AWS Big Data Blog

How Edmunds GovTech unifies data and analytics data for municipalities with Amazon QuickSight
This is a guest post from an Amazon QuickSight customer, Edmunds GovTech Over the past 30 years, Edmunds GovTech has grown to provide enterprise resource planning (ERP) solutions to thousands of East Coast municipalities. We also serve cities and towns in 25 other states. In this blog, I’ll talk about how we used Amazon QuickSight […]
Data monetization and customer experience optimization using telco data assets: Part 2
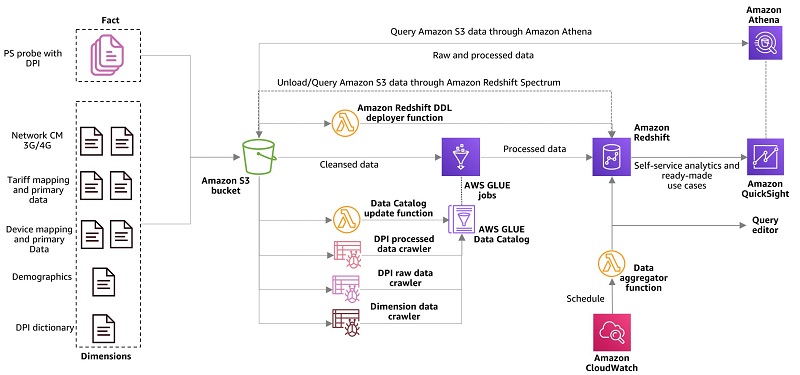
Part 1 of this series explains the importance of building and implementing a customer experience (CX) management and data monetization strategy for telecom service providers (TSPs), and the major challenges driving these initiatives. It also includes an AWS CloudFormation template to set up a demonstration of the solution using AWS services. It covers transforming and enriching […]

Building a cost efficient, petabyte-scale lake house with Amazon S3 lifecycle rules and Amazon Redshift Spectrum: Part 2
In part 1 of this series, we demonstrated building an end-to-end data lifecycle management system integrated with a data lake house implemented on Amazon Simple Storage Service (Amazon S3) with Amazon Redshift and Amazon Redshift Spectrum. In this post, we address the ongoing operation of the solution we built. Data ageing process after a month […]

Centrally tracking dashboard lineage, permissions, and more with Amazon QuickSight administrative dashboards
This post is co-written with Shawn Koupal, an Enterprise Analytics IT Architect at Best Western International, Inc. A common ask from Amazon QuickSight administrators is to understand the lineage of a given dashboard (what analysis is it built from, what datasets are used in the analysis, and what data sources do those datasets use). QuickSight […]
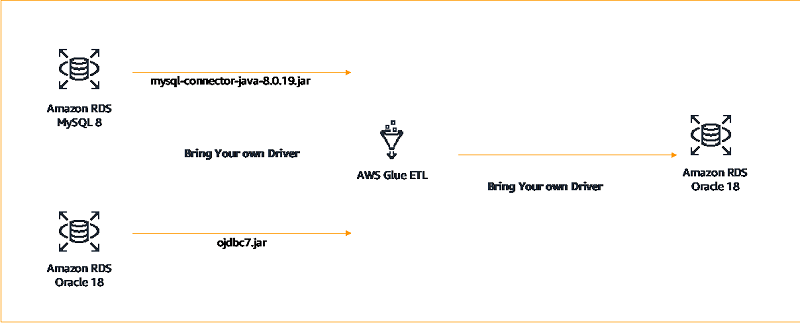
Building AWS Glue Spark ETL jobs by bringing your own JDBC drivers for Amazon RDS
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue has native connectors to connect to supported data sources either on AWS or elsewhere using JDBC drivers. Additionally, AWS Glue now enables you to bring your own JDBC drivers […]

Developing, testing, and deploying custom connectors for your data stores with AWS Glue
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue already integrates with various popular data stores such as the Amazon Redshift, RDS, MongoDB, and Amazon S3. Organizations continue to evolve and use a variety of data stores that best fit […]

Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors
July, 2022: This post was reviewed and updated to include a mew data point on the effective runtime with the latest version, explaining Glue 3,0 and autoscaling. October, 2024: In Glue 4.0 we have introduced a native and managed connector for Google BigQuery. You can follow the instruction in the blog postUnlock scalable analytics with […]

Building AWS Glue Spark ETL jobs using Amazon DocumentDB (with MongoDB compatibility) and MongoDB
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue has native connectors to connect to supported data sources on AWS or elsewhere using JDBC drivers. Additionally, AWS Glue now supports reading and writing to Amazon DocumentDB (with MongoDB […]

Amazon Redshift 2020 year in review
Today, more data is created every hour than in an entire year just 20 years ago. Successful organizations are leveraging this data to deliver better service to their customers, improve their products, and run an efficient and effective business. As the importance of data and analytics continues to grow, the Amazon Redshift cloud data warehouse […]

Writing to Apache Hudi tables using AWS Glue Custom Connector
December 2022: This post was reviewed for accuracy. In today’s world, most organizations have to tackle the 3 V’s of variety, volume and velocity of big data. In this blog post, we talk about dealing with the variety and volume aspects of big data. The challenge of dealing with the variety involves processing data from […]