AWS Database Blog
How HotelTrader cut inter-AZ cost 95% and latency by 49% with Valkey GLIDE on Amazon ElastiCache
This is a guest post by Sundeep Kumar S, VP of Engineering at HotelTrader, and Deepak Prasad, Staff Engineer at HotelTrader, in partnership with AWS.
Hotel Trader operates the exchange, an open hotel exchange connecting hotels directly with travel buyers worldwide. Built as purpose-designed infrastructure, The Exchange integrates directly with property management systems, enabling hotels to connect and start selling in under 8 minutes. Our AI-driven insights analyze billions of data points, and our service processes approximately 15,000 API requests per second, with each request performing multiple cache lookups for property metadata, rates, and currency data.
Our microservices architecture relies on Amazon ElastiCache for Valkey with Multi-AZ configuration to deliver the low-latency, high-throughput performance our hotel search API demands handling approximately 15,000 requests per second with consistent sub-millisecond response times. As we analyzed our infrastructure costs during rapid growth, we identified an optimization opportunity in our cache request routing across availability zones. With a read-heavy workload transferring approximately 43 terabytes per day across AZs, our inter-AZ data transfer costs had reached ~$12K per month, constraining our ability to invest in further cloud innovation.
We migrated to Valkey GLIDE, one of the official Valkey open-source client libraries backed by AWS and designed for reliability and optimized performance. By implementing availability zone-aware routing and request batching, we achieved a 95% reduction in Inter-AZ data transfer costs and 49% latency improvement.
This post explains how we identified our Inter-AZ cost problem, implemented Valkey GLIDE with AZ-aware routing, and achieved these results through a zero-downtime migration.
Understanding the problem: Hidden costs in multi-AZ ElastiCache cluster
We operate a high-throughput hotel property search API that processes approximately 15,000 requests per second across 40–65 Amazon Elastic Container Service (Amazon ECS) tasks. Each request performs multiple cache lookups for property metadata, rates, margins, and currency data against a Multi-AZ Amazon ElastiCache Valkey 8.x cluster with cluster mode enabled with 2 replicas per shard spread across 2 AZs. With a read-heavy workload (>99% reads), the system transferred approximately 43 terabytes per day across availability zones.
