AWS Big Data Blog
Tag: Kafka

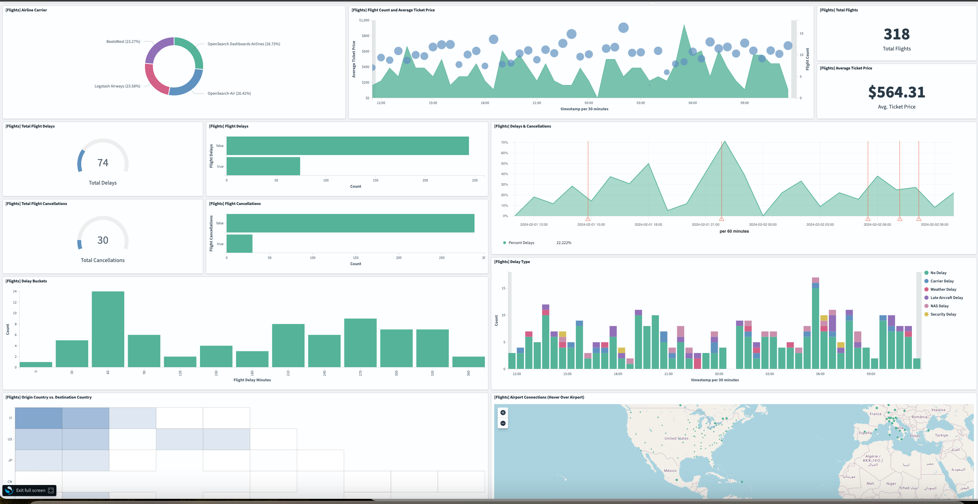
Introducing workload simulation workbench for Amazon MSK Express broker
In this post, we introduce the workload simulation workbench for Amazon Managed Streaming for Apache Kafka (Amazon MSK) Express Broker. The simulation workbench is a tool that you can use to safely validate your streaming configurations through realistic testing scenarios.

Building serverless event streaming applications with Amazon MSK and AWS Lambda
In this post, we describe how you can simplify your event-driven application architecture using AWS Lambda with Amazon MSK. We demonstrate how to configure Lambda as a consumer for Kafka topics, including a cross-account setup and how to optimize price and performance for these applications.
Building a scalable streaming data platform that enables real-time and batch analytics of electric vehicles on AWS
The automobile industry has undergone a remarkable transformation because of the increasing adoption of electric vehicles (EVs). EVs, known for their sustainability and eco-friendliness, are paving the way for a new era in transportation. As environmental concerns and the push for greener technologies have gained momentum, the adoption of EVs has surged, promising to reshape […]

Best practices for running production workloads using Amazon MSK tiered storage
In the second post of the series, we discussed some core concepts of the Amazon Managed Streaming for Apache Kafka (Amazon MSK) tiered storage feature and explained how read and write operations work in a tiered storage enabled cluster. This post focuses on how to properly size your MSK tiered storage cluster, which metrics to […]

Use MSK Connect for managed MirrorMaker 2 deployment with IAM authentication
January 2026: This post was reviewed and updated for accuracy. MSK Connect configurations required for cross-account and same-account replication have been added to show different use cases. March 2025: This post was reviewed and updated for accuracy. MSK Replicator now makes it easier to set up cross-Region and same-Region replication without running MirrorMaker 2. Read AWS News Blog […]
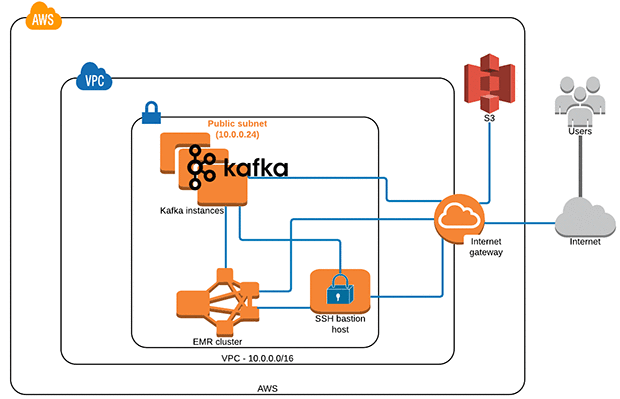
Real-time Stream Processing Using Apache Spark Streaming and Apache Kafka on AWS
This post demonstrates how to set up Apache Kafka on EC2, use Spark Streaming on EMR to process data coming in to Apache Kafka topics, and query streaming data using Spark SQL on EMR.