AWS Database Blog
Architect a Managed Disaster Recovery on Amazon RDS for SQL Server: Part 2
In our last series of posts (Part 1, Part 2, Part 3, and Part 4) , we discussed disaster recovery (DR) terminology and compared the DR solutions available for SQL Server on Amazon Elastic Compute Cloud (Amazon EC2). In this series, we continue to cover the DR solutions available for Amazon Relational Database Service (Amazon RDS) for SQL Server.
In part 1 we explored SQL Server native backup, Amazon RDS Automated and Manual Backups, and cross region replication of RDS backups. In part 2 (this post) we dive into Amazon RDS read replicas, AWS Database Migration Service (AWS DMS), and CLOUDBASIX for RDS SQL Server Read Replicas and Disaster Recovery.
With Amazon RDS Multi-AZ, you get enhanced availability and durability for database (DB) instances within a specific AWS Region. This is often an effective disaster recovery (DR) solution for most use cases. Use in-region read replicas for Amazon RDS for SQL Server when running mission-critical databases with a business requirement for your DR configuration to span across different Availability Zones.
RDS SQL Server read replicas (in-region)
Amazon RDS for SQL Server supports in-region read replicas, which let you offload your read workloads from your primary database instance to a replica. Read replicas use the built-in distributed availability groups feature, and they are available for Enterprise Edition. A distributed availability group is an availability group that spans two separate availability groups. The members of the distributed availability group are the availability groups themselves. Amazon RDS uses a domain-independent Windows Server Failover Cluster (WSFC) for this architecture.
Creating an SQL Server read replica doesn’t require an outage for the primary DB instance. Amazon RDS sets the necessary parameters and permissions for the source DB instance and the read replica without any service interruption. A snapshot is taken of the source DB instance, and this snapshot becomes the read replica. No outage occurs when you delete a read replica. You can create up to five read replicas from one source DB instance. For replication to operate effectively, each read replica should have the same amount of compute and storage resources as the source DB instance. If you scale the source DB instance, then you should also scale the read replicas.
In addition to using read replicas to reduce the load on your source DB instance, you can use read replicas to implement a DR solution for your production DB environment. If the source DB instance fails, then you can promote your read replica to a standalone source server.
The promotion process is manual, and promoting a read replica to a Single-AZ instance doesn’t have any effect on any other read replicas (if any exist), nor does it affect the primary DB instance or its synchronous copy in the Multi-AZ configuration.
RPO and RTO
For DR, RTO is time to failover to the AG secondary replica. RDS use Asynchronous Commit mode to replicate data from primary replica to secondary replica. With asynchronous commit mode, you have to force the failover, thereby accepting the data loss risk. Potential data loss of an asynchronous-commit secondary replica depends on how much log is still waiting to be hardened on the secondary replica. RTO is generally considered as minutes. In this mode, the primary replica sends the transaction log records to the secondary replica, but it doesn’t wait for the acknowledgement for transaction commit. This process is faster, but the RPO value can go up to minutes.
Best practices
If you choose to work with this solution, you should consider the following:
- For replication to operate effectively, each read replica should have the same amount of compute and storage resources as the source DB instance.
- If the source DB instance is scaled, read replicas should be scaled accordingly.
- You must manually copy relevant SQL agent jobs from the primary RDS instance that hosts the original primary replica to the replica instances.
- Synchronization of user logins to read replicas aren’t supported. You must manually create the logins at the read replica.
- You can also use AWS SQLServer-Backup Automation document to automate the process.
