AWS Database Blog
Accelerate generative AI use cases with Amazon Bedrock and Oracle Database@AWS
Oracle Database version 26ai enables the development of generative AI applications such as voice assistants, chat assistants, language translators, recommendation systems, anomaly detection, or video search and recognition by providing the ability to store vector embeddings and query data based on semantics rather than keywords. By using AI Vector Search in Oracle AI Database 26ai, you can build Retrieval Augmented Generation (RAG) applications with important context without having to retrain the large language model (LLM). The context is stored, searched, and retrieved from Oracle AI Database 26ai and passed to the LLM to generate accurate, up-to-date, and targeted responses to your prompts. Customers can use RAG with AI Vector Search in Oracle AI Database 26ai and an LLM to securely respond to important business questions or generate content for many use cases using private, internal business information.
Oracle AI Database 26ai supports VECTOR datatype, providing the foundation to store vector embeddings alongside business data in the database. With embedding models, you can transform unstructured data into vector embeddings that can then be used for semantic queries on business data. You can generate vector embeddings outside the Oracle Database using pre-trained embedding models hosted in Amazon Bedrock, open source embedding models, or your own embeddings models. Amazon provides various options for vector databases like Amazon OpenSearch Service, Amazon Aurora PostgreSQL-Compatible Edition, Amazon DocumentDB, and others to choose from depending on your use case and requirements. In this post, we walk through the steps of integrating Oracle Database@AWS (ODB@AWS) with Amazon Bedrock for by creating a RAG assistant application using an Amazon Titan embedding model in Amazon Bedrock and vectors stored in Oracle AI Database 26ai.
ODB@AWS enables you to access Oracle Exadata infrastructure managed by Oracle Cloud Infrastructure (OCI) within AWS data centers. You can use it to migrate your Oracle Exadata workloads to AWS while maintaining the same performance and features as your on-premises Exadata deployments. ODB@AWS supports both Oracle Database 19c and 26ai database versions in Exadata Database Service or Autonomous Database Service on Dedicated Infrastructure. It enables integration with various AWS services, like Zero-ETL integration with Amazon Redshift, Amazon S3 integration for backups, Amazon CloudWatch for monitoring, Amazon Bedrock, Amazon SageMaker AI, and other generative AI services to build generative AI applications.
Overview of Oracle AI Database 26ai vector capabilities
Oracle AI Database 26ai provides vector capabilities through its AI Vector Search feature, enabling AI workloads to run on ODB@AWS. Key capabilities include:
Native VECTOR data type and operations
Oracle AI Database 26ai introduces a new VECTOR data type, allowing for the native storage of high-dimensional vectors directly in table columns. You can store, query, and perform analytics operations on vector data within a single, unified database environment. It integrates AI Vector Search capabilities natively, enabling similarity searches, hybrid queries that combine vector and relational data, and advanced analytics without requiring external services.
This allows vectors to coexist with unstructured, semi-structured, and structured data, including documents, PDFs, and images stored in SecureFiles LOBs, JSON data for metadata and context, and graph and spatial data for advanced analytics and AI-driven recommendations. This reduces complexity and improves security while enabling hybrid queries that combine semantic search with business context.
Flexible vector generation
Oracle provides flexibility to integrate with external embedding models and other RAG frameworks such as LangChain and LlamaIndex through Python or REST APIs. It also enables import of pre-trained embedding models directly into the database in ONNX format, allowing vector embeddings to be generated within the database environment. But this adds to database performance overhead and needs constant update and maintenance of the models.
AI Smart Scan (Exadata-optimized)
Because Oracle Database@AWS offering runs on Exadata, it uses AI Smart Scan to query vector data, which offloads vector operations to Exadata storage servers. It optimizes bandwidth, reduces CPU usage on the database tier, and is ideal for high-scale artificial intelligence and machine learning (AI/ML) applications such as real-time semantic search and recommendation engines.
