AWS Database Blog
Architect and migrate business-critical applications to Amazon RDS for Oracle
Amazon Relational Database Service (Amazon RDS) for Oracle is a fully managed commercial database that makes it straightforward to set up, operate, and scale Oracle deployments in the cloud. In this post, we share the story of a database migration for a business-critical application from a vital database instance running inside Oracle SuperCluster to Amazon RDS for Oracle with Multi-AZ for one of our customers. We cover the different phases of the project from planning and architecting to migrating the critical applications. We also share the challenges faced and how they overcame them during the migration. Finally, we talk about some best practices and recommendations for running critical applications on Amazon RDS for Oracle, including details to run routine operations with minimal downtime.
Background and initiatives of this Oracle migration project
Oracle SuperCluster is an engineered system equipped with Exadata features designed to run many high-performance Oracle database workloads together. However, this approach creates business agility challenges because each workload may require a different database engine, and Exadata’s proprietary features can create lock-in challenges for companies. Additionally, Oracle SuperCluster’s total cost of ownership (TCO) can be high due to its dependency on Oracle for hardware deployment, maintenance, and support.
As our customer decided to transition into adopting cloud services, they were aiming at replacing monolithic software architectures with microservices in order to increase agility and innovation, and reduce complexity. However, each service had distinct data requirements and experienced varying growth rates, and were compelled to utilize the same database engine. Employing a single, large, monolithic database engine to cater to all their services severely impeded their developers’ flexibility and agility.
As a result, our customer decided to move from Oracle SuperCluster to various AWS fully-managed database engines such as Amazon RDS for Oracle, Amazon RDS for MySQL, and Amazon RDS for PostgreSQL. This approach provided greater flexibility and agility because they could choose the database engine that best suits each application’s needs. It also mitigated lock-in challenges and TCO because AWS fully managed databases are not tied to proprietary hardware and offer greater deployment and pricing options.
Collecting data about specific database instances from Oracle AWR
For a migration of large-scale databases, right-sizing your RDS instance based on your existing Oracle on-premises database is very important. There are two approaches to retrieve the necessary information to plan for instance sizing.
Generate an AWR report
To discover the on-premises DB instance workload, we use SQL scripts to retrieve database performance metrics such as I/O-related metrics, shared pool utilization, PGA usage, and other relevant metrics from Oracle’s Automatic Workload Repository (AWR). These scripts can generate an AWR report for a particular DB instance running in Oracle SuperCluster.
You can collect AWR reports during different time periods to represent the peak and average loading statistics. In our case study, the source database was running in an Oracle RAC environment. Therefore, we first get the instance number by running the following SQL command to generate an AWR report for the specified instance number in the last 24 hours. To extract accurate data from an AWR report, we recommend running the report during a production high-loading period and minimizing intense maintenance operations such as RMAN backup.
Run the following command to generate an AWR report in HTML format:
Note that you need a valid license for Oracle Database Enterprise Edition with Diagnostics and Tuning Pack. As an alternative, you can consider using Oracle Statspack to monitor database performance that doesn’t require this license.
Download the AWR report and review the size of the instance based on the information of CPU, SGA, and I/O profile.
As an alternative, you can refer to Right-size Amazon RDS instances at scale based on Oracle performance metrics for more information on using Python and SQL scripts to collect the database performance workload of on-premises Oracle databases at scale.
Interpret key information retrieved from the AWR report for proper sizing
The Oracle SuperCluster was running with a SPARC M7 processor, while RDS is running on Intel x86 or AWS Graviton. To find out the count of vCPUs on Amazon RDS for Oracle in order to map the usage on the SPARC M7 environment, we use the x86 CPU thread mapping ratio approach using a performance benchmark conducted by SPEC. It can help us conduct the high-level CPU performance comparison across different architectures. The following table summarizes our results:
| Processor Type | Number of Cores | Threads per Core | Number of Threads | SPECrate®2017_int_peak Score | Per-Thread Scores |
| SPARC M7 | 32 | 8 | 256 | 114 | 0.44531 |
| Intel Xeon Platinum 8158 | 48 | 2 | 96 | 304 | 3.1667 |
According to the report SPEC® CPU2017 Integer Rate Result on SPARC M7, it has 32 core * 8 threads/core = 256 threads in total and SPECint_rate_base2017 = 114. Its per-thread score is 114/256 = 0.44531. Similarly, from the report SPEC® CPU2017 Integer Rate Result on Intel Xeon Platinum 8158 (which is similar to RDS for Oracle r5 instance family), it has 48 core * 2 threads/core = 96 threads in total and SPECint_rate_base2017 = 304. Its per-thread score is 304/96 = 3.1667. Their CPU thread mapping ratio = 3.1667/0.44531 = 7.1. This means we need 7.1 SPARC M7 threads to do the same contribution to the benchmark quantity as 1 x86 thread on an RDS for Oracle instance.
