AWS Database Blog
Long-term storage and analysis of Amazon RDS events with Amazon S3 and Amazon Athena
Database administrators and operations teams often need to analyze historical events for compliance, troubleshooting, and operational insights. Amazon Relational Database Service (Amazon RDS) and Amazon Aurora MySQL-Compatible and PostgreSQL-Compatible Edition generate important events that provide insights into database operations, including backup status, configuration changes, security updates, and maintenance notifications. However, these events are only retained for 14 days. In this post, we show you how to implement an automated solution for archiving Amazon RDS events to Amazon Simple Storage Service (Amazon S3). We also discuss how to analyze the events with Amazon Athena which helps enable proactive database management, helps maintain security and compliance, and provides valuable insights for capacity planning and troubleshooting.
Solution overview
The solution uses AWS Lambda and Amazon EventBridge to automatically capture and archive Amazon RDS events to Amazon S3. It uses a tag-based approach to identify which RDS cluster/instances to monitor, making it flexible and scalable. It also provides an optional data analysis layer using Amazon Athena.
By archiving these events to Amazon S3, you can unlock numerous benefits:
- Enhanced compliance capabilities
- Comprehensive historical analysis
- Improved troubleshooting
- Robust audit trails
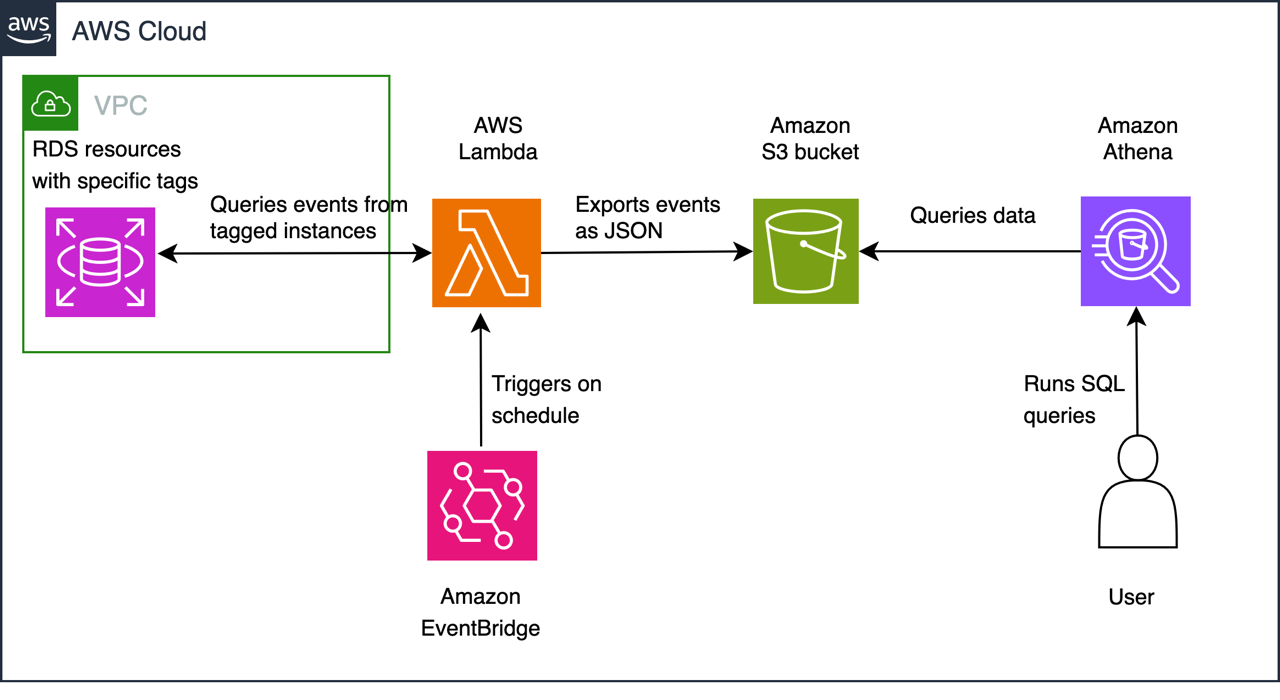
The above diagram displaying the solution follows the below steps:
- EventBridge triggers a Lambda function on a schedule
- The lambda functions uses the AWS SDK to query Amazon RDS for instances and clusters tagged with specific key-value pairs
- For each tagged cluster/instance, the function calls the Amazon RDS
describe_eventsAPI to retrieve events from the previous 24 hours - The function processes the events, formatting them as JSON documents with standardized fields including timestamp, source identifier, event type, and detailed messages