Dedicated memory allocation
Oracle allocates a specialized memory area called vector_pool to store Hierarchical Navigable Small World (HNSW) vector indexes and associated metadata, separate from the database buffer cache. It is also used to speed up Inverted File Flat (IVF) index creation as well as DML operations on base tables with IVF indexes. This feature enables predictable performance for AI-driven workloads without impacting transactional operations.
Simplified development and data management
Developers can work with both relational and vector data within a single environment using standard SQL, reducing the learning curve and streamlining application development. It allows vector operations using PL/SQL packages. By integrating vector capabilities into a general-purpose database, Oracle AI Database 26ai uses existing enterprise-grade features like security, high availability (such as RAC), partitioning, sharding, and disaster recovery.
External table support for vector data
External table support for vectors in Oracle AI Database 26ai makes it possible to store and query embeddings directly from external files for better cost and flexibility. It’s useful for quickly exploring or staging vector data, running similarity searches or hybrid queries that mix relational and vector information, and performing proof-of-concept analysis on large external datasets before committing to full ingestion. You can have your external tables with vector data created on Amazon S3 and run your sematic search against them.
Solution overview
In this post, we demonstrate on how to build a RAG AI assistant application using Oracle AI Database 26ai as a vector data store, LangChain framework, Amazon Titan embedding model, and Anthropic’s Claude LLM model hosted in Amazon Bedrock.
In the following diagram, we use Oracle AI Database 26ai as the vector store deployed in ODB@AWS. The AI chat assistant application is deployed on an Amazon Elastic Compute Cloud (Amazon EC2) instance in a virtual private cloud (VPC) peered with an ODB network using ODB peering. An ODB network is a private, isolated network that hosts Oracle infrastructure within an AWS Availability Zone. Unlike a standard VPC, an ODB network lacks internet connectivity and supports only ODB@AWS resources. ODB peering establishes private network connectivity between your ODB network and an Amazon VPC, enabling applications to communicate with Oracle databases as if they were on the same network. ODB peering bridges AWS and Oracle environments and offers support for a routing capability