AWS Compute Blog
Getting started with serverless for developers: Part 1
Update : You can now find the supporting GitHub repository to this series.
- Part 2: The business logic
- Part 3: The front door
- Part 4: Local developer workflow
- Part 5: Sandbox developer account
Developers around the world are already running serverless applications in production without worrying about servers. This new getting started series is for developers who want to join them. Follow along with blog posts, code examples, and practical exercises to learn how to build serverless applications from your local integrated development environment (IDE).
In this post, you learn why developers need serverless technologies and which challenges serverless technologies help to solve. You deploy a small serverless application to your AWS account that connects Slack to GitHub and see first-hand why serverless technologies spark joy for developers.
What does serverless mean to developers?
Serverless is a broad term that encompasses many different things. For developers, it is a means of building applications that scale automatically, without maintaining, running, or patching infrastructure like servers, clusters, or load balancers.
Building applications with serverless technologies can seem like a significant change for some. It might involve adopting a functional programming model, moving from monoliths to microservices, or reducing code by using managed services.
However, building serverless applications does not have to be a binary choice. Serverless technologies can complement traditional application models. For many developers, their first serverless application augments, integrates with, or connects to a traditional application. This is why understanding what types of workloads are best suited to serverless is important.
Why do developers need serverless?
“I only want to write business logic”
A typical scenario many developers face is a need to do “something” to some data to produce a valuable output. That something can be referred to as business logic. It is at the core of every application.
With traditional (non-serverless) applications, the developer must prepare a number of things before they can start creating business logic. Many of these things are generic and repetitive tasks such as provisioning databases and servers, or setting up backup and restore systems. Using serverless technologies can abstract away many of these common repetitive tasks.
“I want my application to scale on its own”
As applications mature and grow, they may need to handle increasing levels of traffic. This is where scalability challenges can arise. Developers may need to invest in additional architecture or personnel to meet these challenges.
Serverless technologies help to solve this by scaling automatically to meet the increase in demand. They do this by applying a horizontal approach to scalability rather than a vertical approach.
A real life example of horizontal and vertical scalability can be seen in the following illustration:

vertical vs horizontal scaling
Imagine one person needs to travel from home to a birthday party. They use a bicycle as a sufficient mode of transport to carry one person. If two people need to travel together, then a bicycle would be too small and instead they need a taxi. If four people need to travel, then a bus is required, and so on.
This is an example of vertical scaling. Each increase in load requires the purchase of a larger transport mode to bear the load. Applying this same method to scaling an application means that each time a server starts to reach its capacity limits, an additional server is required to increase the load capacity.
Imagine the same four people each travel using a bicycle, the load is now spread evenly. This is far more flexible because as traffic grows you can add an additional capacity unit. This is known as horizontal scaling and it’s what allows serverless technologies to scale flexibly.
“When my code is not running, I don’t want to pay for it.”
With traditional applications, you often need to overprovision. This means having additional resource capacity to accommodate a spike in demand. This additional capacity remains largely unused. With serverless technologies, you pay only for the resources you consume. The horizontal scaling model means that resource consumption scales up and down with your application’s demand. This can make serverless a cost-effective model for applications with variable levels of traffic.
Serverless in practice
One common and effective use of serverless technologies is to connect features of two or more applications together. For example, developers can quickly create endpoints to handle inbound webhooks, run business logic on the webhook payload, and output the result to another service. The following serverless application uses GitHub’s webhook integration capability to notify users via Slack, when a repository has been starred.

Connecting GitHub to Slack, with Serverless technologies
The final result looks like this:

