AWS Big Data Blog
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
This post is co-written with Moshiko Ben Abu, Software Engineer at CyberArk.
CyberArk achieved up to 95% reduction in case resolution time using Amazon Bedrock and Apache Iceberg.
This improvement addresses a challenge in technical support workflow: when a support engineer receives a new customer case, the biggest bottleneck is often not diagnosing the problem but preparing the data. Customer logs arrive in different formats from multiple vendors, and each new log format typically requires manual integration and correlation before an investigation can begin. For simple cases, this process can take hours. For more complex investigations, it can take days, slowing resolution and reducing overall engineer productivity.
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments.
In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.
To achieve these results, CyberArk needed a solution that could ingest customer logs, automatically structure them, establish relationships between related events, and make everything queryable in minutes, not days. The architecture had to be serverless to handle unpredictable support volumes, secure enough to protect customer Personally Identifiable Information (PII), and fast enough to allow same day case resolution.
The legacy architecture: Bottlenecks and manual workflows
When support engineers received customer cases, they would upload log files to the data lake stored in Amazon Simple Storage Service (Amazon S3). The original design then suffered from the complexity of multi-step raw data processing.
First, CyberArk’s custom parsing logic running on AWS Fargate would parse these uploaded log files and transform the raw data. During this stage, the system also had to scan for PII and mask sensitive data to protect customer privacy.
Next, a separate process converted the processed data into Parquet format.
Finally, AWS Glue crawlers were required to discover new partitions and update table metadata for processed Parquet files. This dependency became the most complex and time-consuming part of the pipeline. Crawlers ran as asynchronous batch jobs rather than in real time, often introducing delays of minutes to hours before support engineers could query the data.
But the inefficiency went deeper than just architectural complexity. CyberArk supports customers running diverse product environments across multiple vendors. Each vendor and product produces logs in different formats with unique schemas, field names, and structures. Adding support for a new vendor meant days of integration work to understand their log format and build custom parsers.
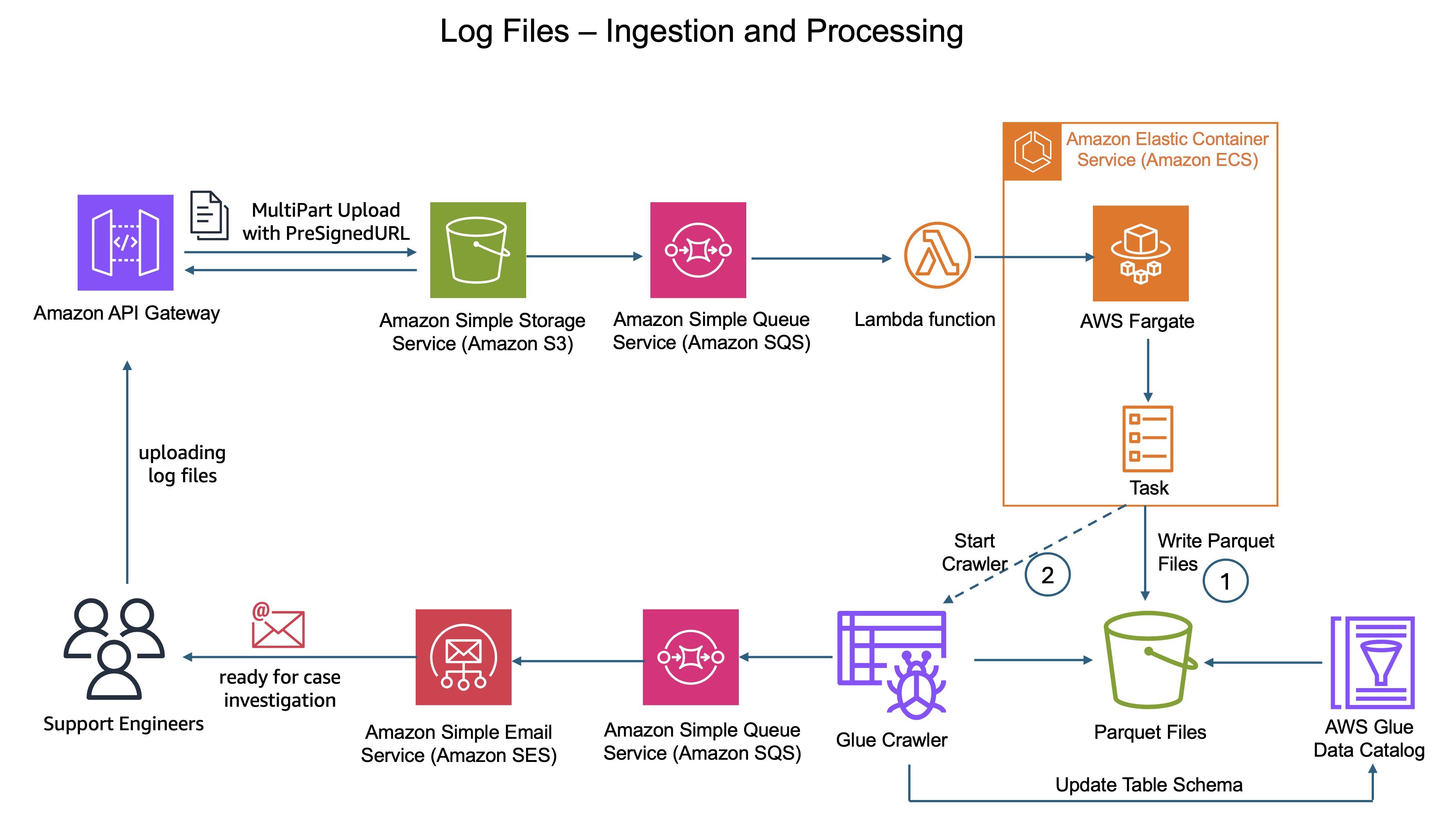
Figure 1: Legacy log ingestion architecture diagram showing the flow from S3 upload through AWS Fargate processing with AWS Glue Crawler
