AWS Database Blog
Architect a Managed Disaster Recovery on Amazon RDS for SQL Server: Part 1
The initial challenge that database administrators (DBA) encounter when planning disaster recovery (DR) for SQL Server is choosing from the many options available. The challenge does not stop there as DBAs must implement the selected technology and ensure that best practices are applied.
Amazon Relational Database Service (Amazon RDS) is a managed service that makes it easy to set up, operate, and scale a relational database. Amazon RDS also offers high availability using a Multi-AZ solution, replicating data synchronously across different Availability Zones. In Multi-AZ RDS deployments, the service provides increased availability, data durability, and fault tolerance for DB instances. Amazon RDS lets you create database instances, database snapshots, point-in-time restores, and automated or manual backups for data protection and disaster recovery purposes.
In our last series of posts (Part 1, Part 2, Part 3, and Part 4) , we discussed disaster recovery (DR) terminology and compared the DR solutions available for SQL Server on Amazon Elastic Compute Cloud (Amazon EC2). In this series, we cover the DR solutions available for Amazon RDS for SQL Server.
Disaster Recovery strategies for Amazon RDS for SQL Server
In a DR plan, there is a DR site, also known as a backup site. This is a place that a company can temporarily use following a disaster. Distance is an essential consideration for an organization’s DR site. A nearby DR site allows for synchronous replication of data, while a DR site that is located far away can cause latency issues and may only support asynchronous replication. In either case, the best practice is to have a DR site on a separate power grid than the primary data center, and far enough away that a major disaster does not impact both the primary and DR site.
Organizations must make location decisions based on the types of possible disasters and costs. AWS global infrastructure simplifies this decision because AWS Availability Zones (AZ) are isolated from every other AZ. They are positioned in separate power grids, on different flood plains, and far apart from each other. Customers can achieve DR within an AWS region with Multi-AZ architectures. We refer to this approach as in-region DR throughout this post. Customers who need longer distances than that provided by a Multi-AZ approach can also leverage another AWS region for DR. We refer to this approach as multi-region DR. In this post we investigate in-region and multi-region DR capabilities on Amazon RDS for SQL Server. Amazon RDS for SQL Server version and edition requirements as per DR technology
The following table summarizes DR solutions by Amazon RDS for SQL Server version. And we will explore these options in this blog series.
| Solution | SQL 2012 | SQL 2014 | SQL2016 | SQL2017 | SQL2019 |
| SQL Server Native Backup and Restore | Yes | Yes | Yes | Yes | Yes |
| Amazon RDS Automated Snapshots/Backups | Yes | Yes | Yes | Yes | Yes |
| Amazon RDS Manual Snapshots/Backups | Yes | Yes | Yes | Yes | Yes |
| Replicating automated backups to another AWS Region | Yes | Yes | Yes | Yes | Yes |
| Amazon RDS SQL Server read replicas | No | No | Yes (15 replicas) | Yes (15 replicas) | Yes (15 replicas) |
| AWS Database Migration Service | Yes | Yes | Yes | Yes | Yes |
| CLOUDBASIX for RDS SQL Server Read Replicas and Disaster Recovery (DR) | Yes | Yes | Yes | Yes | Yes |
The following table summarizes DR solutions by Amazon RDS for SQL Server edition:
| Solution | Enterprise Edition | Standard Edition | Web Edition |
| SQL Server Native Backup and Restore | Yes | Yes | Yes |
| Amazon RDS Automated Snapshots/Backups | Yes | Yes | Yes |
| Amazon RDS Manual Snapshots/Backups | Yes | Yes | Yes |
| Replicating automated backups to another AWS Region | Yes | Yes | No |
| RDS SQL Server read replicas | Yes (15 replicas) | No | No |
| AWS Database Migration Service | Yes | Yes | Yes (full load only) |
| CLOUDBASIX for RDS SQL Server Read Replicas and Disaster Recovery (DR) | Yes | Yes | Yes |
In part 1 (this post) we explore SQL Server native backup/restore capability in RDS, Amazon RDS Automated and Manual Backups, and cross region replication of RDS backups. In part 2 we dive into Amazon RDS Read Replicas, AWS Database Migration Service and CLOUDBASIX for RDS SQL Server Read Replicas and Disaster Recovery.
