AWS Big Data Blog
Use ML predictions over Amazon DynamoDB data with Amazon Athena ML
Today’s modern applications use multiple purpose-built database engines, including relational, key-value, document, and in-memory databases. This purpose-built approach improves the way applications use data by providing better performance and reducing cost. However, the approach raises some challenges for data teams that need to provide a holistic view on top of these database engines, and especially when they need to merge the data with datasets in the organization’s data lake.
In this post, we show how you can use Amazon Athena to build complex aggregations over data from Amazon DynamoDB and enrich the data with ML inference using Amazon SageMaker. You use some of the latest features announced by Athena such as Athena Query Federation, integration with SageMaker for machine learning (ML) predictions, and querying geospatial data in Athena.
For our use case, assume you’re operating a fleet of scooters, and need to forecast whether enough scooters are made available in each part of the city. Specifically, you need to predict the number of scooters needed in each urban neighborhood for the upcoming hour. You have a pre-trained ML model that forecasts the demand for the next hour based on data from the past 4 hours. You use Athena and Amazon QuickSight to predict and visualize the demand, respectively.
Solution overview
The following diagram shows the overall architecture of our solution.
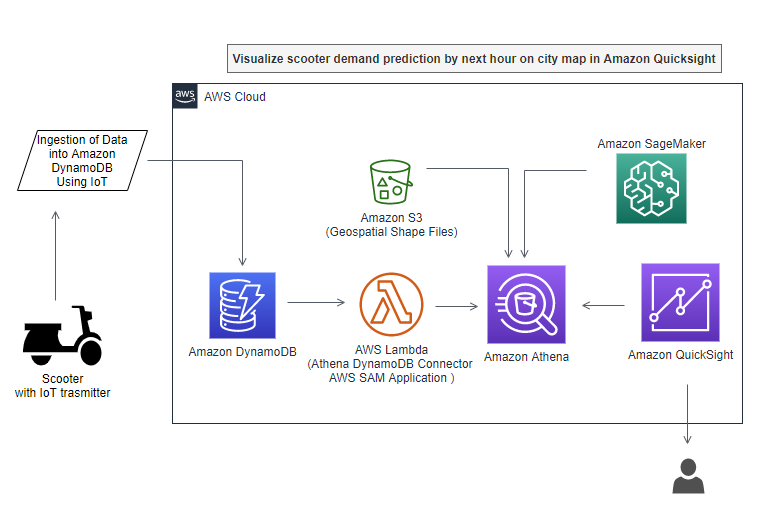
We use the following resources:
- A public dataset of dockless vehicle rentals, provided by the Office of Civic Innovation and Technology of the Louisville (KY) Metro Government. This data is pre-populated in DynamoDB as part of the use case. However, in real life, this data would be sent to DynamoDB through various mechanisms such as internet of things (IoT) devices or Amazon Kinesis consumers, which insert data into DynamoDB via AWS Lambda.
- Boundaries of historical and cultural neighborhoods within the city of Louisville. The public dataset is provided by the Louisville and Jefferson County, KY Information Consortium (LOJIC). You can download the GIS shapefiles directly. We converted original shapefiles into a text file that you can query with Athena. You can find the Python code for transforming shapefiles in the Jupyter notebook https://github.com/aws-samples/dynamodb-ml-prediction-amazon-athena/blob/main/notebook/GeoSpatialProcessingGISshapefilesWithAmazonAthena.ipynb.
- A pre-trained ML model for hourly forecasts. You can find the Python code for training the ML model in the notebook Demand Prediction for scooters using Amazon SageMaker and Amazon Athena.
- A SQL query in Athena that brings everything together for live predictions from the data stored in DynamoDB.
- Optionally, you can use QuickSight to visualize geospatial data over a map of Louisville, Kentucky (see the following example).

Populate DynamoDB with data and create a SageMaker endpoint to query in Athena
For this post, we populate the DynamoDB table with scooter data. For demand prediction, we create a new SageMaker endpoint using a pre-trained XGBoost model using an elastic container registry path from Region us-east-1.