that enables traffic from specific AWS services connected to your peered VPC to reach the ODB network. Amazon Titan embedding model from Amazon Bedrock is used to create the vector embeddings. Anthropic’s Claude LLM is invoked from Amazon Bedrock for semantic search. Access to Amazon Bedrock is granted to the EC2 instance through its associated AWS Identity and Access Management (IAM) role.
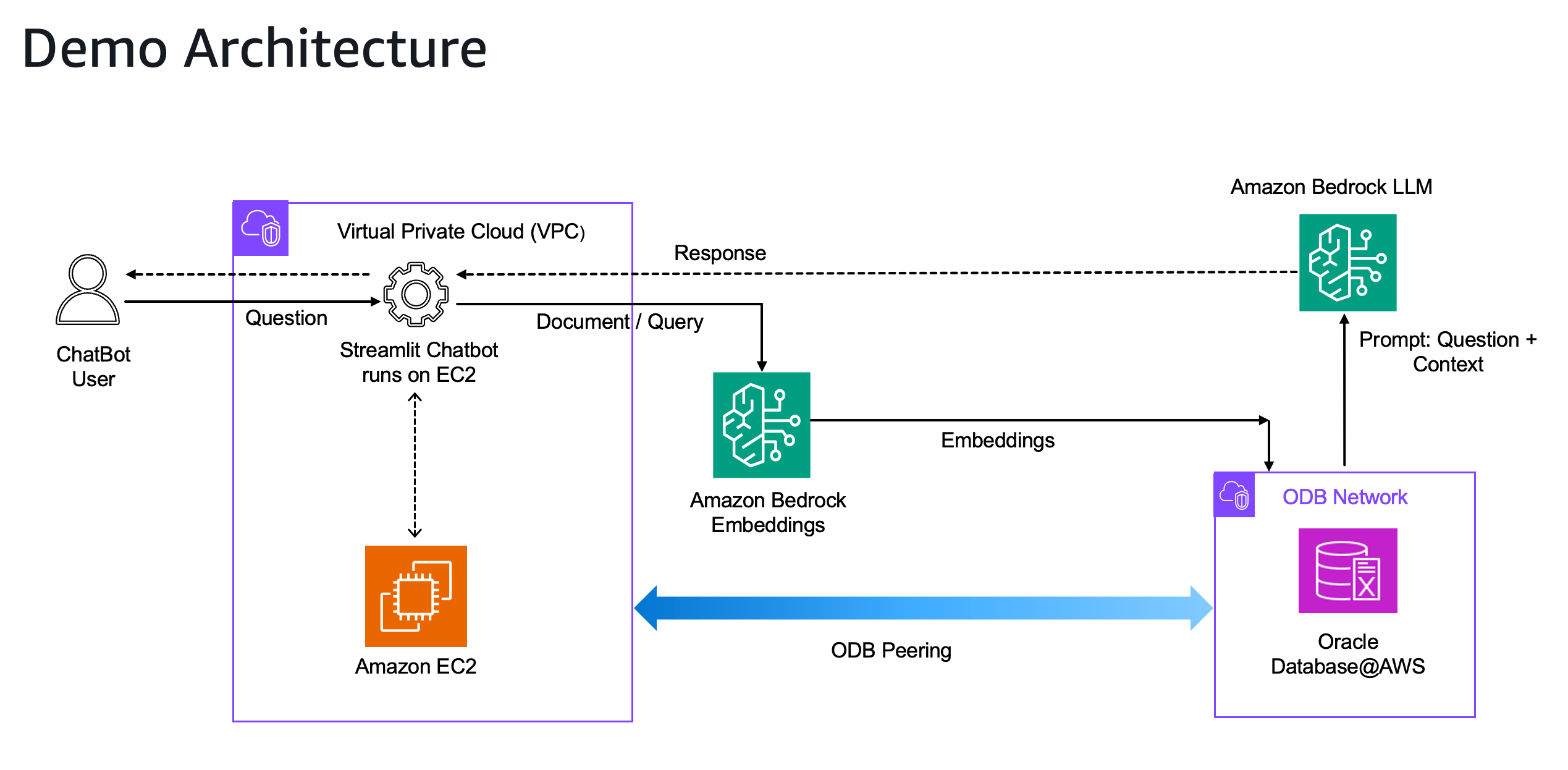
An end-to-end RAG workflow for our demo consists of the following high-level steps:
- Data Ingestion (PDF in this demo): Ingest PDFs into the app, which reads them and extract their text content.
- Text Chunking: Extracted text is divided into smaller chunks that can be processed effectively. Chunking the text is important for retrieval quality and rate-limit safety.
- Generate Embeddings: Applications uses Amazon Titan Text Embeddings v2 model from Amazon Bedrock to generate embeddings which are vector representations of the text chunks.
- Vector store: Store vectors and metadata in Oracle AI Database 26ai with Oracle Database@AWS (Oracle AI Vector Search).
- User Question: A user types a question in natural language in the chatbot.
- Similarity Matching: When the user asks a question, the app compares it with the text chunks and identifies the most semantically similar ones.
- RAG: Run retrieval augmented Q&A with Anthropic’s Claude 3 Sonnet model on Amazon Bedrock through an application built on the Streamlit UI.
- Response: The LLM generates a response based on the relevant content of the PDFs.
For the complete code, refer to the GitHub repo.
Prerequisites
To implement this solution, we have completed following pre requisites and created required resources:
- An AWS account with Amazon Bedrock access in your AWS Region. Amazon Bedrock requires you to request access to its foundation models (FMs) before you can start invoking the model using Amazon Bedrock APIs. You must configure model access in Amazon Bedrock in order to build and run generative AI applications. Amazon Bedrock provides a variety of FMs from several providers, such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon.
- An Oracle AI Database 26ai installed on Oracle Database@AWS, which is used as the vector store. In this demo architecture we have 26ai deployed on Exadata Database service in ODB@AWS
- An EC2 instance deployed in a VPC that is ODB peered with an ODB network that hosts the Oracle Database@AWS service. Make sure the EC2 instance used as the client here has network connectivity to Oracle Database in ODB@AWS.