Solution overview
The following diagram illustrates the architecture of this solution:
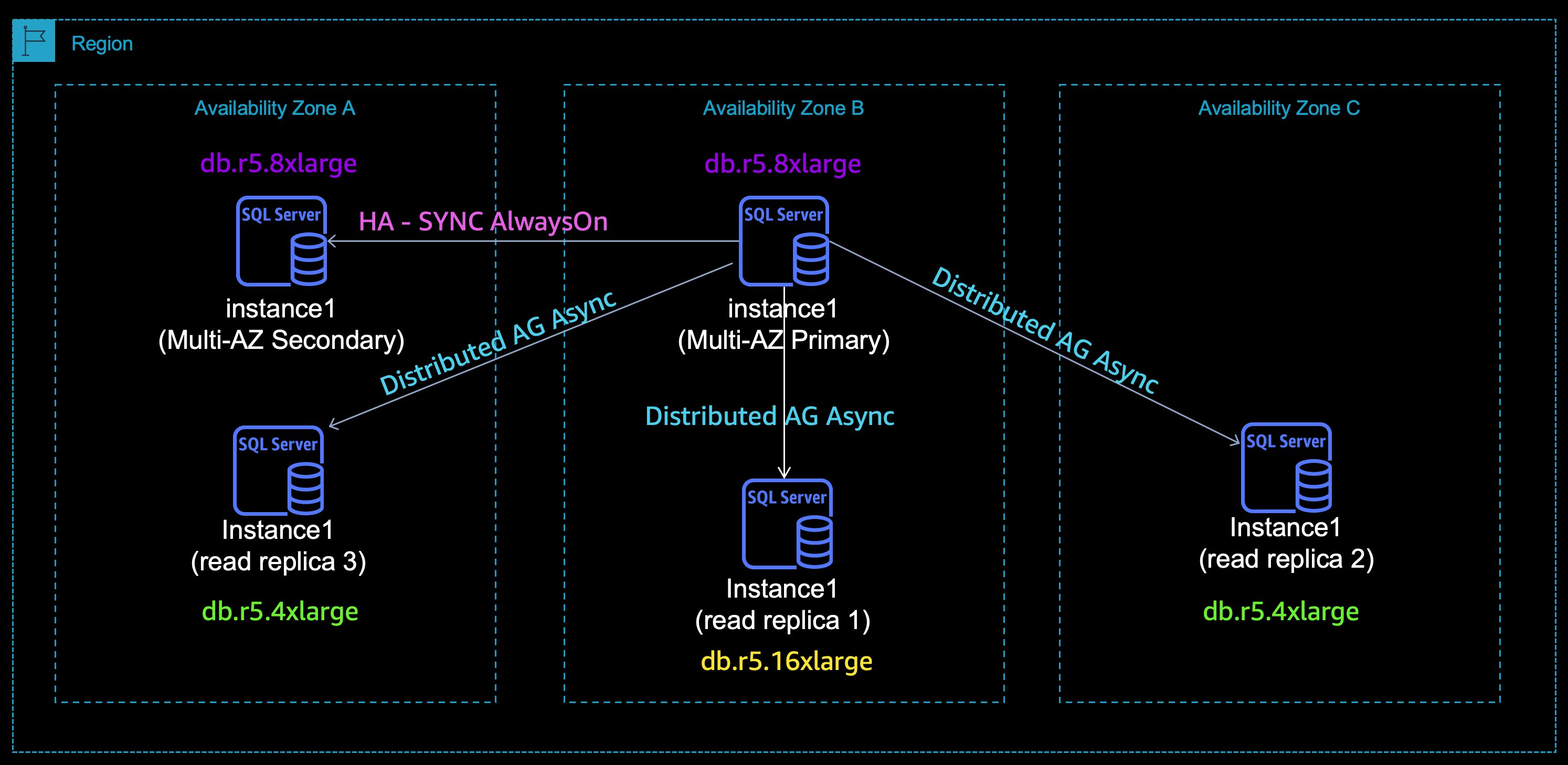
Figure 1 Amazon RDS for SQL server read replicas
In this scenario, you have have a Multi-AZ configuration with a primary instance in AZ-B with synchronous copy secondary instance in AZ-A, and asynchronous copies sent to read replicas in different AZ’s within the same region. The transactions committed on the primary DB instance are synchronously replicated to a secondary replica for high availability purposes, and then asynchronously sent to the read replica for read scale out. A distributed availability group is an availability group that spans two separate availability groups. The primary DB instance is the only copy of the database that can accept both read/write traffic. The read replica can only accept read-only traffic. You are not restricted to having the same instance class. Therefore, you can choose the instance class type depending on your needs.