- Choose Launch Stack to launch a CloudFormation stack in
us-east-1.
![]()
- On the CloudFormation console, accept default values for the parameters.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
The stack creates five resources:
- A DynamoDB table
- A Lambda function to load the table with relevant data
- A SageMaker endpoint for inference requests, with the pre-trained XGBoost model from an Amazon Simple Storage Service (Amazon S3) location
- An Athena workgroup named
V2EngineWorkGroup - Named Athena queries to look up the shapefiles and predict the demand for scooters
The CloudFormation template also deploys a pre-built DynamoDB-to-Athena connector, using the AWS Serverless Application Model (AWS SAM).
It can take up to 15–20 minutes for the CloudFormation stack to create these resources.
You can verify the sample data provided by AWS CloudFormation was loaded into DynamoDB by navigating to the DynamoDB console and checking for the table DynamoDBTableDocklessVehicles.

- When resource creation is complete, on the Athena console, choose Workgroups.
- Select the workgroup
V2EngineWorkGroupand choose Switch workgroup. - If you get a prompt to save the query result location, choose an S3 location where you have write permissions.
- Choose Save.
- In the Athena query editor, select the database
athena-ml-db-<your-AWS-Account-Number>.
Now let’s load the geolocation files into the Athena database.
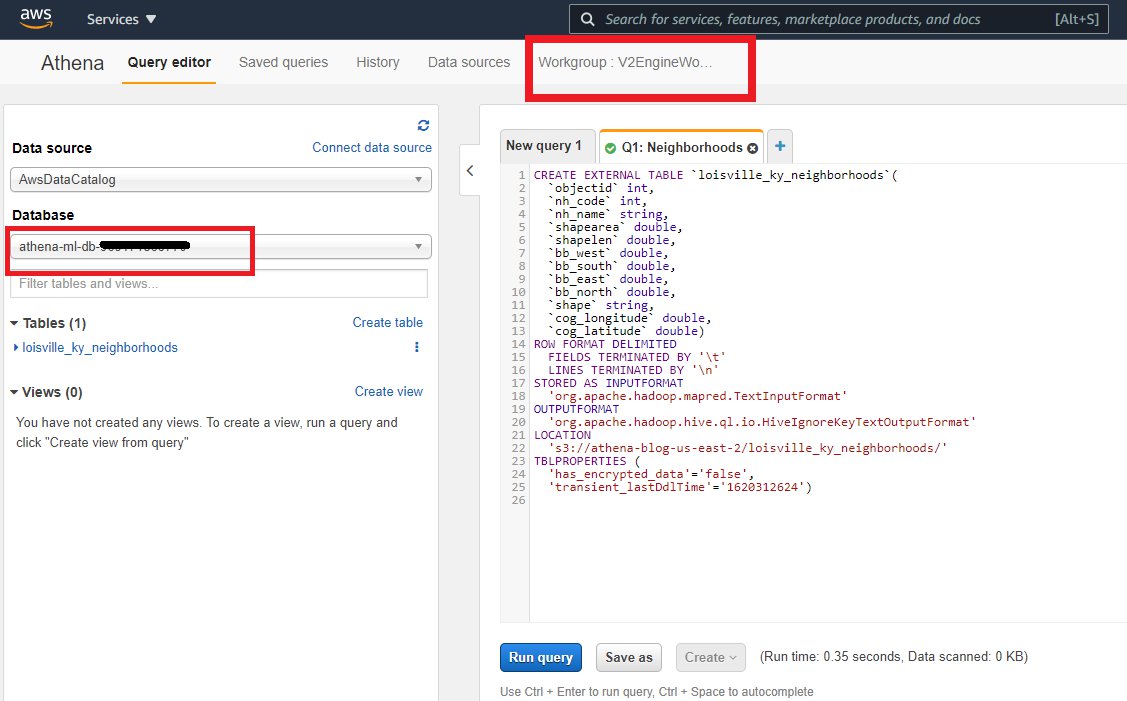
Create an Athena table with geospatial data of neighborhood boundaries
To load the geolocation files into Athena, complete the following steps:
- On the Athena console, choose Saved queries.