Beyond ingestion, the investigation process itself was manual and time consuming. Support engineers would manually query data, correlate events across different log sources, search through product documentation, and piece together root cause analysis through trial and error. This process required deep product expertise and could take hours or days depending on issue complexity. The new architecture addresses these inefficiencies through three key innovations:
- Single stage serverless processing: AWS Fargate with PyIceberg directly creates Iceberg tables from raw logs in one pass, removing intermediate processing steps and crawler dependencies entirely.
- AI powered dynamic parsing: Amazon Bedrock automatically generates grok patterns for log parsing by analyzing file schemas, transforming what was once a manual, time consuming process into a fully automated workflow.
- Autonomous investigation with AI Agents: AI Agents autonomously perform complete root cause analysis by querying log data, analyzing product knowledge bases, identifying event flows, and recommending solutions, transforming hours of manual investigation into minutes of automated intelligence.
The solution: AI-powered automation meets single-stage Iceberg processing
The new system delivers zero touch log processing from upload to query. Support engineers simply upload customer log ZIP files to the system. Here’s where the transformation happens: CyberArk’s custom processing logic still runs on AWS Fargate, but now it uses Amazon Bedrock to intelligently understand the data.
Zero-touch log processing workflow
The system extracts sample log entries from the uploaded log files and sends them to Amazon Bedrock along with context about the log source and table schema from AWS Glue Data Catalog. Amazon Bedrock analyzes the samples, understands the structure, and automatically generates grok patterns optimized for the specific log format.
Grok patterns are structured expressions that define how to extract meaningful fields from unstructured log text. For example, the following grok pattern specifies that a timestamp appears first, followed by a severity level, then a message body %{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:severity} %{GREEDYDATA:message}
The system validates these grok patterns against additional samples to verify accuracy before applying them to parse the complete log file. Successfully validated grok patterns are stored in Amazon DynamoDB, creating a repository of known patterns. When the system encounters similar log formats in future uploads, it can retrieve these patterns directly from Amazon DynamoDB, avoiding redundant grok pattern generation. Amazon Bedrock processes log samples in real-time without retaining customer data or using it for model training, maintaining data privacy.
This entire process invokes Claude 3.7 Sonnet model from Amazon Bedrock and is orchestrated by AWS Fargate tasks with retry logic for reliability. The processing uses these AI-generated grok patterns to parse the logs and create or update Iceberg tables using PyIceberg APIs without human intervention.
This automation reduced logs onboarding time from days to minutes, enabling CyberArk to handle diverse customer environments without manual intervention.