- An IAM role attached to the EC2 instance with policies granting access to Amazon Bedrock models and SageMaker AI services. See the following example policy. Refer to GitHub for the full policy JSON document.
Application Build
Follow the below steps to build an end-to-end RAG workflow including AI chat assistant built on Streamlit using Oracle 26ai and vector store and integrating with Amazon Bedrock for Embedding and LLM models.
You can also repurpose the full code available on GitHub. Jump to Demonstration section for instructions on how to deploy the code from GitHub and execute it.
- Import libraries:
- Ingest documents:
The document in our use case is in PDF format. We load a PDF document and transform each page of the PDF document to text.Note: For simplicity in our example we are loading the PDF documents into the app from local desktop but this data source (PDF document) can reside inside Oracle database (PDF as BLOB), or it can also be external to the database like in Amazon S3 bucket.
- Chunk the text:Given the extracted text, this function splits it into smaller chunks using LangChain’s RecursiveCharacterTextSplitter module. The chunk size, overlap, and other parameters are configured to optimize processing efficiency.
The
create_documentsfunction below takes a list of text chunks and transforms them into Document objects with metadata. This function creates a new Document object for each text chunk, assigning an ID and a page link as metadata, and uses a list comprehension to process all chunks efficiently.The
process_chunk_with_delayfunction handles the processing of a single document chunk while implementing rate limiting through a time delay. It first introduces a pause using time.sleep to respect rate limits, then uses the embedder to convert the document’s content into a numerical embedding vector.The
batch_process_embeddingsfunction manages the parallel processing of multiple documents to generate their embeddings while maintaining rate limits. It uses aThreadPoolExecutorto process multiple documents concurrently (up toMAX_CONCURRENT_REQUESTS), and maps each document through the process_chunk_with_delay function to generate embeddings while respecting rate limits, finally returning a list of generated embeddings. - Store vector embeddings:Next, we load the vector embeddings using the amazon.titan-embed-text-v2 model into Oracle Database@AWS as the vector database. This function takes the text chunks as input and creates a vector store using Amazon Titan Embeddings. You can create it from environment variables as shown in the following screenshot. Change according to your database setup

The preceding code manages Oracle database connections in a Streamlit application through three main functions. The
get_oracle_connection()function creates a new database connection if one doesn’t exist in the session state,check_connection()verifies if the existing connection is healthy and recreates it if necessary, andsafe_close_connection()properly closes the database connection when it’s no longer needed. Together, these functions provide reliable database connectivity while preventing connection leaks and handling errors gracefully.The preceding code initializes the Amazon Bedrock embedding service, which converts text into numerical vectors (embeddings) using the Amazon Titan model. It creates an Amazon Bedrock client specifically for the
us-east-1Region and sets up theBedrockEmbeddingsobject with the Amazon Titan embedding model. If anything goes wrong during initialization, it logs the error and raises the exception.The preceding code sequence performs three main operations in a document embedding workflow:
- Initialize the Amazon Bedrock embeddings service using the previously defined function.
- Process a batch of documents (docs) to create their vector embeddings using the embedder.
- Create a vector store in Oracle Database (OracleVS) by storing the documents and their embeddings, using dot product as the similarity measure between vectors, in a table named ORAVSEMBEDDING.
The next step enables vector similarity search for the documents.
- Create conversational chain:In this function, a conversation chain is created using the conversational AI model (Anthropic’s Claude v1) and vector store (created in the previous function). This chain allows the generative AI application to engage in conversational interactions.
- Create function to handle the questions:This function is responsible for processing the user’s input question and generating a response from the AI assistant.
- Create Streamlit components:
Streamlit is an open source Python library that makes it simple to create and share custom web applications for ML and data science. In just a few minutes, you can build and deploy powerful data applications. The following code creates the Streamlit components.
Demonstration
Now that you have successfully written code for your generative AI assistant application, it’s time to run the application using Streamlit. Follow below steps to deploy the code from GitHub.
- Clone the GitHub repo.
- Navigate to the folder where you cloned the repo.
