AWS Database Blog
Modeling a scalable fantasy football database with Amazon DynamoDB
Today’s online games generate more data than ever and have request rates that reach millions per second. For these data-intensive games, it’s important for developers to select a database that delivers consistent low latency at any scale and has throughput elasticity to accommodate spikes in traffic without costly overprovisioning during low activity periods. This is why Amazon DynamoDB is a popular database service for games. DynamoDB is a serverless, key-value NoSQL database that delivers consistent low latency results and high availability, with a low level of administrative overhead whether your game generates one request per month or one million requests per second. Some of the key reasons game developers use DynamoDB are:
- Scalability: DynamoDB offers nearly unlimited throughput and storage with flexible pricing models that scale with your workload.
- Fully managed: DynamoDB handles most administrative tasks such as patching and backups so that you can focus on developing your game. DynamoDB being serverless means you don’t have to provision or manage instances or storage. It automatically scales capacity to meet workload demand, provides pay-per-use pricing, and all you need to get started is to create a table.
- Global tables: DynamoDB global tables provide a fully managed, multi-Region, and active-active database that enables fast, local read and write performance for massively scaled, global applications.
- Amazon Web Services (AWS) integrations: DynamoDB integrates with other services like Amazon Kinesis Data Streams for streaming item changes, AWS CloudTrail for logging, AWS Lambda for invoking actions, and other services as needed. To learn more, see the DynamoDB features page.
The following architecture diagram depicts a production-ready game running on AWS and backed by DynamoDB. In this post we focus on DynamoDB table design concepts within the context of the popular fantasy football game type.

Figure 1: Sample architecture for a production-ready game backend on AWS
In this post, we discuss access patterns for a fictitious fantasy football game, and then demonstrate the DynamoDB table schema we designed to satisfy those patterns. We focus on a fantasy football (soccer) league game where friends compete to create the best team rosters using real-world football players and results in a ranked competition. DynamoDB is the backend database of the application used by gamers to manage their teams and track their scores as the football season develops over time. We discuss design considerations for modeling a DynamoDB table to support access patterns for functionalities like team selection, points scoring, and leaderboard support for the game.
How to approach data modeling in DynamoDB
If you’re new to DynamoDB data modeling, it’s important to note that you shouldn’t model your data in DynamoDB using relational database modeling techniques. When using DynamoDB, you must define your access patterns before creating a data model. For most workloads, the goal is to create a data model that is performant and cost effective at any scale. To do this, you must know your application’s access-pattern properties such as data size, data shape, and data velocity.
Generally speaking, there are four steps to crafting a DynamoDB database schema:
- Understand the use case.
- Construct an entity-relationship diagram (ERD).
- List your queries or pseudo-queries (define your access patterns).
- Map the pseudo-queries to appropriate DynamoDB operations.
These techniques also apply when designing schema for most non-relational databases including Amazon Keyspaces (for Apache Cassandra). Some of the benefits of making this tradeoff are high scale and fast performance. Understanding the use case typically involves documenting the workload’s requirements (transaction rate, latency, and durability). If you don’t know what the access patterns are, then you should research similar applications. For the fantasy football use case, you should know what a league, team, and footballer (player) represent and how each entity is accessed in the game. Next, you should create an ERD, which helps you discover relationships between the entities. After you have created an ERD, you can create an ordered list of queries prioritized by how often they’ll be used in the game. At this point, you could also create some sample data to simulate queries and responses. Finally, map your queries to a DynamoDB schema using either NoSQL Workbench for DynamoDB or a spreadsheet. Mapping is the process in which you define a partition scheme, secondary indexes, and write sharding (if your design requires it).
Fantasy football game database (ERD and access patterns)
Whether you’re building a new application with DynamoDB or migrating from another data store, a common first step in the data modeling process is to create an ERD. After you’ve identified the entities and their relationships within your application, you can use any of the common ERD representation formats to build an ERD.
In the ERD for our game, we have five unique entities. The Gamer entity stores information about gamers playing the game (gamers are the users who play the game on their mobile or from a web browser). Gamers create TeamSheets of footballers, which can be entered in any number of Leagues. For simplicity, in this example, a given team will be in only one league. The TeamSheet entity (or game-week roster) is a fixed-size collection of Footballers created each week by the gamers. Footballers can be in more than one team in a league. Footballers belong to one Position, such as midfielder or goalkeeper. Notice that we didn’t create an entity for football clubs; they can instead be modeled as an attribute within Footballer because the application doesn’t have read patterns that require sorting or querying by football club.
