AWS Big Data Blog
Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena
Salesforce is a popular and widely used customer relationship management (CRM) platform. It lets you store and manage prospect and customer information—like contact info, accounts, leads, and sales opportunities—in one central location. You can derive a lot of useful information by combining the prospect information stored in Salesforce with other structured and unstructured data in your data lake.
In this post, I show you how to use AWS Glue to extract data from a Salesforce.com account object and save it to Amazon S3. You then use Amazon Athena to generate a report by joining the account object data from Salesforce.com with the orders data from a separate order management system.
Preparing your data
I signed up for a free Salesforce.com account, which comes with a handful of sample records populated with many of the Salesforce.com objects. You can use your organization’s development Salesforce.com account and pull data from multiple objects at the same time by modifying the SOQL query in your AWS Glue code. To demonstrate extracting data from these objects, only use the Account object to keep the query simple.
To demonstrate joining Salesforce.com data with data from another system using Amazon Athena, you create a sample data file showing orders coming from an order management system.
Setting up an AWS Glue job
Use the open source springml library to connect Apache Spark with Salesforce.com. The library comes with plenty of handy features that allow you to read, write, and update Salesforce.com objects using the Apache Spark framework.
You can compile the jars from the springml GitHub repo or download with dependencies from the Maven repo. Upload these JAR files to your S3 bucket and make a note of the full path for each.
In the AWS Management Console, choose AWS Glue in the Region where you want to run the service. Choose Jobs, Add Job. Follow the wizard by filling in the necessary details.
Under the Security configuration, script libraries, and job parameters (optional) section, for Dependent jars path, list the paths for the four JAR files listed previously, separated by commas.
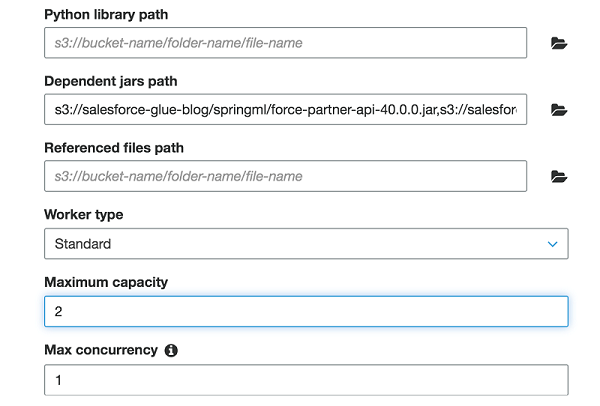
For this job, I allocated Maximum capacity as “2.” This field defines the number of AWS Glue data processing units (DPUs) that the system can allocate when this job runs. A DPU is a relative measure of processing power that consists of four vCPUs of compute capacity and 16 GB of memory. When you specify an Apache Spark ETL job, you can allocate 2–100 DPUs. The default is 10 DPUs.
Execute the AWS Glue job to extract data from the Salesforce.com object
The following Scala code extracts a few fields from the Account object in Salesforce.com and writes them as a table to S3 in Apache Parquet file format.
This code relies on a few key components:
This code example establishes a Salesforce.com connection, submits a SOQL-compatible query for the Account object, and loads the returned records into a Spark DataFrame. Don’t forget to replace username with your Salesforce.com username and password as a combination of your password and the security token of your profile.
Best practices suggest storing and retrieving the password using AWS Secrets Manager instead of hardcoding it. For simplicity, I left it hardcoded in this example.
Keep in mind that this query is simple and returns only a handful of records. For large volumes of data, you might want to limit the results returned by your query or use other techniques like bulk query and chunking. Check the springml page to learn more about the functionality that Salesforce.com supports.
This code does all the writing to your S3 bucket. In this example, you want to aggregate data by Industry segments. Because of that, you should partition the data by the Industry field.
Also, the code writes in Parquet format. Athena charges you by the amount of data scanned per query. You can save on costs and get better performance when you partition the data, compress data, or convert it to columnar formats like Parquet.
After you run this code in AWS Glue, you can go to your S3 bucket where the sink points and find something like the following structure:
Query the data with Athena
After the code drops your Salesforce.com data into your S3 bucket with the correct partition and format, AWS Glue can crawl the dataset. It creates the appropriate schema in the AWS Glue Data Catalog. Wait for AWS Glue to create the table. Then, Athena can query the table and join with other tables in the catalog.
First, use the AWS Glue crawler to discover the Salesforce.com Account data that you previously stored in the S3 bucket. For details about how to use the crawler, see populating the AWS Glue Data Catalog.
In this example, point the crawler to the S3 output prefix where you stored your Salesforce.com Account data, and run it. The crawler creates a new catalog table before it finally stops.
