, you need to create following components:
- GitHub repository – Create a repository and name it
glue-ver-log. For instructions, refer to Create a repo. - Branch – Create a branch and name it develop. For instructions, refer to Managing branches.
- Personal access token – For instructions, refer to Creating a personal access token. Make sure to keep the personal access token handy because you use it in later steps.
Create an AWS Glue Studio job
Now that the infrastructure is set up, let’s author an AWS Glue job in our account. Complete the following steps:
- On the AWS Glue console, choose Jobs in the navigation pane.

- Select Visual job with blank canvas and choose Create.

- Enter a name for the job using the title editor. For example,
aws-glue-git-demo-job.

- On the Visual tab, choose Source and then choose AWS Glue Data Catalog

- For Database, choose
torontoparkingand for Table, choose tickets.

- Choose Transform and then Filter.
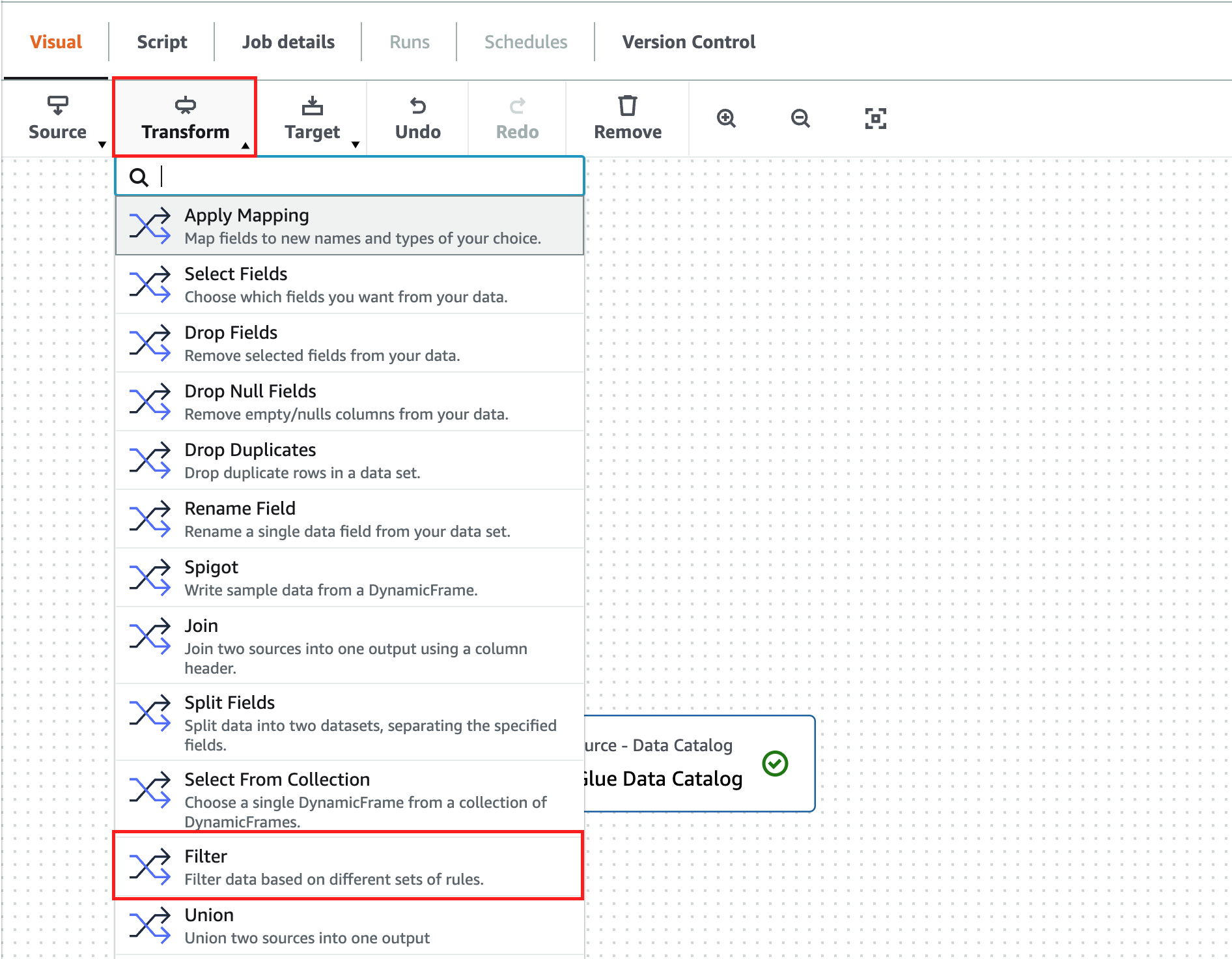
- Add a filter by
infraction_descriptionand set the value toPARK ON PRIVATE PROPERTY.