- Then, it writes the output to Amazon S3 following a partitioned structure (YYYY/MM/DD) for optimal query performance and cost efficiency. This partitioning strategy allows for efficient data lifecycle management and reduces the amount of data scanned during queries. For more information about partitioning best practices, see Partition your data using Amazon Athena
- To enable SQL-based analysis, the solution creates an external table in Athena that maps to the JSON structure in Amazon S3. This allows users to write standard SQL queries to analyze historical events, identify patterns, and generate reports.
Prerequisites
To implement the solution described in this post, you must have the following prerequisites:
- One or more Amazon RDS instances or Amazon Aurora MySQL and PostgreSQL DB clusters that you want to monitor
- An Amazon S3 bucket to store the events
- An IAM policy allowing the s3:PutObject, s3:GetObject, and s3:ListBucket permissions on the Amazon S3 bucket previously created.
- An IAM role for Lambda and attach:
- The preceding policy
AmazonRDSReadOnlyAccessAWSLambdaBasicExecutionRole
Create a Lambda function
In this section you create the Lambda function that will be triggered periodically to upload the Amazon RDS events to an S3 bucket of your choice. Go to the AWS Management Console for AWS Lambda and choose Functions in the navigation pane.
- Choose Create function.
- For Function name¸ enter a name (for the example in this post, use
RDSEventsExportToS3). - For Runtime, choose Python 3.13.
- For Execution role select Use an existing role.
- For Existing role select the role you created as part of the prerequisites.
- Choose Create function at the bottom of the page.
- On the Lambda function details page, go to the function code section and replace the sample code with the following:
- Choose Deploy to save your changes.
- Navigate to Configuration and then Environment variables.
- Configure the following environment variables:
- S3_BUCKET = S3 bucket name.
- TAG_KEY =
archive - TAG_VALUE =
true - DURATION = Amount of RDS Events to export in minutes (for example,
1440).
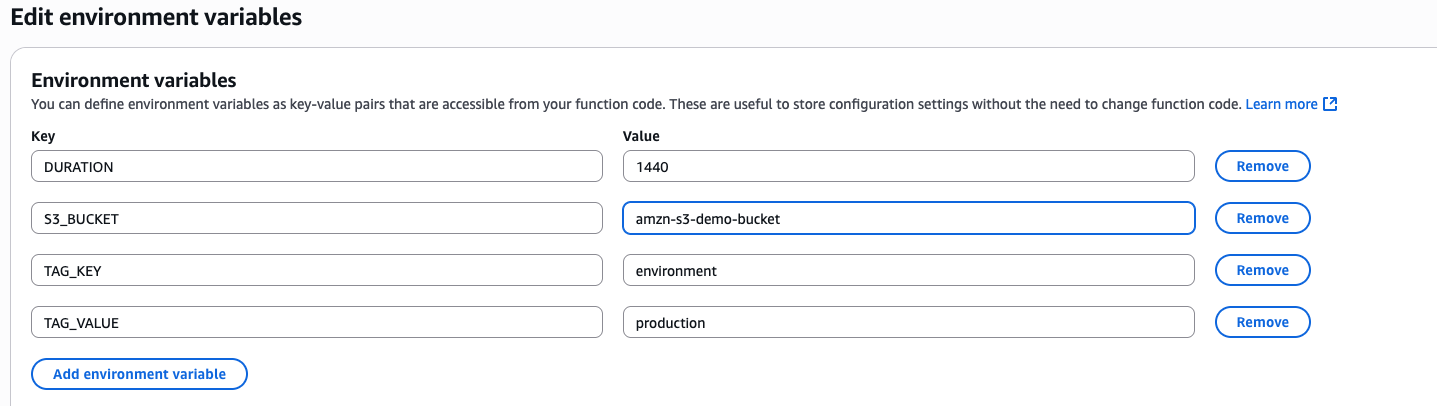
- Choose Save in the bottom right.