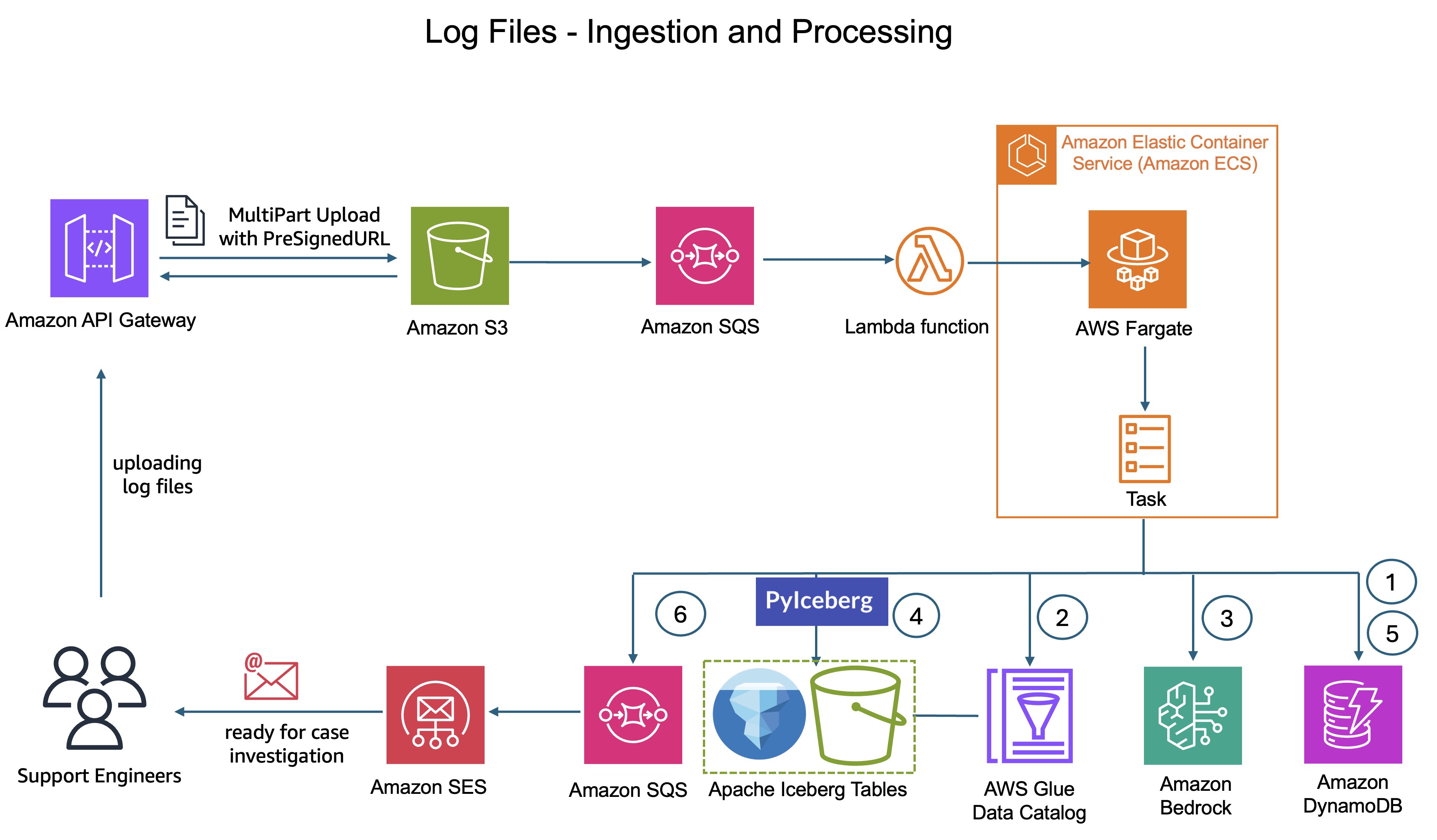
Figure 2: Log ingestion architecture diagram showing the flow from S3 upload through AWS Fargate processing with Amazon Bedrock integration to Iceberg table creation
Apache Iceberg: Simplified architecture, faster queries
Iceberg simplified and improved CyberArk’s data lake architecture by addressing the two primary bottlenecks in the legacy system: slow schema management and inefficient query performance.
Built-in schema evolution removes crawler dependency
In the legacy architecture, AWS Glue crawlers became a source of operational overhead and latency. Even when triggered on demand, crawlers ran as batch jobs over S3 prefixes to discover partitions and update metadata. As data volumes grew and datasets diversified across vendors and schemas, teams had to manage and operate a growing number of crawler jobs. The resulting delays, often ranging from minutes to hours, slowed data availability and downstream investigation workflows.
Iceberg removes this entire layer of complexity. Iceberg’s intelligent metadata layer automatically tracks table structure, schema changes, and partition information as data is written. When CyberArk’s processing creates or updates Iceberg tables through PyIceberg, the metadata is updated instantly and atomically. There’s no waiting for crawlers jobs to complete, and no risk of stale metadata. The moment data is written, it’s immediately queryable in Amazon Athena.