Moving forward, we checked the OS Statistics By Instance section in the AWR report. We noticed that the DB instance is allocated with 12 CPU cores supporting at maximum 96 threads. By using the CPU thread mapping ratio, we needed 96 threads/7.1 = 13.5 threads on the RDS for Oracle instance to accomplish the same task. That would be at least r5.4xlarge that supports 16 vCPU with Hyperthread enabled.
NUM_CPUS (Threads) |
96 |
NUM_CPU_CORES |
12 |
Next, we reviewed the memory allocated to SGA (System Global Area) and PGA (Program Global Area) in the Oracle instance. In our example, the settings of these values from init.ora parameters were 21.5 GB for pga_aggregate_target and 64.4 GB for sga_target. We could interpret that Oracle SuperCluster allocated 86 GB memory for that DB instance.
sga_target |
* 64424509440 |
pga_aggregate_target |
* 21474836480 |
To be cautious, we further verified if the proposed RDS for Oracle instance could fulfil the following guidelines. The objective is to verify that the total memory available on RDS for Oracle instance should fit in SGA + PGA with additional buffers:
DBInstanceClassMemory* 3/4 should be larger thansga_targetDBInstanceClassMemory* 1/8 should be larger thanpga_aggregate_targetDBInstanceClassMemoryshould be larger than sum ofsga_targetandpga_aggregate_target
Based on these conditions, we proposed an RDS for Oracle instance that had at least 256 GB memory in which its 3/4 value would be 192 GB (larger than 64.4 GB for sga_target) and its 1/8 value would be 32 GB (larger than 21.5GB for pga_aggregate_target).
Finally, we reviewed the IOPS for read and write based on the I/O profile with minimum maintenance activities. In our case, it recorded 2,025 IOPS/second (1,813+212) during the snapshot period. We had to select an instance size that could handle this I/O throughput requirement.
| Statistic | Read and Write/sec | Reads/sec | Writes/sec |
| Database Requests | 1,812.92 | 1,798.90 | 14.02 |
| Optimized Requests | 211.52 | 206.62 | 4.91 |
| Database (MB) | 725.27 | 718.19 | 7.08 |
The IOPS and throughput capacity of an RDS for Oracle instance depends on the instance class and size and storage configuration.
When you choose an RDS for Oracle instance configuration, make sure the I/O and throughput requirements of the workload can be met at the Amazon Elastic Compute Cloud (Amazon EC2) instance level as well as at the storage layer.
In conclusion, we decided to start with an RDS for Oracle r5.8xlarge instance equipped with 32 vCPU, 256 GiB memory, 20,000 GiB gp2 EBS based on our study. This instance could offer 16,000 IOPS baseline performance with maximum 6,800 Mbps EBS bandwidth that could fulfill the original Oracle DB instance performance requirements of 2,025 IOPS and 725.3 MBps or 5,802.4 Mbps on database read/write operations.
| . | Instance Type | vCPU | Memory (GiB) | Disk Bandwidth (Mbps) | Storage Size (GiB) | Max IOPS |
| Requirements | DB instance A | 16 | 86 | 5,800 | 20,000 | 2,025 |
| Suggestions | r5.8xlarge | 32 | 256 | 6,800 | 20,000 (gp2) | 16,000 |
Architecture and migration methodology
Business-critical applications require high availability and fault tolerance to minimize downtime and service interruption. The Multi-AZ (Availability Zone) feature of the Amazon RDS replicates database updates across two Availability Zones to increase durability and availability. Amazon RDS will automatically fail over to the standby for planned maintenance and unplanned disruptions. For some applications that can’t tolerate any downtime in Amazon RDS for Oracle during maintenance, we can consider using AWS Database Migration Service (AWS DMS) as a tool to perform logical replication to simulate blue/green deployment during the upgrade with minimal downtime.