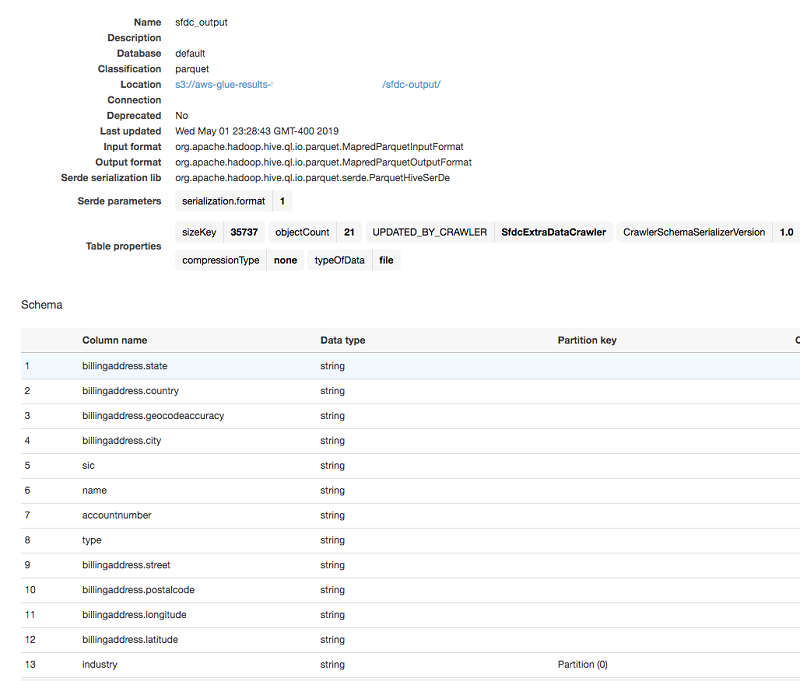
The AWS Glue Data Catalog table automatically captures all the column names, types, and partition column used, and stores everything in your S3 bucket in Parquet file format. You can now query this table with Athena. A simple SELECT query on that table shows the results of scanning the data from the S3 bucket.

Now your Salesforce.com data is ready for Athena to query. For this example, join this data with the sample orders from this sample order management system in S3. After your AWS Glue crawler finishes cataloging the sample orders data, Athena can query it.
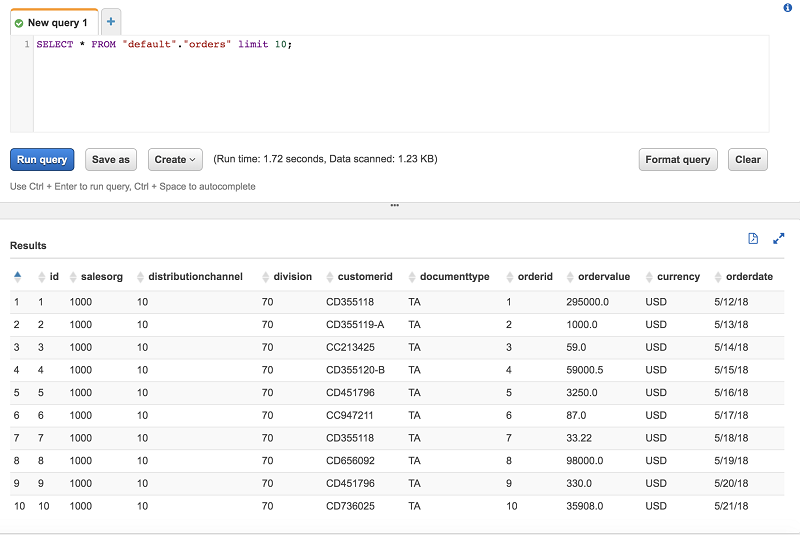
Finally, use Athena to join both tables in an aggregation query.
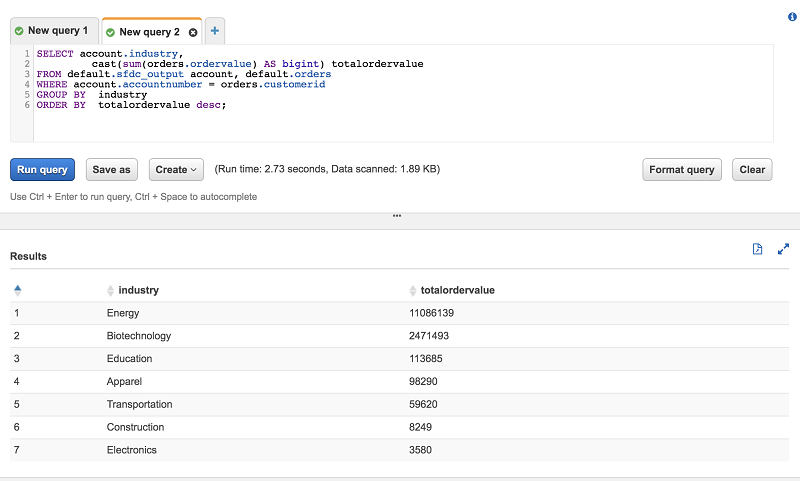
Conclusion
In this post, I showed a simple example for extracting any Salesforce.com object data using AWS Glue and Apache Spark, and saving it to S3. You can then catalog your S3 data in AWS Glue Data Catalog, allowing Athena to query it. With this mechanism in place, you can easily incorporate Salesforce data into your AWS based data lake.
If you have comments or feedback, please leave them below.
About the Author

Behram Irani is a Data Architect at Amazon Web Services.