- Create a
.envfile in your project directory to add your Oracle Database@AWS details. Your.envfile should like the following code: - The GitHub repository you cloned earlier includes the file
requirements.txt, which has the required libraries you need to install for building the AI assistant application. Install the libraries by running the following command: - Navigate to the cloned repo folder and run the following command:
This will start the application, launch the URL in a browser window which will open the application as shown.
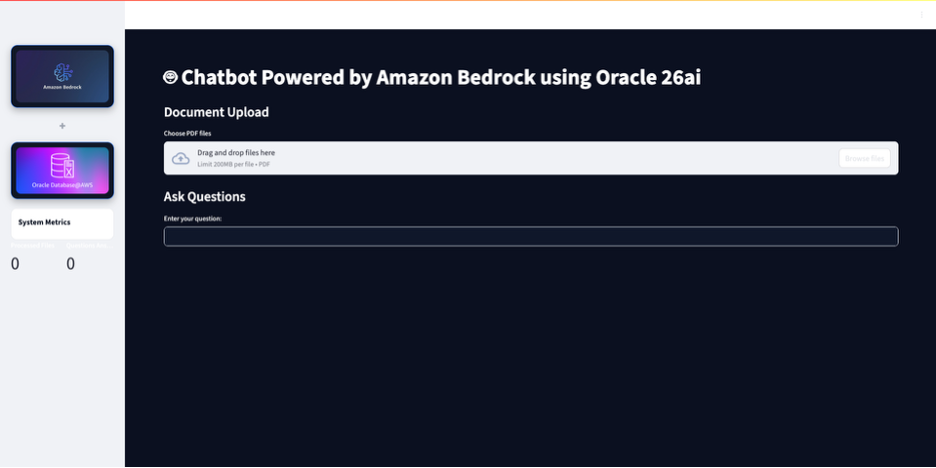
- Upload the PDF file by choosing Browse files.
In this example we uploaded Oracle 26ai user guide in pdf format. - Choose Process Documents.
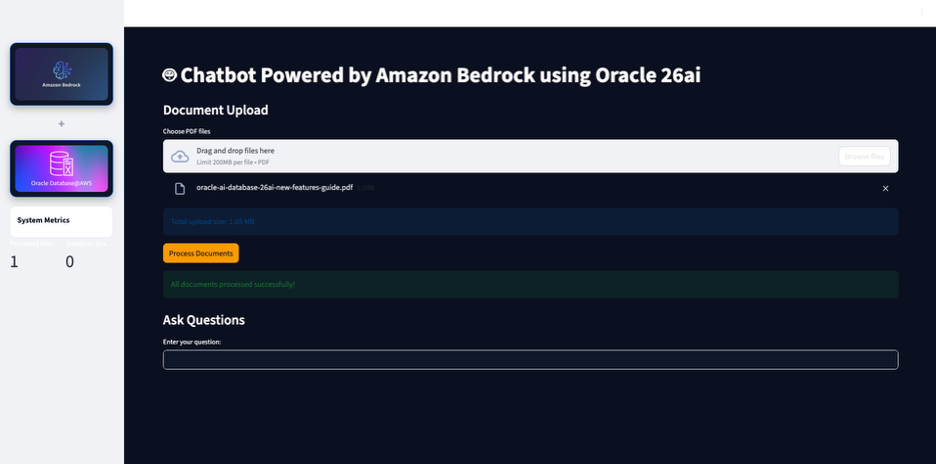
- Enter your question and choose Ask.
The AI assistant processes the question through the RAG workflow and generates a response as shown in the following screenshot.


Clean up
When no longer required make sure to delete the resources provisioned for this testing so that you don’t encounter charges for them. You can manually delete the Streamlit application and EC2 instance along with Oracle AI Database 26ai on Exadata database service if not used.
Conclusion
In this post, we walked through the key vector capabilities of Oracle Database 26ai on Oracle Database@AWS and demonstrated how to integrate Amazon Bedrock and Amazon SageMaker with ODB to build generative AI applications.