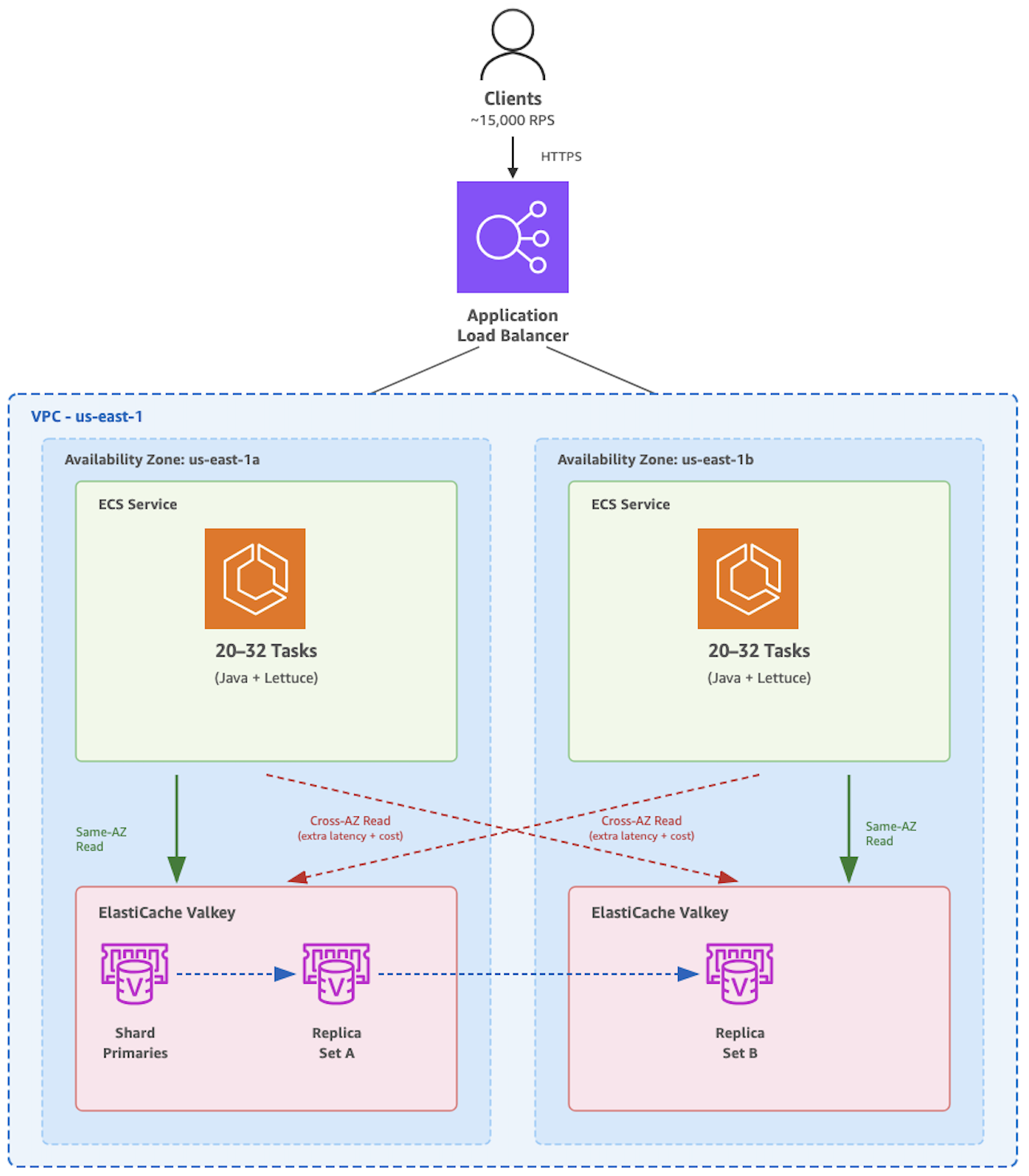
However, we faced a significant challenge with our previous Redis client (Lettuce), wherein inter-AZ data transfer costs reached $15K per month because of the cross-AZ data transfer between Amazon ECS and Amazon ElastiCache alone.
There is no charge for data transfer between Amazon Elastic Compute Cloud (Amazon EC2) and ElastiCache within the same Availability Zone (AZ). While standard EC2 Regional data transfer charges of $0.01 per GiB in or out applies when transferring data between an EC2 instance and an ElastiCache node in different AZs of the same Region, you are only charged for the data transfer in or out of the EC2 instance. See ElastiCache pricing for more information.
To identify the root cause, we enabled VPC Flow Logs and used Amazon Athena to analyze traffic patterns between Amazon ECS tasks and Amazon ElastiCache nodes. The analysis showed that cache requests were distributed randomly across available Amazon ElastiCache nodes, regardless of availability zone placement. This confirmed the limitation that the Lettuce client lacked availability zone awareness, routing requests across zones even when local replicas were available, generating substantial data transfer charges.
For more information about how to use VPC Flow Logs to identify inter-AZ data transfer cost, see the CFM Tips ElastiCache Data transfer section.
The solution: Valkey GLIDE with AZ-affinity reads
We adopted Valkey GLIDE, one of the official Valkey open-source client libraries backed by AWS, to address our cost and performance challenges. The Valkey GLIDE team designed it for reliability, optimized performance, and high-availability for Valkey and Redis OSS-based applications.
Implementation required only two weeks of development effort for our Java-based Spring Boot application. The solution uses Amazon ElastiCache’s multi-AZ architecture and GLIDE’s intelligent routing capabilities, which routes read requests to local replicas, falling back gracefully through a four-tier hierarchy when needed.