- Choose Target and then choose Amazon S3.

- For Format, choose Parquet.
- For S3 Target Location, enter
s3://glue-version-blog-YOUR ACOUNT NUMBER/output/. - For Data Catalog update options, select Do not update the Data Catalog.

- Go to the Script tab to verify that a script has been generated.

- Go to the Job Details tab to make sure that the role
GlueBlogRoleis selected and leave everything else with the default values.

Because the catalog table names in the production and development environment may be different, AWS Glue Studio now allows you to parameterize visual jobs. To do so, perform the following steps: - On the Job details tab, scroll to the Job parameters section under Advanced properties.
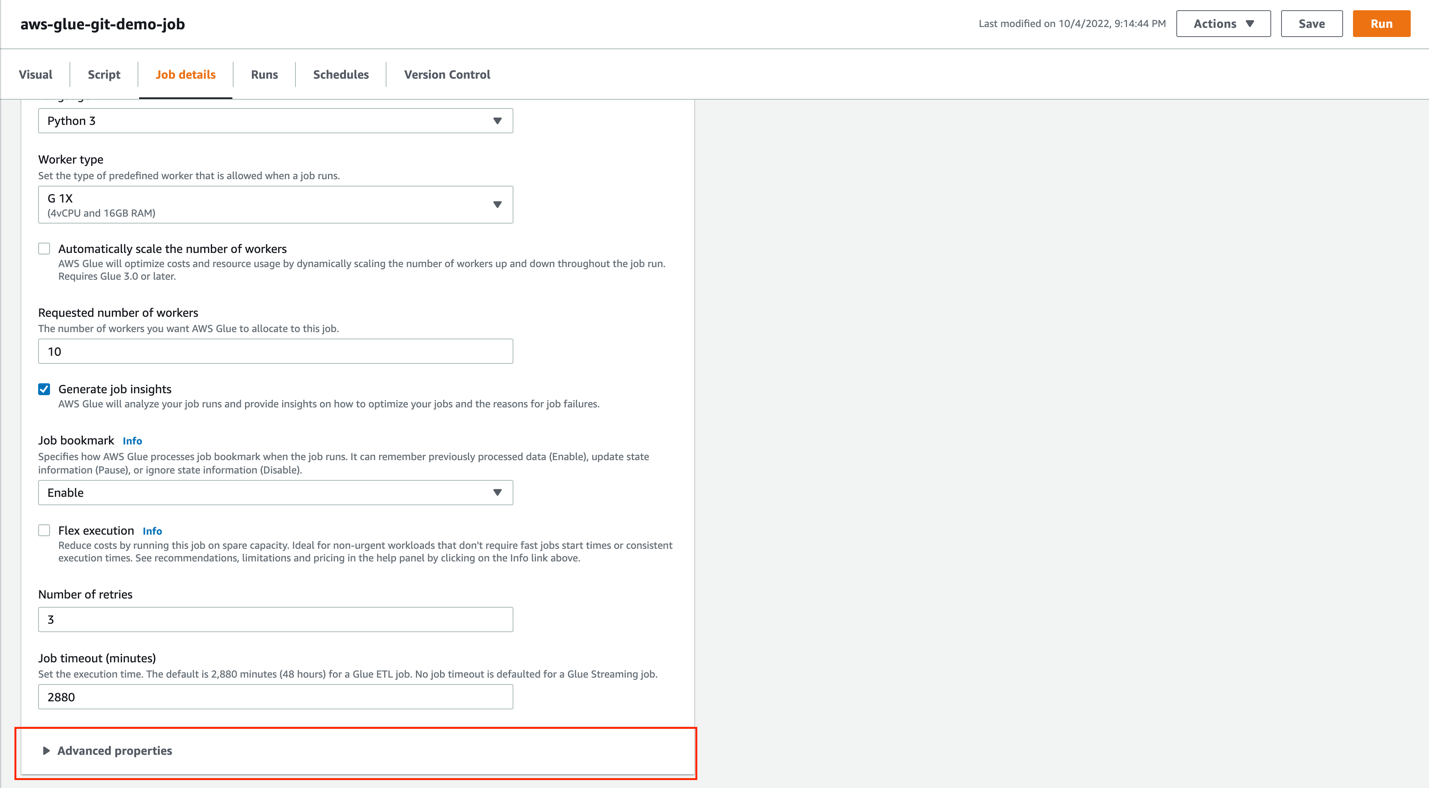
- Create the
--source.database.nameparameter and set the value totorontoparking. - Create the
--souce.table.nameparameter and set the value totickets.

