AWS Compute Blog
Category: AWS Lambda

Announcing migration of the Java 8 runtime in AWS Lambda to Amazon Corretto
Beginning July 19, 2021, the Java 8 managed runtime in AWS Lambda will migrate from the current Open Java Development Kit (OpenJDK) implementation to the latest Amazon Corretto implementation.

Getting Started with serverless for developers: Part 4 – Local developer workflow
This blog is part 4 of the “Getting started with serverless for developers” series, helping developers start building serverless applications from their IDE. Many “getting started” guides demonstrate how to build serverless applications from within the AWS Management Console. However, most developers spend the majority of their time building from within their local integrated development […]
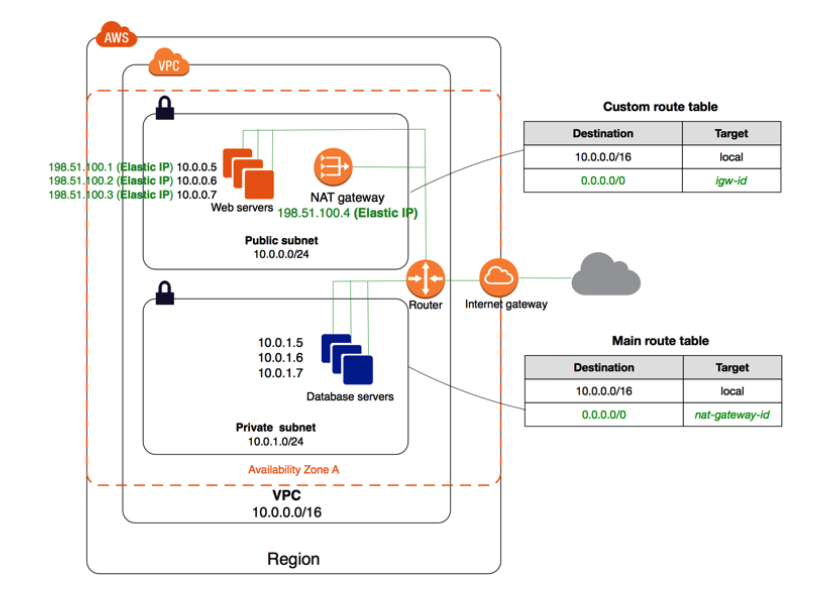
Setting up AWS Lambda with an Apache Kafka cluster within a VPC
Using resources such as NAT Gateways and VPC endpoints with PrivateLink, you can ensure that your data remains secure while also granting access to resources such as Lambda to help you create a Kafka consumer application. This post provides some tips to help you set up a Lambda function using Kafka as a trigger. It also explains various options available to send data securely.

Building serverless applications with streaming data: Part 1
In this post, I introduce the Alleycat racing application for processing streaming data. I explain the virtual racing logic and provide an overview of the application architecture. I summarize the deployment process for the different parts of the solution and show how to test the frontend once the deployment is complete.

Performance and functionality improvements for AWS Lambda extensions
AWS Lambda extensions are a new way to integrate Lambda more easily with your favorite monitoring, observability, security, and governance tools. With the general availability announcement, AWS is introducing performance and functionality improvements. The Lambda service now returns the response from the function as soon as the function code is complete without waiting for the […]

Building private cross-account APIs using Amazon API Gateway and AWS PrivateLink
This post is written by Brian Zambrano, Enterprise Solutions Architect and Srinivasa Atta, Sr. Technical Account Manager With microservice architectures, multiple teams within an organization often build different parts of an application. Different teams may own functionality for a given business segment. An effective pattern to support this is a centrally managed public API. This […]

Operating Lambda: Performance optimization – Part 3
This post is the final part in a 3-part series on performance optimization in Lambda. The Lambda service makes frequent performance improvements in the underlying hardware, software, and architecture of the service. This post identifies the parts of the Lambda lifecycle where developers can make the most impact on performance.
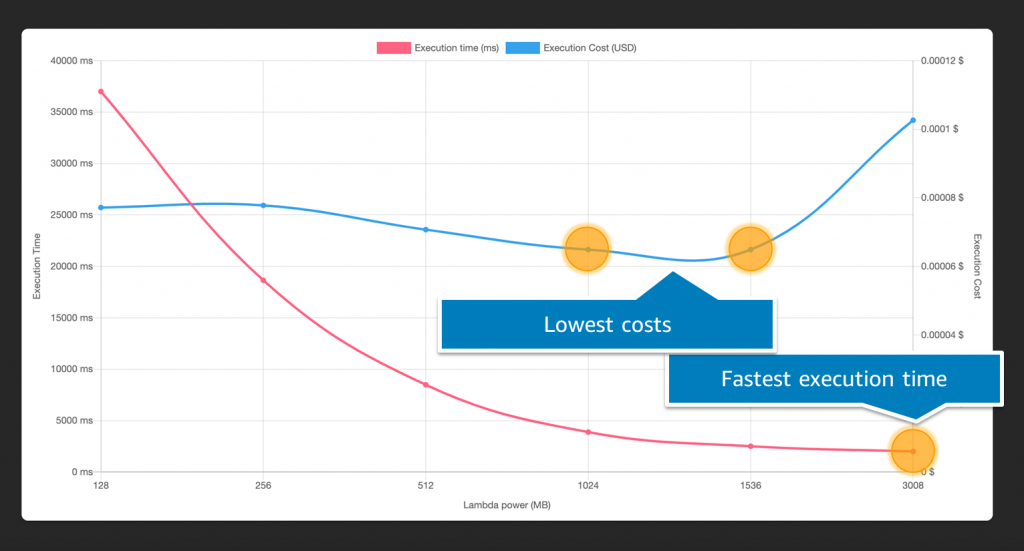
Operating Lambda: Performance optimization – Part 2
This post is the second in a 3-part series on performance optimization in Lambda. It explains the effect of the memory configuration on Lambda performance, and why the memory setting also controls the compute power and networking I/O available to a function.

Getting started with serverless for developers: Part 3 – The front door
This blog post is part 3 of Getting started with serverless for developers, helping developers to start building serverless applications from their IDE. In the previous post, I introduce AWS Lambda and show how functions are designed to run business logic for serverless applications. In this blog post, you see how to access that business […]

Getting started with serverless for developers: Part 2 – The business logic
This blog is part 2 of “Getting started with serverless for developers“, helping developers start building serverless applications from their IDE. In part 1 you learn why developers need serverless technologies and which challenges serverless technologies help to solve. You are introduced to an example serverless application. Deploying this application to your AWS account in […]