AWS Big Data Blog
Tag: optimization

Infor’s Amazon OpenSearch Service Modernization: 94% faster searches and 50% lower costs
In this post, we’ll explore Infor’s journey to modernize its search capabilities, the key benefits they achieved, and the technologies that powered this transformation. We’ll also discuss how Infor’s customers are now able to more effectively search through business messages, documents, and other critical data within the ION OneView platform.

Accelerate Amazon Redshift Data Lake queries with AWS Glue Data Catalog Column Statistics
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. In this post, we highlight the performance improvements we observed using industry standard TPC-DS benchmarks. Overall execution time of TPC-DS 3 TB benchmark improved by 3x. Some of the queries in our benchmark experienced up to 12x speed up.

Detect and handle data skew on AWS Glue
October 2024: This post was reviewed and updated for accuracy. AWS Glue is a fully managed, serverless data integration service provided by Amazon Web Services (AWS) that uses Apache Spark as one of its backend processing engines (as of this writing, you can use Python Shell or Spark). Data skew occurs when the data being […]
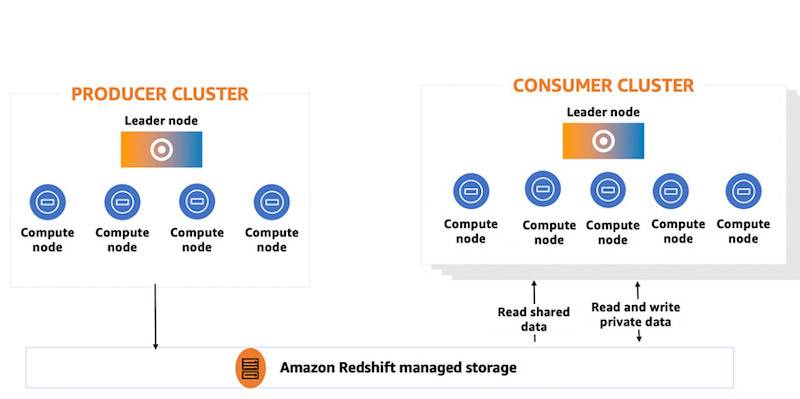
From centralized architecture to decentralized architecture: How data sharing fine-tunes Amazon Redshift workloads
Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price-performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. With the significant growth of data for big […]