- Go to the Visual tab and choose the AWS Glue Data Catalog node.Notice that under each of the database and table selection options is a new expandable section called Use runtime parameters.
- The run time parameters are auto populated with the parameters previously created. Clicking on the Apply button will apply the default values for these parameters.

- Go to the Script tab to review the script.AWS Glue Studio code generation automatically picks up the parameters to resolve and then makes the appropriate references in the script so that the parameters can be used.
 Now the job is ready to be pushed into the develop branch of our version control system.
Now the job is ready to be pushed into the develop branch of our version control system. - On the Version Control tab, for Version control system, choose Github.
- For Personal access token, enter your GitHub token.
- For Repository owner, enter the owner of your GitHub account.

- In the Repository configuration section, for Repository, choose
glue-ver-blog. - For Branch, choose
develop. - For Folder, leave it blank.

- Choose Save to save the job.

Push to the repository
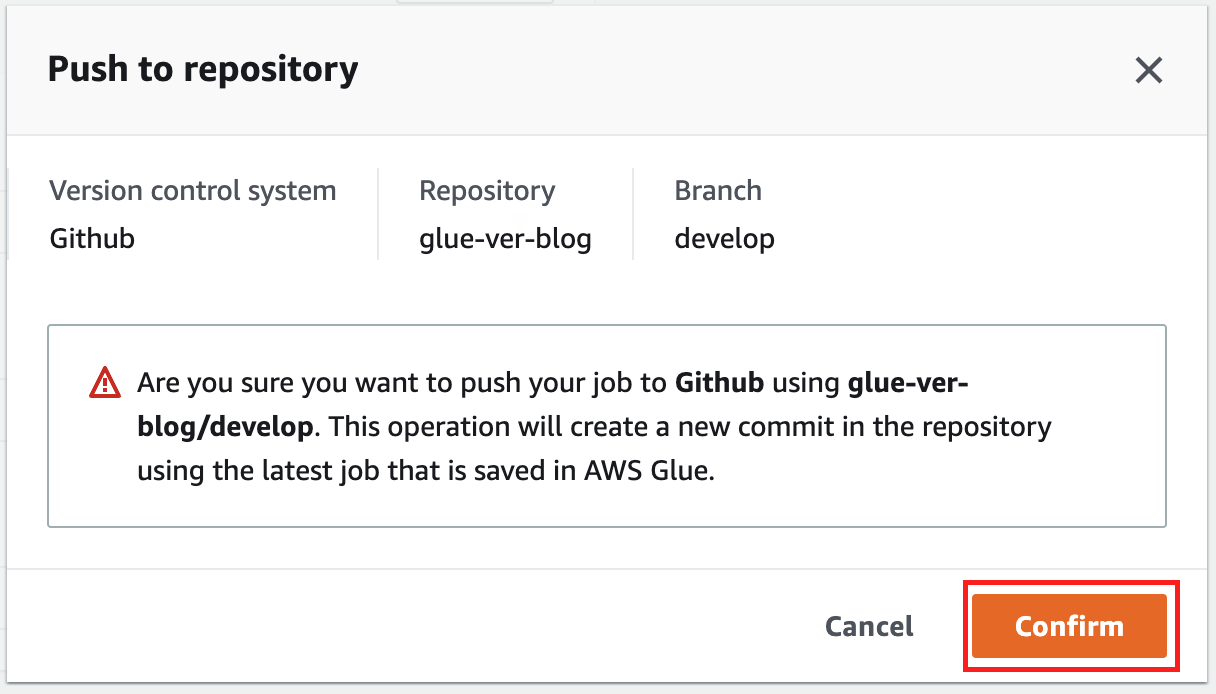
Now the job can be pushed to the remote repository.
- On the Actions menu, choose Push to repository.

- Choose Confirm to confirm the operation.
After the operation succeeds, the page reloads to reflect the latest information from the version control system. A notification shows the latest available commit and links you to the commit on GitHub.

- Choose the commit link to go to the repository on GitHub.
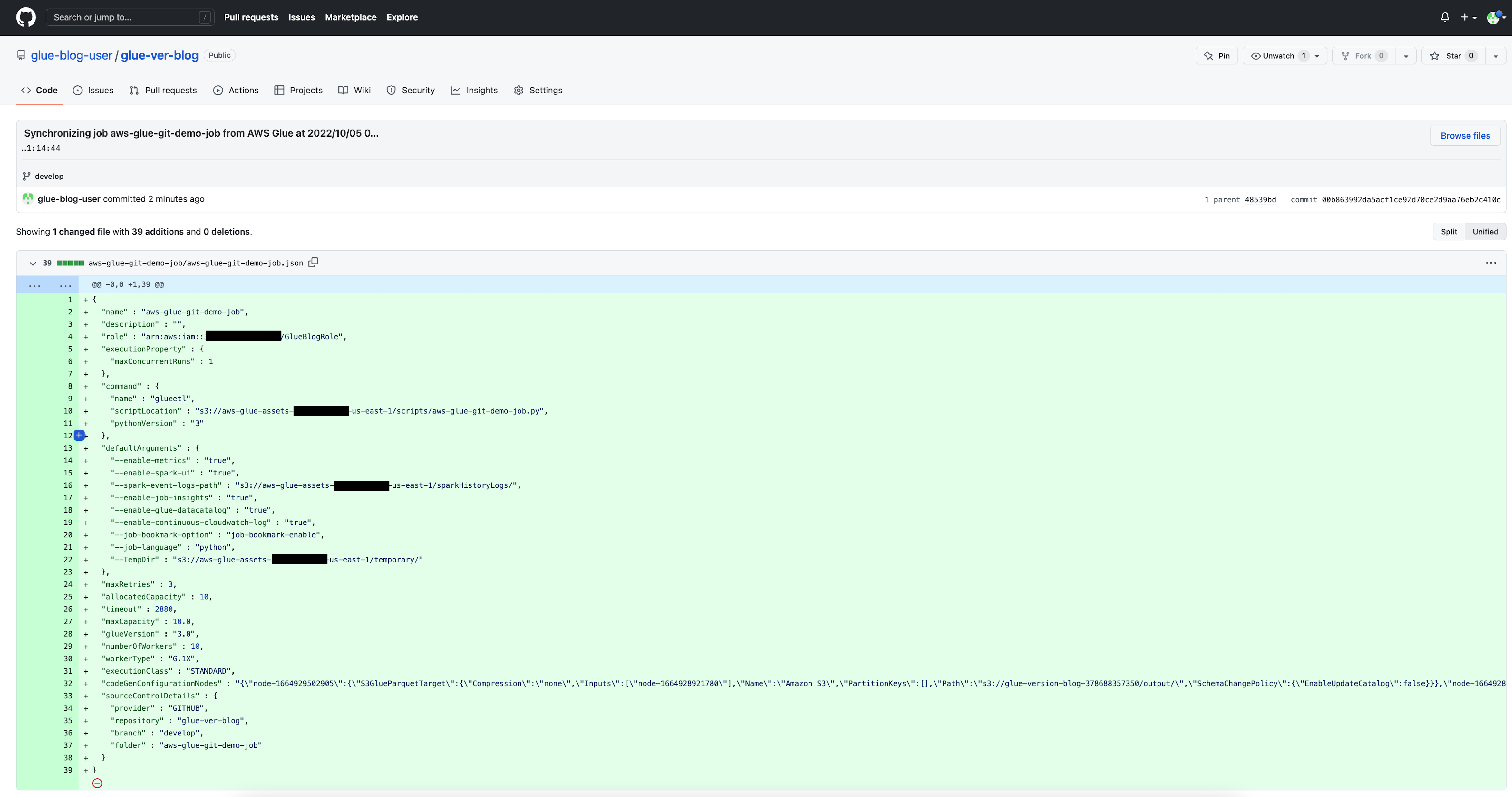
You have successfully created your first commit to GitHub from AWS Glue Studio!
Pull from the repository
Now that we have committed the AWS Glue job to GitHub, it’s time to see how we can pull changes using AWS Glue Studio. For this demo, we make a small modification in our example job using the GitHub UI and then pull the changes using AWS Glue Studio.
- On GitHub, choose the
developbranch.