Failover and failback
Unlike an Amazon RDS Multi-AZ configuration, failover to a read replica is not an automated process. You can promote your read replica to a stand-alone Single-AZ DB instance. Promoting a read replica to a Single-AZ instance does not have any effect on any other read replicas (if any exist), nor does it affect the primary DB instance or its synchronous copy in the Multi-AZ configuration.
Benefits
This solution has the following benefits:
- You can use read replicas to offload your secondary read-only workloads from your primary replica.
- You can create read replicas across different AZ’s for availability.
- Workload can scale to five replicas, relieving pressure on the source DB.
- You can connect to each secondary replica using its reader endpoint.
- Read replicas maintains asynchronous copies of each databases from the primary instance.
Relative cost
RDS replicas do not restrict you from having the same instance class types for read replicas. You can choose the instance class type depending on your needs. This relatively saves compute cost for read workloads.
AWS Database Migration Service
AWS Database Migration Service (DMS) supports the live migration of data to and from AWS, including different Regions. You can use this feature to set up a separate RDS SQL Server instance in a different Region to serve as a DR database. AWS DMS supports full load migration and change data capture (CDC), thereby enabling continuous data replication. Another benefit when using AWS DMS is that, unlike physical replication, which works on the database instance level, AWS DMS is a logical replication solution that lets you migrate a subset of your database, such as a set of tables.
Recovery Point Objective and Recovery Time Objective
The Recovery Point Objective (RPO) of the DR strategy depends on how quickly AWS DMS consumes the captured changes that are available from the source SQL Server instance and applies them to the target. In the DR strategy, the target SQL Server is active so that you could have a near-zero Recovery Time Objective (RTO).
Best practices
If you choose to work with this solution, you should consider the following:
- During ongoing replication, it’s critical to identify the network bandwidth between your source database system and your AWS DMS replication instance. Make sure that the network doesn’t cause any bottlenecks during ongoing replication.
- It’s also important to identify the rate of change and archive log generation-per-hour on your source database system. This can help you understand the throughput that you might get during ongoing replication.
- If you intend to run multiple concurrent replication tasks, consider using one of the larger replication instances.
- If you plan to use ongoing replication, set the Multi-AZ option when you create your replication instance. By choosing Multi-AZ, you get high availability and failover support for the replication instance. However, this option can impact performance and slow down replication while applying changes to the target system.
- For a use case in which AWS DMS replicates the data reading changes from backup only, and when you’re taking log backups on the secondary replica in the Always On AG, you must set an extra connection attribute. This enables AWS DMS to poll all nodes in the Always On cluster for transaction backups. For an example, see the following code: alwaysOnSharedSynchedBackupIsEnabled=false;
For more information about performance considerations, see Improving the performance of an AWS DMS migration.
Solution overview
The following diagram illustrates the architecture of this solution:

Figure 2 Amazon RDS cross region DR with AWS Database Migration Service
In this scenario, you create an AWS DMS instance in Region 1 where your source RDS instance is created. The target instance is created in Region 2 for DR. Then you provide database connection information to connect to both the Source and target database instances in cross regions. Next, you select the tables, schemas, or databases that you want to migrate, and AWS DMS loads the data and keeps it in sync on an ongoing basis. Finally, when you’re ready to cut over, you can change the application configuration pointed to the new Amazon RDS for SQL Server instance in Region 2, instead of the existing Region 1 database.
Failover and failback
Failover in AWS DMS is a manual process. After the source and target databases are synchronized, and when the application is ready for cutover, the replication task is stopped and applications are configured to connect to the SQL Server instance running on Amazon RDS for SQL Server.
If a failback is required, your production databases are no longer in sync with the DR databases. Any changes that occurred on the target database post-cutover are ignored or lost, or those changes have to be manually re-applied on the source database. You must reconfigure the replication task from the DR database to the source database.