PyIceberg: Making Iceberg accessible beyond Apache Spark
Working with Iceberg usually involved Apache Spark and the complexity of distributed data processing. PyIceberg changed that by letting CyberArk create and manage Iceberg tables using a simple Python library. CyberArk’s data engineers could write straightforward Python code running on AWS Fargate to create Iceberg tables directly from parsed logs, without spinning up Spark clusters.
This accessibility was essential for CyberArk’s serverless architecture. PyIceberg enabled single stage processing where AWS Fargate tasks could parse logs, apply PII masking, and create Iceberg tables in one pass. The result was simpler code and lower operational overhead.
Metadata-driven query optimization delivers speed
In addition to removing crawlers, Iceberg significantly improved query performance through its intelligent metadata architecture. Iceberg maintains detailed statistics about data files, including min/max values, null counts, and partition information. When support engineers query data in Athena, Iceberg’s metadata layer supports partition pruning and file skipping, making sure queries only read the specific files containing relevant data. For CyberArk’s use case, where tables are partitioned by case ID, this means a query for a specific support case only reads the files for that case, ignoring potentially thousands of irrelevant files. This metadata driven optimization reduced query execution time from minutes to seconds, allowing support engineers to interactively explore data rather than waiting for results.
ACID transactions maintain data consistency
In a multi user support environment where multiple engineers may be analyzing overlapping cases or uploading logs simultaneously, data consistency is essential. Iceberg’s ACID transaction support helps verify that concurrent writes do not corrupt data or create inconsistent states. Each table update is atomic, isolated, and durable, providing the reliability CyberArk needed for production support operations.
Time travel enables historical analysis
Iceberg’s built-in versioning allows support engineers to query historical states of data, essential for understanding how customer issues evolved over time. If an engineer needs to see what the logs looked like when a case was first opened versus after a customer applied a patch, Iceberg’s time travel capabilities make this straightforward. This feature proved essential for complex troubleshooting scenarios where understanding the timeline of events was critical to resolution.
Automated table optimization with AWS Glue
Iceberg tables require periodic maintenance to maintain query performance.
CyberArk enabled AWS Glue automatic table optimization for their Iceberg tables, which handles compaction and expired snapshot cleanup in the background.
For CyberArk’s continuous upload workflow, this automation avoids performance degradation over time. Tables stay optimized without manual intervention from the engineering team.
AI Agents: Autonomous investigation workflow
While the Claude 3.7 Sonnet model from Amazon Bedrock automates grok pattern generation for log ingestion, the more advanced use of Amazon Bedrock comes in the investigation workflow. We use AI agents with Bedrock models to change how support engineers analyze and resolve customer issues.
From manual analysis to AI powered investigation
In the legacy workflow, support engineers would manually query data, correlate events across different log sources, search through product documentation, and piece together root cause analysis through trial and error. This process required deep product expertise and could take hours or days depending on issue complexity. AI Agents automate this entire investigation process. Support engineers use an internal portal to ask questions in natural language about customer issues, questions like
“Show me authentication errors for case 12345 in the last 24 hours”, “What were the most common errors across cases opened this week?” or “Compare the error patterns between case 12345 and case 12346.”
Behind the scenes, the system fires specialized AI Agents that autonomously perform thorough analysis.
How support agents work
Each AI Agent operates as an intelligent investigator with a clear mission: understand what happened, determine why it happened, and recommend how to fix it. When a support engineer asks a question, the agent collects relevant data by querying Athena to retrieve log data from Iceberg tables, filtering for the specific case and time period relevant to the investigation. The agent then accesses CyberArk’s internal knowledge base for the specific product involved, understanding known issues, common error patterns, and documented solutions. The agent then performs the following analysis:
- Flow identification: Analyzes the sequence of events in the logs to understand what actually happened during the customer’s issue
- Root cause determination: Correlates log events with product knowledge to identify the underlying cause of the problem
- Solution recommendations: Suggests specific remediation steps based on the root cause analysis and known resolution patterns
This entire process happens in minutes, delivering advanced analysis that would have taken support engineers hours to perform manually.
For complex cases where a solution is not found, the support agent escalates to another, specialized agent that interacts with service engineers to collect additional inputs and expertise. This human-in-the-loop approach makes sure that even the most challenging cases receive appropriate attention while still benefiting from the automated investigation workflow. The insights gathered from these escalated cases are automatically fed back into CyberArk’s knowledge base, continuously improving the system’s ability to handle similar issues autonomously in the future.