Besides the Multi-AZ design, we also have the option of using RDS for Oracle replicas that can offload read-only tasks and improve fault tolerance. An Oracle replica database is a physical copy of your primary database. There are two types of RDS for Oracle replicas. An Oracle replica in read-only mode is called a read replica. An Oracle replica in mounted mode is called a mounted replica. Both mounted and read replicas require Enterprise Edition. In addition, you must also have Active Data Guard licenses to support read replicas.
Initial data load migration
One of our challenges in this Oracle SuperCluster migration was to handle one source DB instance with a database size of 20 TB containing large-sized tables together with a volume of daily write transactions that could reach 50 MB per second or 4 TB per day. The migration exercise would use AWS DMS for the initial data replication. Next, we perform continuous data synchronization using AWS DMS change data capture (CDC) to track the changes at the source database during the migration. During the initial data migration of 20 TB of data containing large-sized tables, the AWS DMS data migration task could take days to complete. The long duration was due to the source database remaining open for read and write activities during the initial load process. There is an alternate way to conduct initial data migration via RMAN Transportable Tablespaces besides using AWS DMS. You can migrate sets of tablespaces to Amazon RDS for Oracle using Oracle RMAN XTTS to simplify the movement of large amounts of data and speed up the migration process.
Despite the unavailability of the RMAN XTTS solution at the time of our migration project, we seamlessly implemented the AWS DMS initial load approach, which proved to be a reliable solution for performing full loading. However, it’s important to acknowledge the potential benefits and advantages that the RMAN XTTS solution offers as an excellent alternate solution for future full loading requirements.
Parallel run
It’s a common practice for customers to carry out parallel runs for business-critical systems on both existing and new environments post-migration. They need to verify the functioning and data integrity at the new system after the migration. In our migration, the database on both on-premises Oracle SuperCluster and Amazon RDS for Oracle had to be run in parallel to support the applications for 3 weeks before the official system cutover. During these 3 weeks, the applications sent write operations to both Oracle SuperCluster and RDS for Oracle databases. The read operations were served from the SuperCluster. If there were performance or data integrity issues between the on-premises and RDS databases, the entire database migration workflow would start over from the beginning.
If we need to restart the database migration workflow, we need to redo the AWS DMS initial data load on a new RDS for Oracle instance. This would be time consuming for our case. Therefore, to facilitate our migration exercise more effectively, we used a mounted replica. The AWS DMS targeted RDS instance would be used as a synchronized backup database with Oracle SuperCluster. We created a replica from this RDS instance to facilitate our parallel run and cutover.
By creating a mounted replica from the AWS DMS targeted RDS instance, we could use this replica to turn into the new standalone RDS for Oracle production system afterwards. Meanwhile, we maintained the AWS DMS targeted RDS for Oracle instance as the backup so that we could create new replicas in the future. Because this RDS for Oracle instance was synchronized with on-premises SuperCluster, we could quickly prepare the environment for migration without conducting the AWS DMS initial data load again.
Migration methodology
The following diagram illustrates the overall architecture and migration flow details. The flow includes preparing the migration environment, conducting the parallel run, data validation, and migration cutover.

The entire migration process is divided into four phases:
- Preparation phase – Setting up the environment, including AWS DMS CDC tasks and a mounted replica.
- Replica cutoff phase – Promote the mounted replica into the RDS for Oracle production cluster, modify it as Multi-AZ, and prepare for parallel running.
- Parallel run with data validation phase – Update the applications to perform write operations in parallel at the on-premises Oracle SuperCluster and newly promoted RDS for Oracle production cluster. Ongoing data validation would be conducted on both databases.
- Cutover phase – Stop the parallel running and shut down the Oracle SuperCluster DB instance.