Benefits
This solution has the following benefits:
- You can create DR environment with minimal downtime
- Supports widely used databases
- Allows replication between different SQL Server editions and versions
- Allows replication between different AWS accounts
- Ongoing replication lowers the risk of data loss
Relative cost
With AWS DMS, you pay for the compute resources used during the migration process and any additional log storage. If you’re running an SQL Server database using Enterprise Edition and have a requirement to offload read workloads to secondary read replicas, then you can use AWS DMS to replicate data to a secondary database using SQL Standard Edition to reduce the licensing cost.
CLOUDBASIX for RDS SQL Server Read Replicas and Disaster Recovery (DR)
CloudBasix facilitate a seamless deployment option of enabling fully automated Amazon RDS for SQL Server cross-Region disaster recovery.
CLOUDBASIX for RDS SQL Server Read Replicas and DR is a cloud-native solution that was designed to integrate with other AWS services. This makes the product particularly suitable as the backbone of a comprehensive DR setup.
RPO and RTO
In a CLOUDBASIX cross-region replication cluster, configured to operate in a Minimize RTO/RPO mode, the RTO is defined by the time it takes to only load pending changes. This is a small fraction of the overall replication latency time. Even if the entire primary region goes down, the surviving part of the CLOUDBASIX cluster finalizes the processing of data in transit.
Proper configuration and sizing of the CLOUDBASIX cross-region cluster and the DR RDS lets you achieve near-zero RTO in most scenarios.
Best practices
If you choose to work with this solution, you should consider the following:
- Deploy CLOUDBASIX in a cross-region cluster, with the activation of Minimize RTO/RPO replication mode, is essential to achieving replication high availability and lowering RTO below the overall replication latency.
- Although CLOUDBASIX recommends semi-automatic failover with the initiating of failover manually, automatic activation of the failover process can be achieved by automated monitoring of the RDS in the primary region for an unhealthy state. Follow the recommended CLOUDBASIX cross-region architecture, which features integration with other AWS services, such as Amazon Route 53 and AWS Lambda, to orchestrate a fully automated failover.