- Choose the
aws-glue-git-demo-jobfolder.

- Choose the
aws-glue-git-demo-job.jsonfile.

- Choose the edit icon.

- Set the
MaxRetriesparameter to1. - Choose Commit changes.
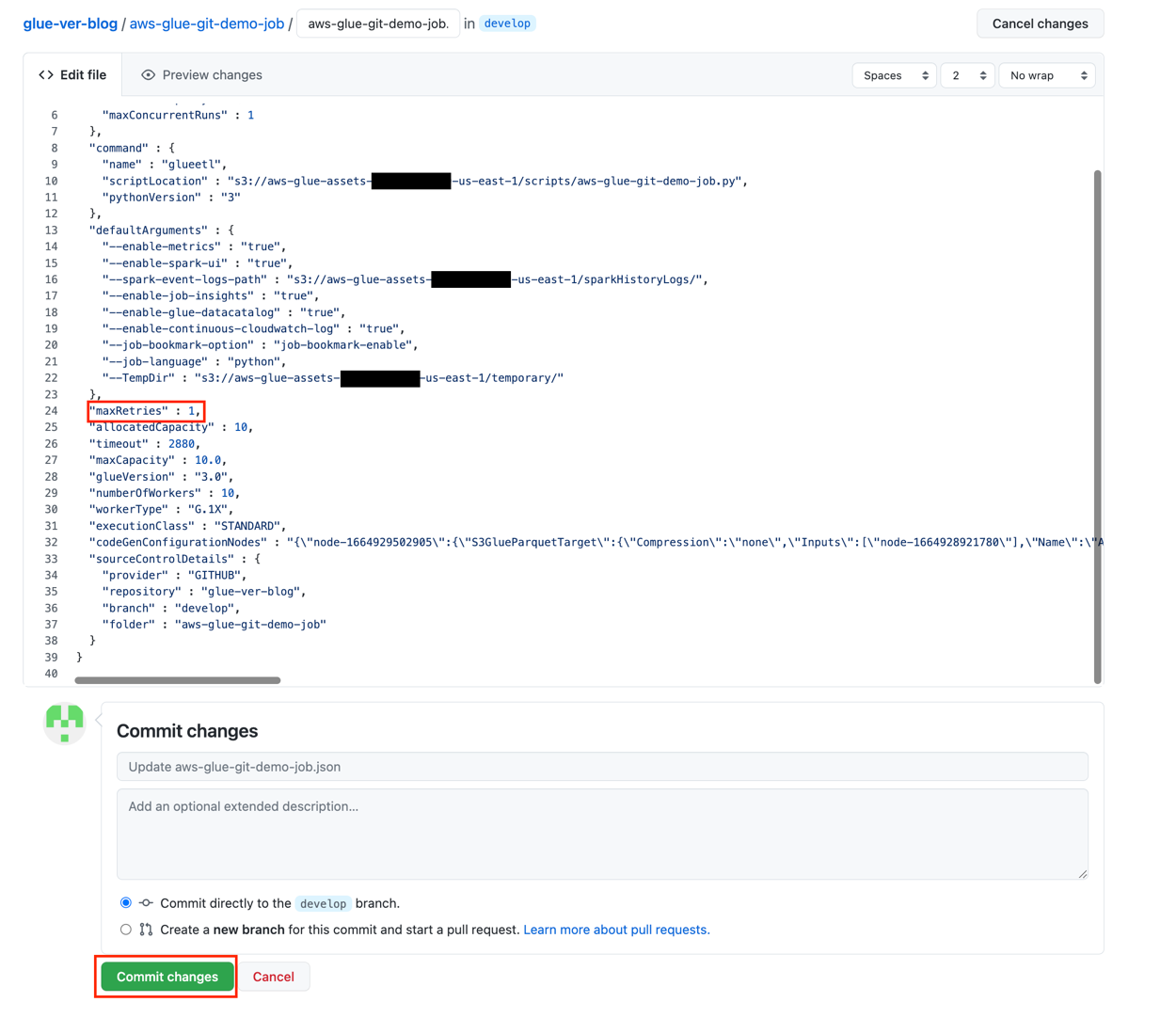
- Return to the AWS Glue console and on the Actions menu, choose Pull from repository.

- Choose Confirm.