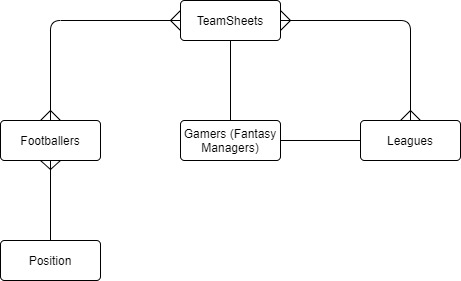
Figure 2: ERD for fantasy football database
Access patterns:
- Look up Gamer details by Gamer ID.
- Get TeamSheet for a Gamer.
- Look up Footballer details by Footballer ID.
- Get Footballers for a given Position.
- Get all Gamers within a League sorted by totalPoints.
Note: In reality, a fantasy football game would have additional access patterns. We’ve chosen these common ones for the purpose of this demonstration.
Modeling entity items
When you’re modeling a schema for DynamoDB, you should try to construct items and item collections to meet the access patterns with acceptable performance at a reasonable cost. An item collection is defined as a group of items with the same partition key value but different sort key values. The flexible schema of DynamoDB allows you to store different types of entities, such as Footballer or League, in the same table if the primary key definition is suitable. This allows for more efficient queries across entities. For our sample application database, we start by modeling top-level entities.
In the following table, notice we use generic names for partition key (PK) and sort key (SK). This is because we plan to take advantage of the schema flexibility of DynamoDB by storing multiple entity types in the table. Another modeling technique we use is prefixing our PK values with the entity name. The pattern for the Gamer entity is Gamer#<GamerName> and the Footballer entity uses the pattern Footballer#<FootballerName>. We do this for two reasons. First, to satisfy the primary key uniqueness constraint in our base table and to avoid overlap between different item types in a table in the case of a common identifier. Second, this allows for a selective begins with pattern with a sort key expression if we choose to use this attribute as the sort key for a secondary index. These basic entities satisfy the first (get Gamer by gamer ID) and third (get Footballer by footballer ID) access patterns.
| Primary Key | Attributes | |||||||
| Partition Key (PK) | Sort Key (SK) | |||||||
| Gamer#Tito12121 | Gameer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | . |
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | – – – | |
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – |
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – |
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||
In DynamoDB, the partition key, as the name suggests, defines how that data is distributed in the underlying storage layer. It’s important to select high cardinality partition key attribute values that allow even distribution of data as the request rates grow in the application over time. See Choosing the Right DynamoDB Partition Key to learn more. As shown in the following table, you can identify entities quickly using the partition key. The partition key value is repeated as the sort key for root (entity) items so they’re distinguishable from other item types.
A sort key is typically used to model one-to-many relationships with other entities. However, for the top-level entity items, we repeat the partition key as the sort key for items that represent the entity data. For example, the Gamer Tito12121 will have a PK value of Gamer#Tito12121 and a SK value of Gamer#Tito12121 for the main item representing Tito12121. You could also use another naming convention like <metadata> or <root>, but that can become a scaling limitation if you need to create a secondary index with the base table sort key as the partition key of a global secondary index.
Modeling one-to-many relationships
There are multiple ways to model one-to-many relationships in DynamoDB. We discuss some of the techniques covered in Item collections – how to model one-to-many relationships in DynamoDB in the following sections.
| Primary Key | Attributes | |||||||
| Partition Key (PK) | Sort Key (SK) | |||||||
| Gameer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | . |
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | – – – | |
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – |
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – |
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||
Using partition key overloading with global secondary indexes
We can use Position as the partition key value for a global secondary index (GSI) to get all footballers that play in a given position. A GSI lets you query the data in the table using an alternate key. Without a GSI, we can only query on the base table’s primary key. In our example, we created a GSI named GSI1 with two attributes named GSI1_PK to hold the GSI partition key value. Similar to the base table schema, we’re using partition key overloading in our GSI keys to allow different entities to reside inside the same index. In applying this design pattern, we must prefix the GSI1_PK with the entity that gives us a GSI1_PK value of Position#Midfielder. This GSI satisfies the fourth access pattern: get Footballers by Position.
