AWS Compute Blog
Building a location-based, scalable, serverless web app – part 3
In part 2, I cover the API configuration, geohashing algorithm, and real-time messaging architecture used in the Ask Around Me web application. These are needed for receiving and processing questions and answers, and sending results back to users in real time.
In this post, I explain the backend processing architecture, how data is aggregated, and how to deploy the final application to production. The code and instructions for this application are available in the GitHub repo.
Processing questions
The frontend sends new user questions to the backend via the POST questions API. While the predicted volume of questions is only 1,000 per hour, it’s possible for usage to spike unexpectedly. To help handle this load, the PostQuestions Lambda function puts incoming questions onto an Amazon SQS queue. The ProcessQuestions function takes messages from the Questions queue in batches of 10, and loads these into the Questions table in Amazon DynamoDB.

This asynchronous process smooths out traffic spikes, ensuring that the application is not throttled by DynamoDB. It also provides consistent response times to the front-end POST request, since the API call returns as soon as the message is durably persisted to the queue.
Currently, the ProcessQuestions function does not parse or validate user questions. It would be easy to add message filtering at this stage, using Amazon Comprehend to detect sentiment or inappropriate language. These changes would increase the processing time per question, but by handling this asynchronously, the initial POST API latency is not adversely affected.
The ProcessQuestions function uses the Geo Library for Amazon DynamoDB that converts the question’s latitude and longitude into a geohash. This geohash attribute is one of the indexes in the underlying DynamoDB table. The GetQuestions function using the same library for efficiently querying questions based on proximity to the user.
There are a couple of different mechanisms used to pass information between the frontend and backend applications. When the frontend first initializes, it retrieves the current location of the user from the browser. It then calls the questions API to get a list of active questions within 5 miles of the current location. This retrieves the state up to this point in time. To receive notifications of new messages posted in the user’s area, the frontend also subscribes to the geohash topic in AWS IoT Core.
Processing answers

The application allows two types of question that have different answer types. First, the rating questions accept an answer with a 0–5 score range. Second, the geography questions accept a geo-point, which is a latitude and longitude representing a location.
Similar to the way questions are handled, answers are also queued before processing. However, the PostAnswers Lambda function sends answers to different queues, depending on question type. Ratings messages are sent to the StarAnswers queue, while geography messages are routed to the GeoAnswers queue. Star ratings are saved as raw data in the Answers table by the ProcessAnswerStar function. Geography answers are first converted to a geohash before they are stored.
It’s possible for users to submit updates to their answers. For a star rating, the processing function simply saves the new score. For geography answers, if the updated answer contains a latitude and longitude close enough to the original answer, it results in the same geohash. This is due to the different aggregation processes used for these types of answers.
Aggregating data
In this application, the users asking questions are seeking aggregated answers instead of raw data. For example, “How do you rate the park?” shows an average score from users instead of thousands of individual ratings. To maintain performance, this aggregation occurs when new answers are saved to the database, not when the application fetches the question list.
The Answers table emits updates to a DynamoDB stream whenever new items are inserted or updated. The StreamSpecification parameter in the table definition is set to NEW_AND_OLD_IMAGES, meaning the stream record contains both the new and old item record.
New answers to questions are new items in the table, so the stream record only contains the new image. If users update their answers, this creates an updated item in the table, and the stream record contains both the new and old images of the item.
For star ratings, when receiving an updated rating, the Aggregation function uses both images to calculate the delta in the score. For example, if the old rating was 2 and the user changes this to 5, then the delta is 3. The summary score related to the answer is updated in the Questions table, using a DynamoDB update expression:
const result = await myGeoTableManager.updatePoint({
RangeKeyValue: { S: update },
GeoPoint: {
latitude: item.lat,
longitude: item.lng
},
UpdateItemInput: {
UpdateExpression: 'ADD answers :deltaAnswers, totalScore :deltaTotalScore',
ExpressionAttributeValues: {
':deltaAnswers': { N: item.deltaAnswers.toString()},
':deltaTotalScore': { N: item.deltaValue.toString()}
}
}
}).promise()
For geo-point ratings, the same approach is used but if the geohash changes, then the delta is -1 for the geohash in the old image, and +1 for the geohash in the new image. The update expression automatically creates a new geohash attribute on the DynamoDB item if it is not already present:
const result = await myGeoTableManager.updatePoint({
RangeKeyValue: { S: item.ID },
GeoPoint: {
latitude: item.lat,
longitude: item.lng
},
UpdateItemInput: {
UpdateExpression: `ADD ${item.geohash} :deltaAnswers, answers :deltaAnswers`,
ExpressionAttributeValues: {
':deltaAnswers': { N: item.deltaAnswers.toString() }
}
}
}).promise()
By using a Lambda function as a DynamoDB stream processor, you can aggregate large amounts of data in near real time. The Questions and Answers tables have a one-to-many relationship – many answers belong to one question. As answers are saved, the aggregation process updates the summaries in the Questions table.
The Questions table also publishes updates to another DynamoDB stream. These are consumed by a Lambda function that sends the aggregated update to topics in AWS IoT Core. This is how updated scores are sent back to the frontend client application.
Publishing to production with Amplify Console
At this point, you can run the application on your local development machine and view the application via the localhost Vue.js server. Once you are ready to launch the application to users, you must deploy to production.
Single-page applications are easy to deploy publicly. The build process creates static HTML, JS, and CSS files. These can be served via Amazon S3 and Amazon CloudFront, together with any image and media assets used. The process of running the build process and managing the deployment can be automated using AWS Amplify Console.
In this walk through, I use GitHub as the repo provider. You can also use AWS CodeCommit, Bitbucket, GitLab, or upload the build directory from your machine.
To deploy the front end via Amplify Console:
- From the AWS Management Console, select the Services dropdown and choose AWS Amplify. From the initial splash screen, choose Get Started under Deploy.