Solution overview
The following diagram illustrates the architecture of this solution:
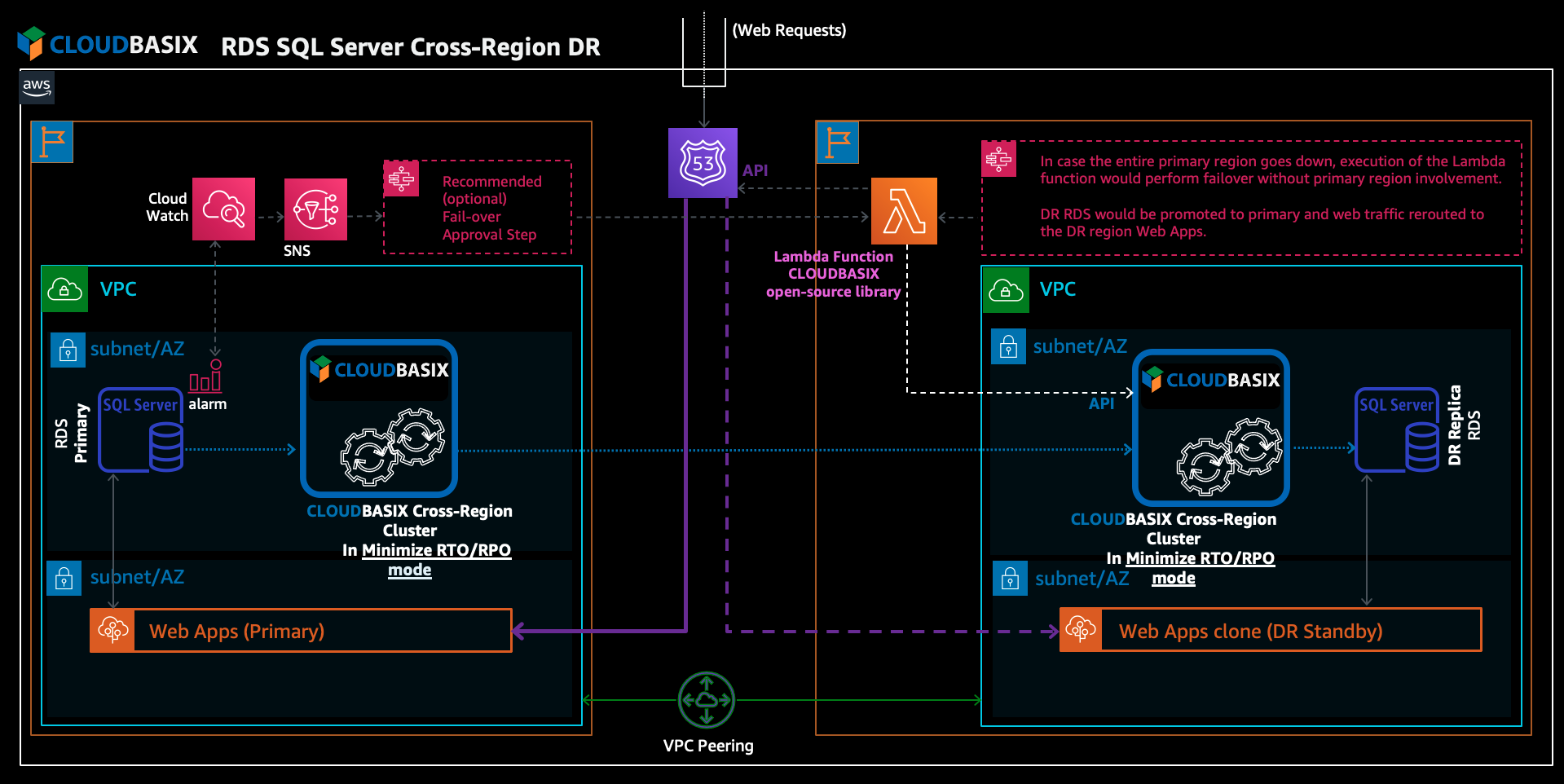
In this scenario, the cluster of CLOUDBASIX continuously replicates Amazon RDS for SQL Server data and database schemas cross-region in a Minimize RTO/RPO mode, with RTO lower than the overall replication latency. This is the result of replication processing distributed throughout its cloud-native HA clustering mechanism.
Primary Region Amazon RDS for SQL Server unhealthy state detection triggers a request to execute the Lambda function (with a recommended but optional approval step). This calls CLOUDBASIX Cluster’s API & Route53’s API, to promote DR replica databases to primary, and reroute web traffic to the DR standby Web Apps clone respectively.
Failover and failback
CLOUDBASIX is designed to tolerate intermittent outages, such as cross-region degradation of connectivity. Temporary primary region downtimes would not result in data loss, and they should not necessarily be considered DR events triggering failover.
The failover and failback processes with CLOUDBASIX are subject to full automation. The failback process (not illustrated in the diagram) can be part of the main Lambda function or implemented as a separate function.
Leveraging CLOUDBASIX’s API along with other Amazon services, such as Amazon Route 53 and AWS Lambda, allows for the orchestration of a fully automated failover and failback.
While CLOUDBASIX recommends for the failover process to be activated manually, the process can be automatically triggered by setting up alarms monitoring for RDS unhealthy state in the primary region.
Benefits
This solution has the following benefits:
- CLOUDBASIX is designed to deliver low RTO/RPO, RTO lower than the overall replication latency, as a result of replication processing distributed throughout its cloud-native cross-region cluster.
- You can use CLOUDBASIX to mask data on the field/column level
- CLOUDBASIX is designed to tolerate the degradation of connectivity and other intermittent outages.
- You can create cross-Region and in-Region read replicas for SQL Server Enterprise, Standard, and Web editions.