- Search for and select Q1: Neighborhoods.
- Return to the Athena SQL window.
This query creates a new table for the geospatial data that represents the urban neighborhoods of the city. The data table has been created from GIS shapefiles. The following CREATE EXTERNAL TABLE statement defines the schema of the table, and the location and format of the underlying data file. You can find the Python code to process shapefiles and produce this table in the notebook Geo-Spatial processing of GIS shapefiles with Amazon Athena.
- Choose Run query or press CTRL+Enter.
This action creates a table named louisville_ky_neighborhoods in your database. Make sure the table is created in the database athena-ml-db-<your-AWS-Account-Number>.
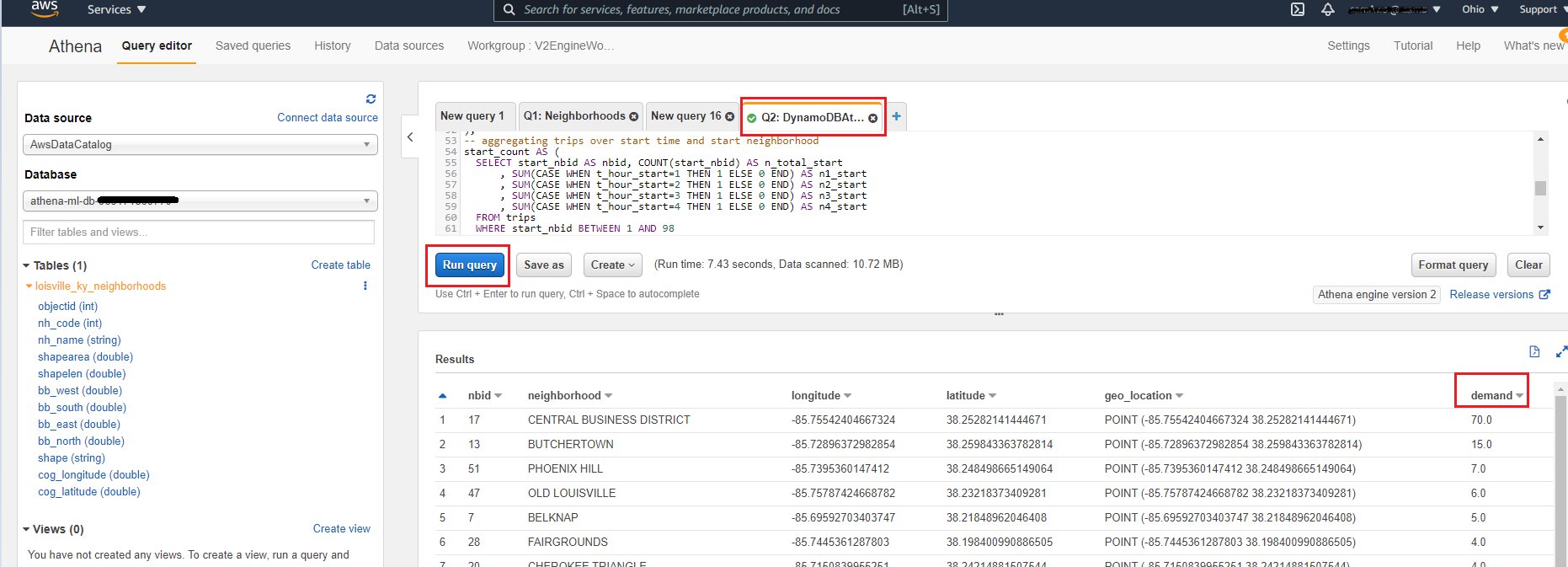
Predict demand for scooters by neighborhood from the aggregated DynamoDB data
Now you can use Athena to query transactional data directly from DynamoDB, and aggregate it for analysis and forecast. This feature isn’t easily achieved by directly querying a DynamoDB NoSQL database.
- On the Athena console, choose Saved queries.
- Search for and select Q2: DynamoDBAthenaMLScooterPredict.