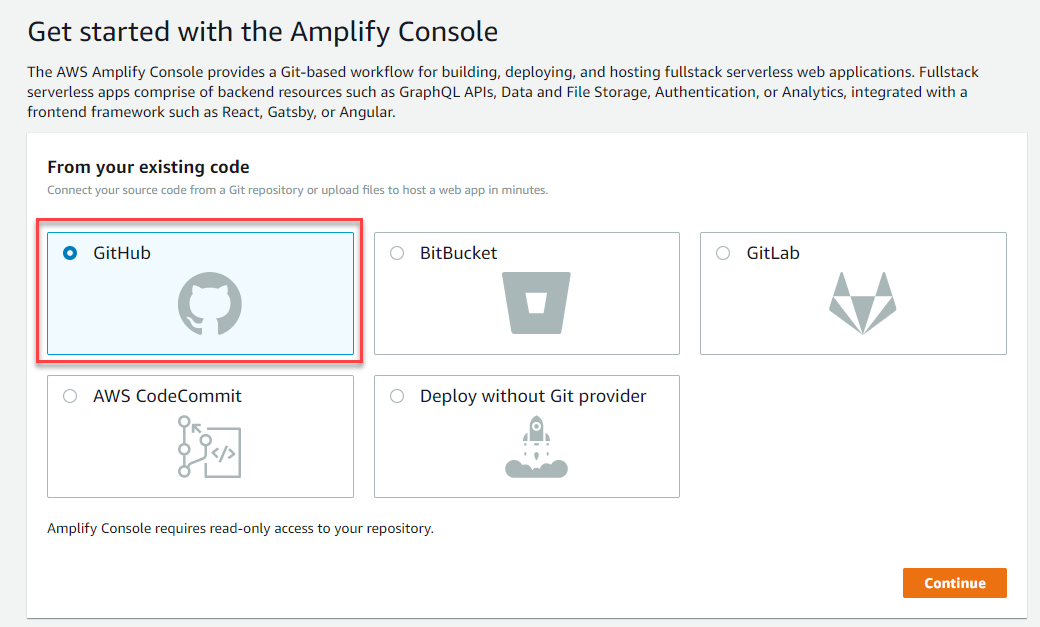
- Select GitHub as the repository provider, then choose Continue:

- Follow the prompts to enable GitHub access, then select the repository dropdown and choose the repo. In the Branch dropdown, choose master. Choose Next.

- In the App build and test settings page, choose Next.
- In the Review page, choose Save and deploy.
- The final screen shows the deployment pipeline for the connected repo, starting at the Provision phase:




After a few minutes, the Build, Deploy, and Verify steps show green checkmarks. Open the URL in a browser, and you see that the application is now served by the public URL:

Finally, before logging in, you must add the URL to the list of allowed URLs in the Auth0 settings:
- Log into Auth0 and navigate to the dashboard.
- Choose Applications in the menu, then select Ask Around Me from the list of applications.
- On the Settings tab, add the application’s URL to Allowed Callback URLs, Allowed Logout URLs, and Allowed Web Origins. Separate from the existing values using a comma.

- Choose Save changes. This allows the new published domain name to interact with Auth0 for authentication your application’s users.
Anytime you push changes to the code repository, Amplify Console detects the commit and redeploys the application. If errors are detected, the existing version is presented to users. If there are no errors, the new version is served to visitors.
Conclusion
In the last part of this series, I show how the application queues posted questions and answers. I explain how this asynchronous approach smooths traffic spikes and helps maintain responsive APIs.
I cover how answers are collected from thousands of users and are aggregated using DynamoDB streams. These totals are saved as summaries in the Questions table, and live updates are pushed via AWS IoT Core back to the frontend.
Finally, I show how you can automate deployment using Amplify Console. By connecting the service directly with your code repository, it publishes and serves your application with no need to manually copy files.
To learn more about this application, see the accompanying GitHub repo.