Amazon Bedrock never shares customer data with model providers or uses it to train foundation models, case data and investigation insights remain within CyberArk’s environment.
Concurrent agent execution at scale
When multiple support engineers investigate different cases simultaneously, the solution runs specialized agents concurrently. CyberArk currently uses Claude 3.7 Sonnet as the foundation model for these agents. Each agent works independently on its assigned investigation, operating in parallel without resource contention. This concurrent execution allows the investigation workflow to scale automatically with support volume, handling peak loads without performance degradation.
AI-powered investigation advantage
This AI-powered investigation workflow delivers two key advantages.
Investigations that took hours now complete in minutes, enabling support engineers to resolve up to 4x more cases per day.
The system also creates a continuous learning feedback loop. When cases require manual resolution by engineers, these resolutions are automatically recorded and fed back into the knowledge base. Future investigations benefit from this accumulated expertise, with agents applying lessons learned from previous manual resolutions to similar cases. Amazon Bedrock doesn’t use customer data to train foundation models. Case data and investigation insights remain within CyberArk’s environment.
This automated feedback mechanism means the investigation workflow becomes more effective over time, continuously improving resolution accuracy and speed.
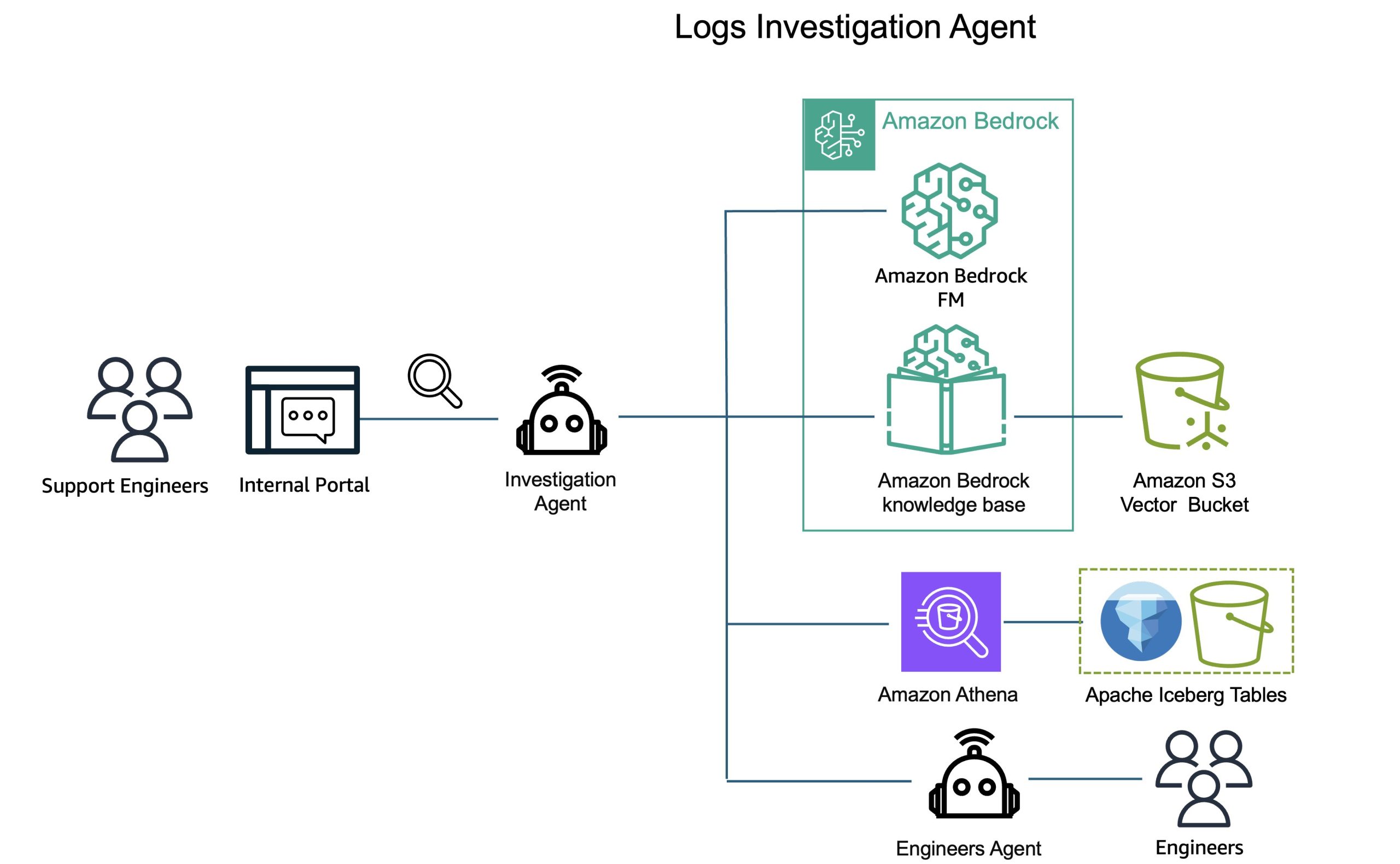
Figure 3: Investigation workflow diagram showing natural language query through AI Agents to Athena queries and knowledge base analysis
Scaling without proportional engineering growth
The business impact of this AI automation is significant. CyberArk can expand its vendor coverage and product portfolio without adding data engineering headcount. The same system that handles today’s log types will automatically handle tomorrow’s additions, whether that’s ten new formats or thousands, significantly reducing time to market for new product and vendor integrations.