If this application is built using a traditional technology stack, the developer must provision a server to receive the inbound webhook, this may involve raising a ticket with the operations department. The server must always be available, ready to receive the inbound webhook. It must also be configured with enough spare capacity to handle spikes in traffic, or replicated and placed behind a load balancer to distribute traffic evenly. It needs to allow access to the public internet, with additional authorization for the inbound GitHub webhook. The application server operating system and runtime must be maintained with regular patching, and security updates. The list of preparation and maintenance tasks go on.
In contrast, a serverless implementation of the application means not having to think about as many of the traditional stack operations. Developers can start directly with the business logic, and deploy into their AWS account with a single command.
The following steps show how to deploy and test the final application from this GitHub repository. Subsequent posts in this series will show how to build this application from scratch, directly within your local integrated development environment (IDE). They will explain the various AWS services and concepts involved.
Prerequisites
To deploy this application, you need:
- The AWS Serverless Application Model (AWS SAM CLI) installed with an AWS account set up.
- A GitHub account, and a repository with admin permissions.
- A Slack account with the ability to create apps.
Setting up your inbound Slack webhook
This application uses a Slack webhook URL to send a POST request to a Slack channel when a user stars a GitHub repository.
To create the Slack webhook:
- Create a new channel in Slack where you want the messages to go.
- In your new channel, choose Add apps

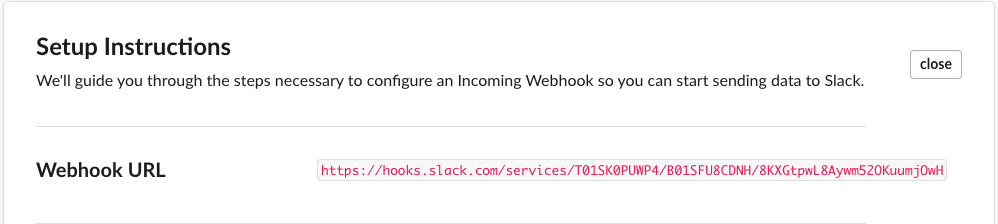
- Search for the “Incoming Webhook” application, and create a new one for your channel.

Once created, a Slack webhook URL is displayed. The serverless application uses this URL to post data to your Slack channel. Make a note of this URL as you will need it when you deploy the application.
Deploying the serverless application
The serverless application code exists in this GitHub repository. First, clone the application code to your local machine, then deploy it to your AWS account:
- Run the following command in a terminal window on your local machine
git clone https://github.com/aws-samples/getting-started-with-serverless - Change directory into the root of the application by running the following command:
cd part_1 - AWS SAM is a framework for building and deploying serverless applications.
Deploy the application to your AWS account using the following AWS SAM CLI command:sam build sam deploy --guided --config-file ../samconfig.tomlThis command leads you through a guided deployment, which requires some input parameters. Enter a stack name such as “GitHubToSlackApp”. Enter the AWS Region to deploy to, Answer Y to answer “webhookHandler may not have authorization defined” and accept the remaining defaults. Make sure to replace the Parameter slackUrl prompt with the Slack URL you noted down previously:

- The deployment takes a moment to complete after which, the following output is provided:

Make a note of the GitHubEndpoint value. This URL is the gateway to your serverless application. A POST request to this URL, along with the correctly formatted payload triggers the application to run, at which point it posts a message to the Slack webhook URL. The final task is to tell GitHub when to send a POST request to this URL:
Setting up your GitHub webhook
- Go to the GitHub repository you want to track and choose Settings, then Webhooks.
- Choose Add webhook.
- In the Payload URL field, enter the GitHubEndpoint value noted down earlier:

- In the Content type field, select application/json.
- In the Which events would you like to trigger this webhook? section, choose Let me select individual events, and choose Watches.
- Choose Add webhook.
Running the serverless application
Congratulations! You have deployed a serverless application.
To see the application working in your GitHub repository:
- Choose the star icon.
This sends the GitHub event to the serverless application, which processes and sends it to the Slack webhook URL. The message appears in the Slack channel showing who starred the repository and how many total stars the repository has.
A high-level representation of this serverless application can be shown as:

Summary
This blog post introduces the new Getting started with serverless series. This is a developer focused series consisting of blog posts, code examples, and exercises to help developers start building serverless applications from their local IDE. This post introduces the reasons why developers need serverless technologies. It explains how to clone and deploy an example serverless application from your local machine to your AWS account.
In a few steps, you see how serverless technologies can help build applications quickly, removing repetitive tasks and allowing you to focus on the business logic.
Future blog posts in the series will explore this serverless application in more detail. Readers will learn how to build and update the application from their local IDE. They will discover where the business logic is written, which AWS services are used to create this application, and how to test and extend it.
For more resources for building serverless applications, go to serverlessland.com