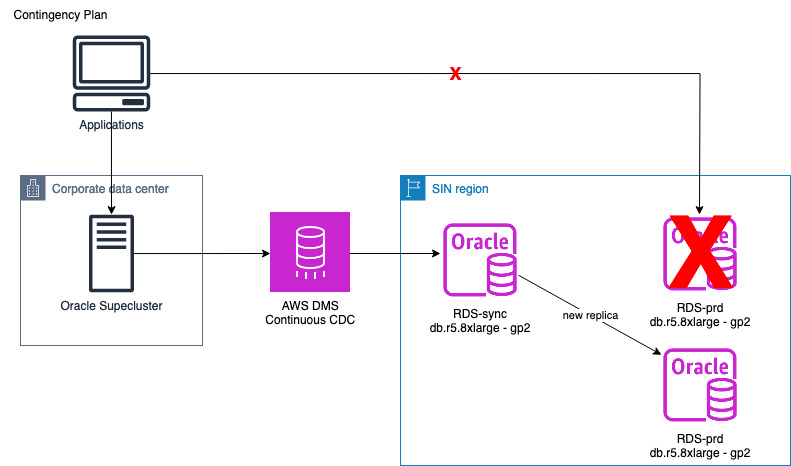
In case we discovered data integrity issues during the parallel run phase, we would move to a contingency plan where we prepare a new mounted replica and restart the preparation phase.
Preparation phase
Based on our experience, conducting a mission-critical database migration with CDC within a single AWS DMS task could easily experience failure due to various reasons, such as incompatible data fields in the source table.
After we provisioned the right-sized RDS for Oracle instance, we started setting up AWS DMS tasks between the source database on Oracle SuperCluster and our target database. At the preparation stage, we used AWS DMS to conduct the data migration for more than 900 tables with a volume size of 20 TB for initial load without CDC. We split the migration into 30 AWS DMS tasks distributed on five AWS DMS replication instances simultaneously. We used the source filters feature inside each AWS DMS task configuration to define the range of records of the particular table to be transferred from the source to target. With this approach, we could identify and fix the issues that affected the AWS DMS tasks and manage the preparation phase efficiently.
These AWS DMS tasks replicated data to our RDS for Oracle RDS-sync instance. This instance was used as the backup and checkpoint for the migration. Meanwhile, we set up the mounted replica RDS-prod based on RDS-sync. We promoted this RDS-prod replica to a production RDS for Oracle instance later on. Note that it was a mounted replica and therefore no Active Data Guard license was required.
After completing the data replication tasks, we created a CDC task between the source DB instance on Oracle SuperCluster and our RDS-sync instance to track and replicate new transactions to the RDS-sync based on the redo log. While running the CDC tasks, we monitored the replica lag between RDS-prod and RDS-sync to make sure that the transactions were run at both RDS for Oracle instances without delays.

Replica cutoff phase
Before promoting the mounted replica to a standalone instance, we made sure the database got minimal activities and paused all active transactions. The RDS-prod replica would be modified from Single-AZ to Multi-AZ for high availability.
During the replica cutoff phase, we maintained the CDC task between Oracle SuperCluster and the RDS-sync instance. Meanwhile, we promoted the mounted replica RDS-prod to become a standalone RDS for Oracle primary instance for the parallel run phase.

Parallel run phase
At the parallel run phase, the application team modified their application logics to conduct database UPSERT operations twice on Oracle SuperCluster and the RDS-prod instance, respectively. But the applications kept their read operations using tables only on Oracle SuperCluster. This parallel run arrangement would last for 3 weeks to maintain the performance as well as the operations on the RDS-prod instance.

Cutover phase
At the cutover phase, the application team modified their applications to perform both read and write operations with the RDS-prod instance only. Finally, we stopped the AWS DMS CDC task between the Oracle SuperCluster and RDS-sync instance. The RDS-sync instance would be stopped after the migration.

Contingency plan
In case there was an issue and we needed to restart the migration workflow, we would create a new mounted replica from the RDS-sync instance. After completing the data synchronization, we promoted this replica into another new RDS for Oracle cluster. The application team would revise their application to conduct parallel running on the existing Oracle SuperCluster and new RDS for Oracle cluster.