The results: Significant improvements in resolution time and productivity
The transformation delivered measurable improvements across every key metric.
Resolution time: CyberArk achieved up to 95% reduction in time from case assignment to resolution. Simple cases that used to take 4 to 6 hours now take just 15 to 30 minutes. Complex cases that previously took up to 15 days are now completed in 2 to 4 hours.
Engineer productivity: Support engineers now handle 8 to 12 cases per day, compared to just 2 to 3 cases before. This means each engineer is helping up to 4x more customers.
Data availability: Logs are queryable within minutes of upload instead of waiting hours or days. Support engineers can start investigating issues almost immediately after receiving customer data.
Operational efficiency: The system requires zero manual intervention for new log formats or schema changes. Cases that used to require days of data engineering work now happen automatically.
Cost optimization: The serverless architecture alleviated idle infrastructure costs while scaling automatically with demand. CyberArk only pays for what they use, when they use it.
Customer satisfaction: Faster resolution times and proactive issue identification significantly improved the customer experience. Problems get solved in hours instead of days, and customers spend less time waiting for answers.
What’s next?
While AWS continues to innovate across both data lake management and agentic AI infrastructure, the following capabilities align well with CyberArk’s architecture and may offer additional operational benefits as the system scale.
Agent infrastructure maturity
As the agent-based architecture scales to handle thousands of concurrent investigations, CyberArk is transitioning to Amazon Bedrock AgentCore for future agent deployments. AgentCore provides a managed runtime for production AI agents with enhanced observability through AWS X-Ray integration, intelligent memory for context retention across sessions, and streamlined operational workflows. While the current AI Agents implementation delivers the performance and reliability CyberArk needs today, AgentCore represents a natural evolution path as operational requirements grow, offering framework-agnostic deployment, automatic scaling, and comprehensive monitoring capabilities without infrastructure management overhead.
Amazon S3 Tables
CyberArk’s current architecture uses Iceberg tables stored in Amazon S3 buckets. Amazon S3 Tables offers fully managed Iceberg tables with built-in optimization.
As CyberArk continue to scale with hundreds of Iceberg tables and rapid data growth, CyberArk is exploring a migration to Amazon S3 Tables to further reduce operational overhead.
S3 Tables remove the need to set up and monitor AWS Glue maintenance jobs. It automatically performs maintenance to enhance the performance of Iceberg tables, including unreferenced file removal, file compaction, and snapshot management. Additionally, S3 Tables provides Intelligent-Tiering that automatically moves data between storage classes based on access patterns, optimizing storage costs without manual intervention.
Because S3 Tables uses Iceberg open table format, migration would not require changes to existing Athena queries and PyIceberg code. This flexibility allows CyberArk to evaluate and adopt S3 Tables when the operational and cost benefits align with their business needs.
Conclusion
CyberArk’s transformation demonstrates how combining modern data lake architecture with AI automation can significantly change operational economics. By combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock, CyberArk transformed case resolution from days to minutes while enabling support operations to scale automatically with business growth. Support engineers now spend their time solving customer problems instead of wrangling data, customers receive faster resolutions, and the system scales automatically with the business.
To learn more about Iceberg on AWS, refer to Working with Amazon S3 Tables and table buckets and Using Apache Iceberg on AWS. To learn more about Amazon Bedrock AgentCore, refer to Amazon Bedrock AgentCore.