This post describes our caching architecture challenges and explains how we improved both cost efficiency and performance by migrating from Redis Lettuce to Valkey GLIDE with availability zone-aware routing.
Valkey GLIDE read strategies
You can choose from four read strategies with Valkey GLIDE to optimize your workload.
- The PRIMARY strategy always reads from the primary node to support data freshness.
- The PREFER_REPLICA strategy distributes requests among the replicas in a round-robin manner (alternating between available replicas in sequence) and falls back to the primary if no replica is available.
- The AZ_AFFINITY strategy prioritizes replicas in the same AZ as the client, falling back to other replicas or the primary if no local replicas are available.
- The AZ_AFFINITY_REPLICAS_AND_PRIMARY strategy goes further: it prioritizes local AZ replicas, then falls back to the primary in the same AZ, and only routes to other AZs if neither is available.
For our read-heavy workload (>99% reads), we selected AZ_AFFINITY_REPLICAS_AND_PRIMARY to maximize cost savings while maintaining high availability.
Configuration and implementation
The following code shows how we initialized the Valkey GLIDE client with availability zone awareness. The readFrom setting controls the read strategy, and the clientAZ setting passes the detected AZ to Valkey GLIDE. Notice the conditional logic: if an AZ is detected, the client uses AZ_AFFINITY_REPLICAS_AND_PRIMARY.
The ReadFrom.AZ_AFFINITY_REPLICAS_AND_PRIMARY setting instructs Valkey GLIDE to prefer replicas in the same availability zone for read operations, following this fallback order: (1) Replicas in the same AZ (round-robin), (2) Primary in the same AZ, (3) Replicas in other AZs, (4) Primary in other AZs.
Note: The code snippets in this post omit authentication configuration for brevity. For production deployments, configure authentication for your ElastiCache cluster using IAM-based authentication, Role-Based Access Control (RBAC) with user groups, or AUTH tokens as appropriate. Enabling encryption in transit is a prerequisite for authentication.
Detecting the availability zone automatically
Automatically detecting the availability zone is essential for continuous operation across Amazon ECS tasks. We implemented a multi-layered detection approach with fallback logic.
The following code shows the priority order: first, an environment variable provides the highest-priority override; second, the ECS Task Metadata endpoint retrieves the AZ from the running task; and third, Amazon EC2 Instance Metadata Service v2 (IMDSv2) provides a final fallback.
This approach queries the ECS Task Metadata endpoint (V4) first. The ECS Task Metadata endpoint V4 is an HTTP endpoint provided by the Amazon ECS agent that returns JSON metadata about the running task, including its placement Availability Zone. It then falls back to Amazon EC2 instance metadata, supporting compatibility across different compute environments.
The ECS metadata endpoint provides the availability zone information directly from the task’s placement. The following code focuses on the HTTP request to the ECS_CONTAINER_METADATA_URI_V4 environment variable to retrieve the task’s AZ:
Application migration effort: Minimal code changes, maximum impact
One of the most common concerns we hear from teams considering a move from Lettuce to Valkey GLIDE is the perceived complexity of application changes. Our experience proved this concern unfounded. The migration required minimal code modifications with substantial performance and cost benefits.
The core migration involved three straightforward changes to our Spring Boot application:
- Swapping the Lettuce dependency for Valkey GLIDE in our build file.
- Replacing our Lettuce connection factory with GLIDE client configuration (approximately 30-40 lines).
- Mapping commands through a thin adapter layer (less than 200 lines). For example,
stringCommands.get(key)becameclient.get(key).get().
The entire development effort, including coding, unit testing, and integration testing, took only two weeks with a single developer. No architectural changes were required, and our existing Redis data structures, TTL policies, and eviction strategies remained unchanged.