With this approach, we used the existing RDS-sync to provide a quick starting point for recreating a new RDS-prod instance through the mounted replica. This helped us minimize the data replication overhead time and the need to perform a full initial load from the beginning.
Best practices for migrating large databases to Amazon RDS for Oracle
We used AWS DMS as our primary tool to conduct the database migration from Oracle SuperCluster to Amazon RDS for Oracle. During the process, we learned several valuable lessons worth considering.
Index the target database if the source database comes from the Exadata platform
Because our DB instance involved a huge number of daily transactions during the parallel run phase, the CDC task needed to be conducted without encountering high target latency. However, because Oracle SuperCluster has a capability to allow SQL statements to take advantage of Exadata Storage Indexes, it can achieve high data retrieval performance even without having a table index. The SQL operations using this feature could potentially cause the high target latency issue due to the repeated full scan operations over target tables in the absence of schema indexes.
To address this, we conducted a query run plan analysis to identify queries that heavily relied on Smart Scans and Storage Indexes on the source. Then we determined which table index we needed to create on the database accordingly to minimize full scan operations during the CDC task.
Extend the archive log retention period in the event of replication lagging
In our migration, we used an RDS for Oracle mounted replica for our parallel running. During the asynchronous replication process, we witnessed an increasing replica lag between the RDS for Oracle primary instance and the associated mounted replica. The replica lag was caused by the high volumes of transactions pending to be replicated on the replica instance.
RDS for Oracle keeps 2-hour archive redo logs by default. However, the 2-hour duration might not be sufficient to store all the log information created to handle archived redo log gaps among the primary instance and replicas. The missing information on the archive log affected replication performance and generated the replica lag issue. Therefore, our resolution was to increase the archived redo logs retention period from 2 hours to 24 hours.
Special handling for data types
There were some data type constraints on the source tables that could interrupt AWS DMS task operations. For example, when unloading data from a source table in Oracle that contains the NUMBER data type, there is no automatic truncation of decimals by default. The NUMBER data type in Oracle allows for precise numeric values with decimal places. However, AWS DMS automatically truncates decimals when unloading the NUMBER data type on the source table.
To address the issue related to the numeric data type being migrated as a floating-point or decimal type in the AWS DMS configuration, we made the necessary adjustment by adding the connection attribute DataTypeScale=-2 to the AWS DMS source endpoint. This modification provides that the correct scale value is set, allowing for accurate migration of the numeric data type.
Special handling for degree of parallelism
Degree of parallelism is a feature on Oracle that allows parallel runs on the same table using multiple CPUs. The operation mechanism of AWS DMS is based on a direct path load by loading a direct path stream that contains data for multiple rows of operations. However, these operations could try to modify the same table in parallel when the source table was using a degree of parallelism. Under this circumstance, the AWS DMS task could fail because it wasn’t permitted to use direct load to carry out these operations on the same table.
To rectify this situation, we added an extra connection attribute on the AWS DMS target endpoint to specify useDirectPathFullLoad=N to reduce using the direct path approach. We also needed to identify tables that enabled the parallelism mechanism. We disabled this feature on that table using alter table table_name noparallel.
Best practices for operating business-critical applications with Amazon RDS for Oracle
In this section, we share some additional best practices while operating business-critical applications with Amazon RDS for Oracle.
Use Amazon RDS and Oracle monitoring tools
Enhanced Monitoring and Amazon RDS Performance Insights are useful built-in monitoring features. These features allow you to gain a comprehensive understanding of the performance of the DB instance, including the load on your database, performance bottlenecks, and other issues that may be impacting performance. With this information, you can optimize the DB instance for better performance, proactively manage your database, and troubleshoot issues as they arise. You can also use these features to diagnose performance issues and take corrective action before they impact users. With Performance Insights and Enhanced Monitoring, you can know that your DB instance is running at peak performance and meets the demands of the users.
For customers who used Oracle Enterprise Manager (OEM) for monitoring SuperCluster, Amazon RDS for Oracle also supports Management Agent through the use of the OEM_AGENT option, and communicates with Oracle Management Services (OMS).