- Navigate to General configuration within the Configuration tab.
- Choose Edit and set the Lambda timeout to 10 seconds.
- Adjust the Memory allocation for the Lambda function. If the function doesn’t have enough memory, it may not be able to process all events successfully. You can monitor memory utilization through Amazon CloudWatch to determine the optimal configuration for your workload. Viewing your Lambda Insights metrics.
- Choose Save to save your changes.
Create an EventBridge schedule
Now you create an EventBridge schedule that will periodically trigger the Lambda function. For the example in this post, you will export Amazon RDS events daily, but you can change this if desired.
Note that if you change the schedule to another time interval, you must also change the DURATION environmental variable within the Lambda function to reflect this interval. You can also change the rate expression to run the Lambda function more frequently – this can help reduce the Lambda functions memory consumption.
- In the EventBridge console, choose Schedules in the navigation pane.
- Choose Create schedule.
- For Name, enter a name (for the example in this post, use
RDSEventsExportSchedule). - For Occurrence, select Recurring schedule.
- For Time zone, select UTC.
- For Schedule type, select Rate-based schedule.
- For Rate expression, enter
1 dayas the unit. - For Flexible Time Window, select Off.
- Choose Next.
- For Target API, select Templated targets.
- Select AWS Lambda Invoke.
- Select the AWS Lambda function RDSEventsExportToS3 from the dropdown and choose Next.
- Review your configuration and choose Create schedule.
Tagging RDS instances and/or Aurora Clusters
Now, you have a solution that exports Amazon RDS events daily to Amazon S3 for any RDS instance or Aurora cluster that’s tagged with archive=True. You can tag your instances and clusters to start exporting their Amazon RDS events to S3 using the following steps:
- Navigate to the Aurora and RDS Dashboard.
- Choose Databases on the navigation pane.
- Select the instance you want to monitor.
- Choose Tags and then Manage Tags.
- Choose Add new tag.
- For key, enter
archiveand for value, entertrue. - Choose Save changes.
The environment variables within the Lambda function control what the key and value combination must be when tagging your RDS instance. If you want to change the key or value, you can edit the Lambda function’s environment variables (TAG_KEY and TAG_VALUE).
Up to this point, you have configured a fully working solution to store Amazon RDS events within Amazon S3 once a day. Remember that you can change the frequency of the Lambda function’s execution, however you must alter the rate expression shown within step 7 of the EventBridge creation and also the duration variable in the Lambda code. If you want to build an analytical solution for the data within Amazon S3, continue to the next section, if not you can skip to the Clean up and Limitations sections.
Set up Athena
By using Lambda, EventBridge, and Amazon S3, you’ve created a serverless architecture that automatically captures and archives Amazon RDS events.
Now that you have Amazon RDS event data stored as JSON files on Amazon S3, you can use Athena to query the data. If you don’t want to add this analytical component, you can skip to the next section.
- Open the Amazon Athena console.
- Choose Query Editor in the navigation pane.
- If you haven’t used Athena before you must configure an S3 bucket to store query results. To learn more, see Get started in the Athena User Guide.
- Create a new database:
- Create an external table for the Amazon RDS events (note this can be customized depending on use case).