| Primary Key | Attributes | |||||||||
| Partition Key (PK) | Sort Key (SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | ||||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
What we did here is overload the GSI to let us get all Footballers in a given Position, while allowing the GSI to be used for other queries in the future. With GSIs, you can choose to project only attributes you’re interested in, which is more performant and cost efficient than projecting all attributes. For example, we can get all Footballers (entities) in the Position midfielder by querying GSI1 where GSI1_PK = “Position#Midfielder”. We chose not to use a GSI write shard for the position because of the low cardinality of footballers for a given position. For more information about this design technique, see Using Global Secondary Index write sharding for selective table queries.
Using item collections
One principle of DynamoDB design is to keep related data together. This means that you store information about a gamer’s TeamSheets (game week rosters) under the Gamer next to important details for the Gamer entity. This technique of pre-joining data using item collections reduces roundtrips to the table to fetch items, leading to faster retrieval times at the expense of duplicating some data in the table. This technique optimizes for compute, which is contrasted with relational databases where you join separate items from different tables to save on storage costs. In the following chart, we have added TeamSheets for Gamer#Tito12121 under the SK values of GW#(N), where GW stands for game week and N represents the game week number. Note how the game week 01 TeamSheet attribute value is a map with multiple Footballers. We decided not to use a more advanced technique called adjacency lists, explained later, because we want to add or remove footballers from the TeamSheet all at once in order to maintain its fixed size limit. This design satisfies the second access pattern: get TeamSheet for a Gamer. As shown in the following diagram, three items—a root item record and two team sheet records—are displayed for Gamer#Tito12121, so we can say all items that have PK = Gamer#Tito12121 are in the same item collection. This modeling technique forms item collections under a PK. When you have item collections like these which represent related data, you can use the query API actions to retrieve multiple items under a partition key at the same time.
| Primary Key | Attributes | |||||||||
| Partition Key (PK) | Sort Key (SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | ||||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
Modeling many-to-many relationships
There are a couple of strategies you can use for modeling many-to-many relationships. In our fantasy football application database example, Footballer-TeamSheet and Gamer-League relationships are examples of many to many relationships.
Using data duplication
One of the most common strategies for modeling many-to-many relationships in DynamoDB is duplicating data. In our fantasy football game, a good example of a relationship that lends itself to this strategy is the Gamer and Footballer relationship. A typical access pattern is fetching players that are in a gamer’s team sheet. As shown in the following table a Gamer creates team sheets containing a selection of Footballers for every game week. In a relational database, you would typically model this by creating a separate TeamSheet table that would use foreign keys to link Footballers to team sheets. In DynamoDB, you can duplicate the TeamSheet data under the Gamer entity, which allows you to fetch all players in a gamer’s team sheet with a single GetItem request. When you use this strategy, it’s important to keep in mind that it works best when there are a limited number of related entities in the duplicated relationship and when the duplicated information doesn’t change often or is immutable.
| Primary Key | Attributes | |||||||||
| Partition Key (PK) | Sort Key (SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | ||||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
Using adjacency lists
The concept of using adjacency lists to represent many-to-many relationships is a common representation for finite graphs in graph theory. In DynamoDB terms, you model the relationship between the entities as an item in the table. In our fantasy football game, the Gamer and League relationship can be modeled using this strategy. To do this, we create an item for each league a gamer has entered under the top-level entity, Gamer.
| Primary Key | Attributes | |||||||||
| Partition Key (PK) | Sort Key (SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| gamer | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| gamer | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| League#1234 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| League#3456 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| League#5678 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| – – – | – – – | – – – | – – – | – – – | ||||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | – – – | |||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||
| GW#01TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – – | |||||
| League#1234 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
With this model, we can fetch all leagues entered by any given gamer, as shown in the following schema.