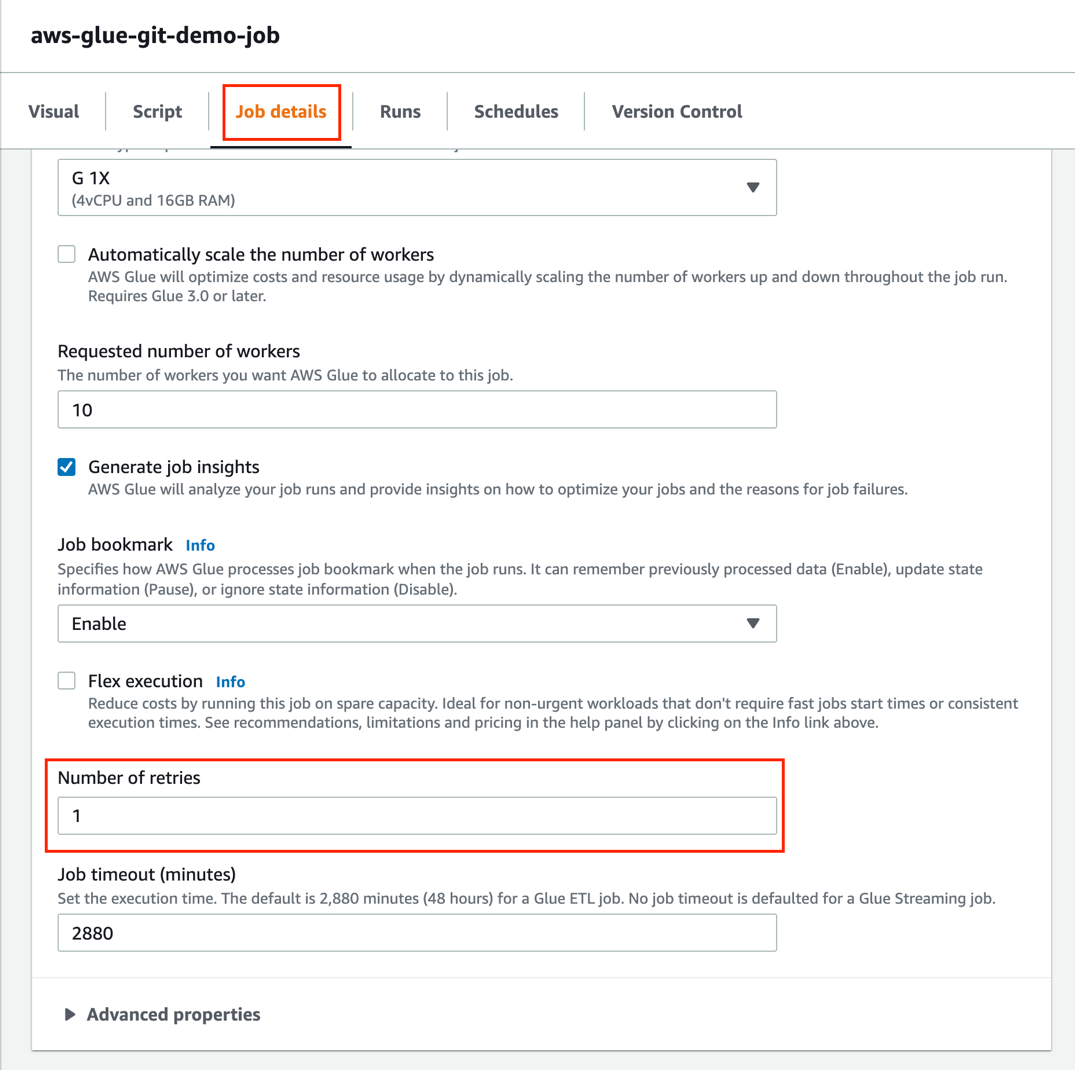
Notice that the commit ID has changed.

On the Job details tab, you can see that the value for Number of retries is 1.
Clean up
To avoid incurring future charges, and to clean up unused roles and policies, delete the resources you created: the datasets, CloudFormation stack, S3 bucket, AWS Glue job, AWS Glue database, and AWS Glue table.
Conclusion
This post showed how to integrate AWS Glue with GitHub, but this is only the beginning—now you can use the most popular functionalities offered by Git.
To learn more and get started using the AWS Glue Studio Git integration, refer to Configuring Git integration in AWS Glue.
About the authors
 Leonardo Gómez is a Senior Analytics Specialist Solutions Architect at AWS. Based in Toronto, Canada, he has over a decade of experience in data management, helping customers around the globe address their business and technical needs.
Leonardo Gómez is a Senior Analytics Specialist Solutions Architect at AWS. Based in Toronto, Canada, he has over a decade of experience in data management, helping customers around the globe address their business and technical needs.
 Daiyan Alamgir is a Principal Frontend Engineer on AWS Glue based in New York. He leads the AWS Glue UI team and is focused on building interactive web-based applications for data analysts and engineers to address their data integration use cases.
Daiyan Alamgir is a Principal Frontend Engineer on AWS Glue based in New York. He leads the AWS Glue UI team and is focused on building interactive web-based applications for data analysts and engineers to address their data integration use cases.