- Return to the Athena SQL window.
This SQL statement demonstrates the use of the Athena Query Federation to query the DyanamoDB table with the raw trip data, Athena’s geospatial functions to place geographic coordinates into neighborhoods, and enrich data with ML inference using SageMaker.
The first part of the SQL statement declares the external function to query ML inferences from the SageMaker endpoint that hosts the pre-trained model. We need to define the order and type of the input parameters and the type of the return values.
We use several sub-queries to build the feature table for ML prediction. With the first SELECT statement, we query the raw data from DynamoDB for a given window. Then we locate the start and end locations of each trip record within their urban neighborhoods. Next, we create two aggregations over time and space for the start and end of the trips and combine them to generate a table with the number of trips per hour that started and ended within each of the neighborhoods. Among a few other parameters, we use the hourly counts for the past 4 hours to predict the demand for vehicles for the next hour. You can find the Python code for training the ML model in the notebook Demand Prediction for scooters using Amazon SageMaker and Amazon Athena.
- Choose Run query or press CTRL+Enter to run the query and predict the demand for scooters.
The output table includes the neighborhood, longitude and latitude of the centroid of the neighborhood, and the number of vehicles that are predicted for the next hour. This query produces the predictions for a selected point in time. You can make predictions for any other time by changing the expression TIMESTAMP '2019-09-07 15:00' everywhere in the statement. Change it to NOW()if you have a real-time data feed from your DynamoDB table.
Visualize predicted demand for scooters in QuickSight
You can use the same Athena query (Q2) to visualize the data in QuickSight. You may have to add additional permissions to your QuickSight role to invoke Lambda functions to access the DynamoDB tables and SageMaker endpoints for the predictions. For detailed instructions on how to set up QuickSight to visualize geo-location coordinates, see the GitHub repo.
As you can see in the following QuickSight visualization, we can spot the demand for scooters on the map of Louisville, Kentucky. Circles with a bigger radius denote higher demand for scooters in that neighborhood. You can also hover over any of the circles to view the detailed demand count and the name of the neighborhood.

With live data, you can also set the refresh rate on your QuickSight dashboard to update the demand prediction automatically.
Clean up
When you’re done, clean up the resources you created as part of this solution.
- On the Amazon S3 console, empty the bucket you created as part of the CloudFormation stack.
- On the AWS CloudFormation console, find stack
bdb-1462-athena-dynamodb-ml-stackand delete the stack. - On the Amazon CloudWatch console, delete the
/aws/sagemaker/Endpoints/Sg-athena-ml-dynamodb-model-endpointlog group.
Conclusion
This post demonstrated how to query data in Athena using the Athena Federated Query feature for DynamoDB, and enrich data with ML inference using SageMaker. We also showed how you can integrate geo-location-based queries, using geospatial features in Athena. The Athena Query Federation feature is very extensible and queries data from multiple data sources such as DynamoDB, Amazon Neptune, Amazon ElastiCache for Redis, and Amazon Relational Database Service (Amazon RDS), and gives you a wide range of possibilities to aggregate data.
About the Authors
 Sachin Doshi is a Senior Application Architect working in the AWS Professional Services team. He is based out of New York metropolitan area. Sachin helps customers optimize their applications using cloud native AWS services.
Sachin Doshi is a Senior Application Architect working in the AWS Professional Services team. He is based out of New York metropolitan area. Sachin helps customers optimize their applications using cloud native AWS services.
 Péter Molnár is a Data Scientist with AWS Professional Services. He develops machine learning and artificial intelligence solutions for customer business problems. He holds a doctorate in Theoretical Physics from the University of Stuttgart (Germany) and a master’s degree in Physics from Georgia Augusta University in Göttingen (Germany).
Péter Molnár is a Data Scientist with AWS Professional Services. He develops machine learning and artificial intelligence solutions for customer business problems. He holds a doctorate in Theoretical Physics from the University of Stuttgart (Germany) and a master’s degree in Physics from Georgia Augusta University in Göttingen (Germany).