Now, you can query the Amazon RDS events depending on the data you want to gather. You can monitor backup compliance, track configuration changes across your Amazon RDS fleet, identify security-related modifications, and detect patterns in maintenance events. For example, the following query gathers the Amazon RDS events where a backup has started:
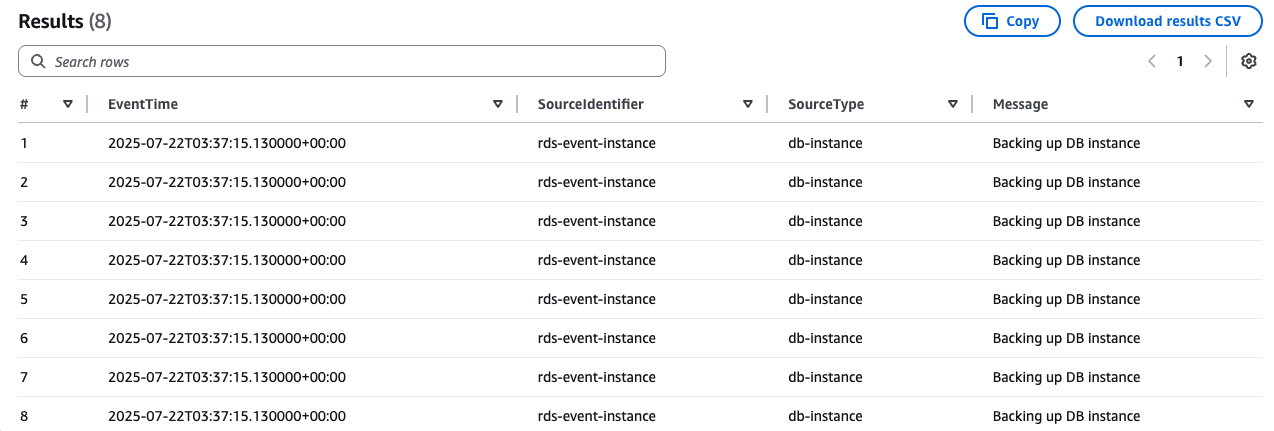
For a full list of the RDS instance and cluster events please visit AWS documentation.
Clean up
To avoid incurring future charges, use the following steps to delete the resources you created if you no longer need them.
- Delete the EventBridge schedule.
- Delete the Lambda function.
- Remove Athena resources (if configured):
- Open the Athena console
- Execute the following SQL commands:
- Empty the Athena query results S3 bucket if no longer needed.
- Delete the Amazon S3 bucket contents and bucket.
- Delete IAM resources.
- Remove tags from RDS instances (optional) if the
archive=truetag is no longer needed.
Make sure to delete resources in all AWS Regions where you deployed this solution.
Limitations and Next Steps
This solution has some limitations that you need to consider before implementing it in production:
- This solution doesn’t work across multiple AWS accounts.
- This solution doesn’t automatically purge old data in Amazon S3. To automatically purge old data, consider implementing S3 Lifecycle.
- Newly created RDS instances aren’t automatically tagged. Review the Tagging RDS instances section for more details on how to tag RDS instances.
You can customize your Lambda function to address specific needs, such as filtering for specific RDS event types. This will allow for more targeted monitoring and response. Additionally, using Athena to create views of your data enables more sophisticated querying and analysis of your RDS events, providing deeper insights into your database performance and health. Also consider implementing business intelligence tools to further analyze the collected data, helping you identify trends, patterns, and potential issues before they become critical. Finally, integrate your RDS event data with Amazon QuickSight. You can use it to transform your raw data into intuitive, interactive dashboards. By implementing these enhancements, you’ll create a more robust, insightful, and actionable RDS monitoring system.
Conclusion
In this post, we’ve presented a solution that you can use to archive Amazon RDS events to Amazon S3 for long-term storage and analysis. We invite you to implement this solution in your own environment and explore its potential.