| Primary Key | Attributes | |||||||||
| Partition Key (PK) | Sort Key (SK) | |||||||||
| Gamer#Tito12121 | Gamer#Tito12121 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 1995 | South Africa | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | – – – | |||||
| GW#01#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| GW#02#TeamSheet | Type | TeamSheet | ||||||||
| teamsheet | {“Captain”:{“S”:”JorgeSouza#7”},”GoalKeeper”:{“S”:”RichardRoe#1”},”Players”:{“SS”:”[KwesiManu#9”,”PauloSantos#10”,”ArnavDesai#20”]};”Subs”:{“SS”:[“JohnStiles#6”,”NikhilJayahankar#17”]}}} | |||||||||
| – – – | – – – | – – – | – – – | – – – | – – – | |||||
| League#1234 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| League#3456 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| League#5678 | Type | GameweekPoints | TotalPoints | |||||||
| league | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||||
| – – – | – – – | – – – | – – – | – – – | ||||||
| – – – | – – – | – – – | – – – | – – – | – – – | – – – | – – – | |||
| Gamer#Seyi89000 | Gamer#Seyi89000 | Type | DOB | Country | GameweekPoints | TotalPoints | – – – | |||
| gamer | 2005 | USA | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | ||||||
| Footballer#KwesiManu#9 | Footballer#KwesiManu#9 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| footballer | 12 | 51 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Striker | – – | ||||
| Footballer#PauloSantos#10 | Footballer#PauloSantos#10 | Type | Price ($_MM) | Select% | GameweekPoints | TotalPoints | GSI1_PK | – – | ||
| Footballer | 9.5 | 22 | {“GW1”:”0.0”,”GW2”:”0.0” …} | 0 | Position#Midfielder | – – | ||||
To get gamers playing in a league using PK = League#<LeagueID> with a single request, we can then add a GSI named GSI2 where League# is the partition key (not shown in the above table). In the GSI, our partition key GSI2_PK value is League#<LeagueID> and sort key GSI2_SK value is TotalPoints. In the application. we must make sure the keys for League and Gamer are kept in sync with the GSI2 primary keys. To satisfy the fifth access pattern (get all Gamers for a given League, sorted by TotalPoints), we can query the given league as partition key and get all the gamers in the league sorted by TotalPoints, no need for client-side sorting.
Access patterns and query mapping
At the end of your modeling exercise, update the access patterns table with example query conditions and table or secondary index keys used to satisfy the access pattern.
| . | Access patterns | Query condition |
| 1 | Look up Gamer details by Gamer ID | Primary key on table, PK = ”Gamer#Tito12121” |
| 2 | Get TeamSheet for a Gamer | Primary key on table, PK = ”Gamer#Tito12121”,
SK = ”GW#01#TeamSheet” |
| 3 | Look up Footballer details by Footballer ID | Primary key on table, PK = ”Footballer#PauloSantos#10” |
| 4 | Get Footballers for a given Position | Use GSI1, GSI1_PK = ”Position#Midfielder” |
| 5 | Get all Gamers within a League sorted by totalPoints | Use GSI2, GSI2_PK = ”League#1234” |
Conclusion
In this post you learned methodologies for designing a scalable data model for storing game play data for a fantasy football game in DynamoDB. You also reviewed a walk-through of how we applied techniques such as denormalization, multiple entity types per index, and adjacency lists to map data access patterns to tables and indexes as required to serve the application. For more in-depth information about gaming design patterns on AWS, see Introduction to Scalable Gaming Patterns on AWS. Also, for additional resources about developing games on AWS, see AWS for Games.
About the authors
 Stanley Chukwuemeke is a Database Solutions Architect. He helps customers architect and migrate their database solutions to AWS.
Stanley Chukwuemeke is a Database Solutions Architect. He helps customers architect and migrate their database solutions to AWS.
 Sean Shriver is a Sr. NoSQL Solutions Architect. Sean helps high profile and strategic customers with migrations, design reviews, AWS SDK optimizations, and proof-of-concept testing for Amazon DynamoDB.
Sean Shriver is a Sr. NoSQL Solutions Architect. Sean helps high profile and strategic customers with migrations, design reviews, AWS SDK optimizations, and proof-of-concept testing for Amazon DynamoDB.
 Kehinde Otubamowo is a Sr. NoSQL Solutions Architect. He is passionate about database modernization and enjoys sharing best practices for building cost effective database solutions that perform at scale.
Kehinde Otubamowo is a Sr. NoSQL Solutions Architect. He is passionate about database modernization and enjoys sharing best practices for building cost effective database solutions that perform at scale.