AWS Compute Blog
Converting call center recordings into useful data for analytics
Many businesses operate call centers that record conversations with customers for training or regulatory purposes. These vast collections of audio offer unique opportunities for improving customer service. However, since audio data is mostly unsearchable, it’s usually archived in these systems and never analyzed for insights.
Developing machine learning models for accurately understanding and transcribing speech is also a major challenge. These models require large datasets for optimal performance, along with teams of experts to build and maintain the software. This puts it out of reach for the majority of businesses and organizations. Fortunately, you can use AWS services to handle this difficult problem.
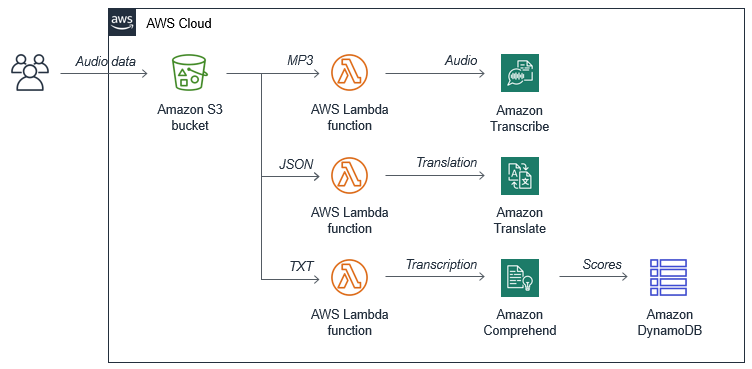
In this blog post, I show how you can use a serverless approach to analyze audio data from your call center. You can clone this application from the GitHub repo and modify to meet your needs. The solution uses Amazon ML services, together with scalable storage, and serverless compute. The example application has the following architecture:

For call center analysis, this application is useful to determine the types of general topics that customers are calling about. It can also detect the sentiment of the conversation, so if the call is a compliment or a complaint, you could take additional action. When combined with other metadata such as caller location or time of day, this can yield important insights to help you improve customer experience. For example, you might discover there are common service issues in a geography at a certain time of day.
To set up the example application, visit the GitHub repo and follow the instructions in the README.md file.
How the application works
A key part of the serverless solution is Amazon S3, an object store that scales to meet your storage needs. When new objects are stored, this triggers AWS Lambda functions, which scale to keep pace with S3 usage. The application coordinates activities between the S3 bucket and two managed Machine Learning (ML) services, storing the results in an Amazon DynamoDB table.
The ML services used are:
- Amazon Transcribe, which transcribes audio data into JSON output, using a process called automatic speech recognition. This can understand 31 languages and dialects, and identify different speakers in a customer support call.
- Amazon Comprehend, which offers sentiment analysis as one of its core features. This service returns an array of scores to estimate the probability that the input text is positive, negative, neutral, or mixed.

- A downstream process, such as a call recording system, stores audio data in the application’s S3 bucket.
- When the MP3 objects are stored, this triggers the Transcribe function. The function creates a new job in the Amazon Transcribe service.
- When the transcription process finishes, Transcribe stores the JSON result in the same S3 bucket.
- This JSON object triggers the Sentiment function. The Sentiment function requests a sentiment analysis from the Comprehend service.
- After receiving the sentiment scores, this function stores the results in a DynamoDB table.
There is only one bucket used in the application. The two Lambda functions are triggered by the same bucket, using different object suffixes. This is configured in the SAM template, shown here:
SentimentFunction:
...
Events:
FileUpload:
Type: S3
Properties:
Bucket: !Ref InputS3Bucket
Events: s3:ObjectCreated:*
Filter:
S3Key:
Rules:
- Name: suffix
Value: '.json'
TranscribeFunction:
...
Events:
FileUpload:
Type: S3
Properties:
Bucket: !Ref InputS3Bucket
Events: s3:ObjectCreated:*
Filter:
S3Key:
Rules:
- Name: suffix
Value: '.mp3'
Testing the application
To test the application, you need an MP3 audio file containing spoken text. For example, in my testing, I use audio files of a person reading business reviews representing positive, neutral, and negative experiences.
- After cloning the GitHub repo, follow the instructions in the README.md file to deploy the application. Note the name of the S3 bucket output in the deployment.
- Upload your test MP3 files using this command in a terminal, replacing your-bucket-name with the deployed bucket name:
aws s3 cp .\ s3://your-bucket-name --recursiveOnce executed, your terminal shows the uploaded media files:
- Navigate to the Amazon Transcribe console, and choose Transcription jobs in the left-side menu. The MP3 files you uploaded appear here as separate jobs:

- Once the Status column shows all pending job as Complete, navigate to the DynamoDB console.
- Choose Tables from the left-side menu and select the table created by the deployment. Choose the Items tab:

Each MP3 file appears as a separate item with a sentiment rating and a probability for each sentiment category. It also includes the transcript of the audio.