Note: For Spring-based applications, migration to Valkey is now even more streamlined with the recent launch of Spring Data Valkey, which provides first-class integration between Spring and Valkey. Learn more at spring.valkey.io and the Spring Data Valkey announcement.
Optimizing with request batching
Beyond AZ-aware routing, we reduced network overhead by implementing request batching. Instead of issuing multiple individual hget calls to retrieve hash fields, we used Valkey hmget operation to retrieve multiple fields in a single request.
The following code shows the batching implementation. Pay attention to how fieldArray serializes multiple keys at once, reducing the number of network round trips from N to 1 for N fields:
This batching approach reduced network round trips substantially. It’s an important optimization for high-throughput workloads. Combined with AZ-aware routing, batching contributed to the 49% latency improvement we describe in the following sections.
Migration strategy: Zero-downtime A/B testing
Rather than a risky single-step migration that switches all traffic at once, we implemented a gradual rollout using A/B testing. We shifted traffic from Java Lettuce to Valkey GLIDE incrementally over 15 days, with careful monitoring at each stage.
We tracked migration progress with a combination of technical and cost metrics. Monitored latency (average and P99), error rates, and CPU utilization alongside Inter-AZ data transfer cost. The validation criteria required zero 5xx errors, acceptable latency, and a measurable cost reduction before advancing to the next traffic increment.
| Metric | With Java Lettuce | With Valkey GLIDE | Delta |
| Avg Latency | 48.2ms | 24.6ms | -23.6ms (49% faster) |
| P99 Latency | 464.5ms | 123.8ms | -340.7ms (73% faster) |
| Max Latency | ~60s (timeouts) | ~20s | -67% better |
| Daily Requests | ~850M | ~954M | +12% more traffic |
A rollback plan was in place to immediately shift traffic back to Java Lettuce if any issues appeared. This approach gave us confidence at each stage and allowed us to verify the cost and performance improvements before full commitment.
Results
We achieved measurable results across multiple dimensions with this approach. The following sections break down the cost reduction, performance improvements, and operational outcomes.
Cost reduction
Our inter-AZ data transfer cost reduced by 95% during the rollout. The following table shows the daily cost at each stage of the migration:
| Day | Cost/day | Notes |
| Day 0 | $420 | 100% Lettuce |
| Day 1 | $404 | A/B testing started |
| Day 5 | $264 | ~50% on Valkey GLIDE |
| Day 9 | $81 | ~95% on Valkey GLIDE |
| Day 10 | $18 | 100% Valkey GLIDE |
| Day 15 | $18 | Steady state |
Final cost reduction: From ~$420/day to ~$18/day ~ 95% reduction representing approximately $147K in annual savings.
Performance and operational improvements
Beyond cost savings, we achieved significant performance improvements. Average latency decreased by 49%, dropping from 49ms to 25ms, a reduction that includes the benefits of request batching. P99 latency improved by 28%, falling from 259ms to 187ms. The latency improvements directly enhanced user experience. Faster cache responses translated to faster API responses, improving the hotel search experience for end users.
Throughout the migration, we maintained HotelTrader’s operational standards. The gradual rollout ensured continuous service availability with zero downtime and no 5xx errors during the 15-day migration period.
Conclusion
HotelTrader’s migration to Valkey GLIDE shows how smart technical choices can cut costs through targeted optimization rather than complete system rebuilds. By connecting applications to the nearest reader node first and batching requests together, we achieved 95% lower data transfer costs and 49% faster response times.
One of the key factors contributing to our success was exceptional AWS partnership throughout the journey. AWS Technical Account Managers, Solutions Architects, and ElastiCache specialists provided continuous hands-on guidance, code reviews, and optimization recommendations at every stage. The migration was executed safely through gradual testing and rollout.
To achieve similar results, analyze your data transfer costs between availability zones, consider smarter caching for read-heavy workloads, and test changes carefully before production deployment. Engage your AWS account team early for personalized guidance. You can also join community forums or attend workshops to learn more.