Check the Availability Zone of upstream applications after failover on Amazon RDS for Oracle
Some legacy applications are used to run tasks on Amazon RDS for Oracle involving recursive queries, and they can be sensitive to latency. These application servers might need to stay closed with databases within the same Availability Zone. In case there is a failover on the RDS for Oracle primary node moving to another Availability Zone, additional latency would be introduced between the applications and databases due to different Availability Zones. But this could introduce longer runtime and impact application performance.
In such scenarios, you need a mechanism to monitor the latency and residency of the Availability Zone for both applications and databases. For these latency-sensitive applications, you need to implement an application-level failover mechanism to verify the same residency of Availability Zone for both application and database tiers.
You may consider subscribing to RDS Events to stay informed about failovers in your Amazon RDS environment. By doing so, you can receive notifications and promptly react to failover events, minimizing downtime and maintaining the availability of your database. This proactive approach helps you stay on top of critical events and take appropriate actions to mitigate the potential impact on your applications and users.
Improve overall performance
For Oracle SuperCluster incorporating with Exadata features, many read operations could be handled at the storage tier without consuming resources on the Oracle DB instance. For migrating heavy read applications from Oracle SuperCluster to Amazon RDS for Oracle, simply scaling up to a larger RDS for Oracle instance might not tackle the high read requests effectively.
In this situation, consider using an RDS for Oracle read replica within the same Availability Zone to offload the read requests from the RDS for Oracle primary node. Note that additional investment is required for Active Data Guard licenses because you’re using a read replica instead of a mounted replica in this scenario.
Next, consider using the m5d, r5d, x2idn and x2iedn instance types, which support the instance store for temporary tablespaces and the Database Smart Flash Cache in Amazon RDS for Oracle. These instance types are an ideal fit for applications that need access to high-speed, low-latency local storage, including those that need temporary storage of data for scratch space, temporary files, and caches.
We can use SQL analyzer to perform profiling, baselining to identify queries running with suboptimal run plans, and tune them in order to reduce their I/O footprints.
Finally, there are a number of optimizer parameters in Amazon RDS for Oracle that we can change to compensate for features from Oracle Exadata. These parameters include optimizer_mode, parallel_execution_enabled, parallel_degree, and parallel_max_servers. The default values for these parameters are different from the value settings on Oracle Exadata. You can adjust these parameters if necessary during the SQL tuning process.
In case there is a high usage on Exadata features like Smart Scan and Storage Indexes by the original database instance on SuperCluster, we can consider using a larger instance with more compute power and memory to bridge the gaps benefited by these Exadata features.
Summary
In this post, we demonstrated a real customer case involving a large database migration for business-critical applications from Oracle SuperCluster with Exadata to Amazon RDS for Oracle. In addition to the migration methodology, we shared some important lessons learned throughout the migration process and recommendations to operate business-critical systems on Amazon RDS for Oracle in a production environment.
If you have any comments or questions, leave them in the comments section.
About the Authors
 Raymond Lai is a Senior Solutions Architect with a focus on serving large enterprise customers. He works with customers to migrate complex enterprise systems to AWS, build enterprise data platforms, discovering and designing solutions on AI/ML use cases. Raymond also enjoys swimming outside of work.
Raymond Lai is a Senior Solutions Architect with a focus on serving large enterprise customers. He works with customers to migrate complex enterprise systems to AWS, build enterprise data platforms, discovering and designing solutions on AI/ML use cases. Raymond also enjoys swimming outside of work.
 Alvin Liu is an Enterprise Support Technical Account Manager (TAM) specializes in Cloud Operations and Databases. He leverages his expertise to provide guidance and technical support to customers, assisting them in creating scalable, resilient, and cost-effective solutions. Beyond his professional life, Alvin is passionate about traveling and enjoys spending time with his family and friends.
Alvin Liu is an Enterprise Support Technical Account Manager (TAM) specializes in Cloud Operations and Databases. He leverages his expertise to provide guidance and technical support to customers, assisting them in creating scalable, resilient, and cost-effective solutions. Beyond his professional life, Alvin is passionate about traveling and enjoys spending time with his family and friends.