- CLOUDBASIX supports replication between different versions and editions of SQL Server. This functionality is essential in on-premises to AWS DR scenarios.
- Replication between AWS accounts is supported.
Relative cost
CLOUDBASIX supports the replication of a large number of databases on a single properly sized cluster, and the aggregation of workloads from multiple RDS instances. This contributes to a substantial reduction of solution TCO. In addition, CLOUDBASIX supports RDS to SQL Server on EC2 replication.
There is software and infrastructure costs associated with this solution. Please check the pricing page for details.
Summary
It is crucial to implement and test disaster recovery for your SQL databases. While it is not possible to cater to every type of disaster, Amazon RDS for SQL Server simplifies and automates the implementation of many disaster recovery options.
The following table summarizes the RPO and RTO metrics that you can attain with DR technologies for SQL Server on RDS:
| DR Technology | RPO | RTO | Automatic Failover | Readable Secondaries | Failback | Ease of Access | Endpoint Change in Failover** | Resource |
| Native backups | Hours | Hours/Days | No (Restore on target SQL Server) | No | Reconfigure | Available in all SQL editions | Yes | Database level |
| RDS Automated backups | Minutes | Minutes/Hours | No | No | No | Available in all SQL editions | Yes | Instance level |
| Manual Snapshot | Hours | Minutes/Hours | No | No | No | Available in all SQL editions | Yes | Instance level |
| Cross region PITR | Minutes | Minutes/Hours | No | No | No | Available in all SQL editions | Yes | Instance level |
| RDS for SQL Server Read replicas | Minutes | Minutes | No | Yes | Simplified* | Enterprise edition | Yes | Database level |
| AWS DMS | Seconds/Minutes | Minutes | No | Yes | Reconfigure | All SQL Editions | Yes | Table level |
| CLOUDBASIX for RDS SQL Server Read Replicas and Disaster Recovery (DR) | Seconds/Minutes | Minutes | Yes | Yes | Simplified* | All SQL Editions | Yes | RDS / Database / Table level |
*Operation does not require additional configuration or setup
**Application reconfiguration is required to connect to the database after failover
***Not guaranteed by vendor
+Crash recovery times not included—typically a few milliseconds to a few minutes depending on workloads
Conclusion
In this series, we showed you DR strategies for Amazon RDS for SQL Server. In part 1 we discussed SQL Server native backup/restore capability in Amazon RDS for SQL Server, as well as RDS automated and manual backups to support DR. We also discussed SQL versions and editions to implement the DR capabilities for in-region and multi-region deployments. In part 2 (this post), we talk through RDS Multi-AZ Read replicas, AWS DMS, and CLOUDBASIX technologies for DR for Amazon RDS for SQL Server.
If you have any questions, comments, or suggestions, please leave a comment below.
About the Authors
 Ganapathi Varma Chekuri is a Database Specialist Solutions Architect at AWS. Ganapathi works with AWS customers providing technical assistance and designing customer solutions on database projects, helping them to migrate and modernize their existing databases to AWS cloud.
Ganapathi Varma Chekuri is a Database Specialist Solutions Architect at AWS. Ganapathi works with AWS customers providing technical assistance and designing customer solutions on database projects, helping them to migrate and modernize their existing databases to AWS cloud.
 Baris Furtinalar is a Senior Solutions Architect who is part of specialists in Microsoft architectures team at AWS. He is passionate about cloud computing and he believes this shift to the cloud helps companies transform their businesses, gain agility, and improve operational responsiveness. He comes from a diverse background including SQL database administration, virtualization and system security. He designed, implemented and supported Windows/SQL server deployments since 2000.
Baris Furtinalar is a Senior Solutions Architect who is part of specialists in Microsoft architectures team at AWS. He is passionate about cloud computing and he believes this shift to the cloud helps companies transform their businesses, gain agility, and improve operational responsiveness. He comes from a diverse background including SQL database administration, virtualization and system security. He designed, implemented and supported Windows/SQL server deployments since 2000.