Handling multiple languages
One of the most useful aspects of serverless architecture is the ability to add functionality easily. For call centers handling multiple languages, ideally you should translate to a common language for sentiment scoring. With this application, it’s easy to add an extra step to the process to translate the transcription language to a base language:
A new Translate Lambda function is invoked by the S3 JSON suffix filter and creates text output in a common base language. The sentiment scoring function is triggered by new objects with the suffix TXT.
In this modified case, when the MP3 audio file is uploaded to S3, you can append the language identifier as metadata to the object. For example, to upload an MP3 with a French language identifier using the AWS CLI:
aws s3 cp .\test-audio-fr.mp3 s3://your-bucket --metadata Content-Language=fr-FR
The first Lambda function passes the language identifier to the Transcribe service. In the Transcribe console, the language appears in the new job:

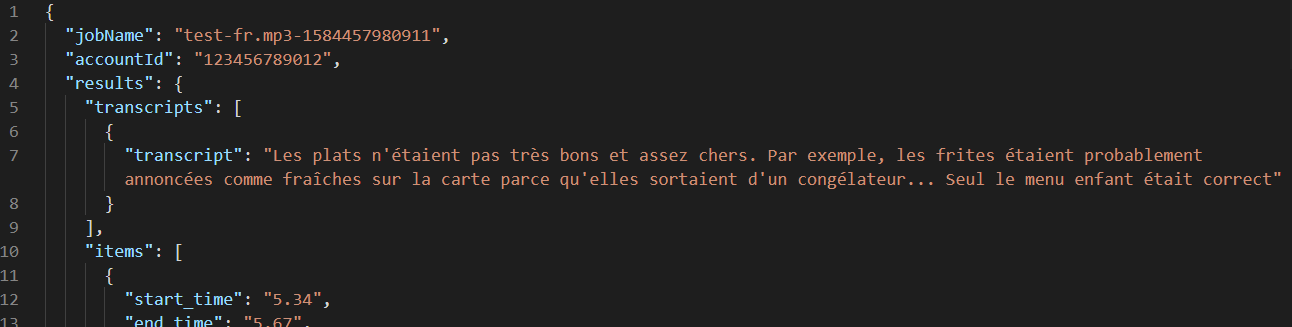
After the job finishes, the JSON output is stored in the same S3 bucket. It shows the transcription from the French language audio:
The new Translate Lambda function passes the transcript value into the Amazon Translate service. This converts the French to English and saves the translation as a text file. The sentiment Lambda function now uses the contents of this text file to generate the sentiment scores.
This approach allows you to accept audio in a wide range of spoken languages but standardize your analytics in one base language.
Developing for extensibility
You might want to take action on phone calls that have a negative sentiment score, or publish scores to other applications in your organization. This architecture makes it simple to extend functionality once DynamoDB saves the sentiment scores. By using DynamoDB Streams, you can invoke a Lambda function each time a record is created or updated in the underlying DynamoDB table:

In this case, the routing function could trigger an email via Amazon SES where the sentiment score is negative. For example, this could email a manager to follow up with the customer. Alternatively, you may choose to publish all scores and results to any downstream application with Amazon EventBridge. By publishing events to the default event bus, you can allow consuming applications to build new functionality without needing any direct integration.
Deferred execution in Amazon Transcribe
The services used in the example application are all highly scalable and highly available, and can handle significant amounts of data. Amazon Transcribe allows up to 100 concurrent transcription jobs – see the service limits and quotas for more information.
The service also provides a mechanism for deferred execution, which allows you to hold jobs in a queue. When the numbering of executing jobs falls below the concurrent execution limit, the service takes the next job from this queue. This effectively means you can submit any number of jobs to the Transcribe service, and it manages the queue and processing automatically.
To use this feature, there are two additional attributes used in the startTranscriptionJob method of the AWS.TranscribeService object. When added to the Lambda handler in the Transcribe function, the code looks like this:
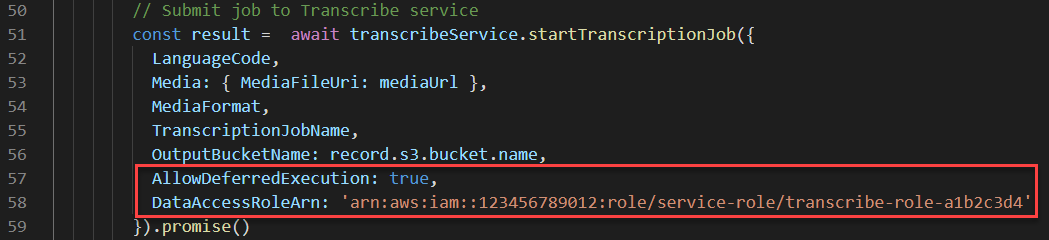
After setting AllowDeferredExecution to true, you must also provide an IAM role ARN in the DataAccessRoleArn attribute. For more information on how to use this feature, see the Transcribe documentation for job execution settings.
Conclusion
In this blog post, I show how to transcribe the content of audio files and calculate a sentiment score. This can be useful for organizations wanting to analyze saved audio for customer calls, webinars, or team meetings.
This solution uses Amazon ML services to handle the audio and text analysis, and serverless services like S3 and Lambda to manage the storage and business logic. The serverless application here can scale to handle large amounts of production data. You can also easily extend the application to provide new functionality, built specifically for your organization’s use-case.
To learn more about building serverless applications at scale, visit the AWS Serverless website.