Native backup and restore in RDS for SQL Server
Amazon RDS for SQL Server supports native backup and restore for Microsoft SQL Server databases. It lets you backup individual databases from an SQL Server RDS instance. The native backup and restore functionality is supported with the help of stored procedures. These stored procedures let you create a differential or full backup of your Amazon RDS for SQL Server DB instances, and store backup files on Amazon Simple Storage Service (Amazon S3). You can restore full, differential and log backups to an existing Amazon RDS DB or you can restore full and differential backups created from Amazon RDS. Amazon RDS for SQL Server also supports access to transaction log backups. With this feature, customers gain access to transaction log backups that are generated on the Amazon RDS SQL Server instance and copied to a customer S3 bucket. These files alongside with full and differential backups, can be used to restore databases to an on-premises instance that is running SQL Server. You can store and transfer backup files on Amazon S3 in the same AWS region (in-region DR), or you can replicate the backup files to another S3 bucket in another AWS region (multi-region DR).
Recovery Point Objective and Recovery Time Objective
If you’re using backups for your choice of DR for SQL server, then the maximum duration of the recovery process, and therefore the downtime, is the Recovery Time Objective (RTO). RTO depends on multiple factors, such as network throughput, which dictates how much time is required to transfer backup files over the network, as well as the size and number of backup files. Your recovery objectives also depend on if your source SQL database is on Amazon RDS or not. Amazon RDS for SQL Server lets you restore full, differential, and transaction log backups to a database instance, whereas it only allows the creation of full and differential backups from Amazon RDS.
Native backup and restore options in RDS for SQL Server:
| . | SQL Server Full Backup | SQL Server Full Restore | SQL Server Differential Backup | SQL Server Differential Restore | SQL Server Log Backup | SQL Server Log Restore |
| Amazon RDS SQL Server Single-AZ | Yes | Yes | Yes | Yes | No* | Yes |
| Amazon RDS SQL Server Multi-AZ | Yes | Yes | Yes | No | No* | No |
* You can list and copy available transaction log backups from RDS for SQL Server to a target Amazon S3 bucket.
Best practices
If you choose to work with this solution, you should consider the following:
- Write/read backup files up to 10 files – Writing to multiple files can improve backup/restore throughput, since files are written in parallel. This is useful if your backups are taking too long and you would like/need them to complete faster.
- Compress backup files – Because a compressed backup is smaller than an uncompressed backup of the same data, compressing a backup typically requires less device I/O and therefore usually increases backup speed significantly. Compressing backup files supported in Microsoft SQL Server Enterprise Edition and Standard Edition for RDS.
- Use AWS Key Management Service (AWS KMS) to encrypt your backup files internally, and at the S3 object layer. KMS simplifies the creation and management of cryptographic keys and control their use across a wide range of AWS services.
- You can use Amazon S3 Lifecycle policies so that backups are stored cost effectively throughout their lifecycle.
Solution overview

Figure 1 – Multi-Region DR with Amazon RDS
In this scenario, you have a source Amazon RDS for SQL Server instance in AWS Region A. You can create full and then differential backup files and store them on your Amazon S3 bucket in the same region. In case of a disaster, you can restore full and differential backups in the same region to a new Amazon RDS for SQL Server instance instance.
If your organization requires multi-region DR, you can copy the backup files to another Amazon S3 bucket in another AWS region. You can enable the built in replication feature of Amazon S3to transfer backup files to another AWS region automatically. Replication enables the automatic, asynchronous copying of objects across Amazon S3 buckets.
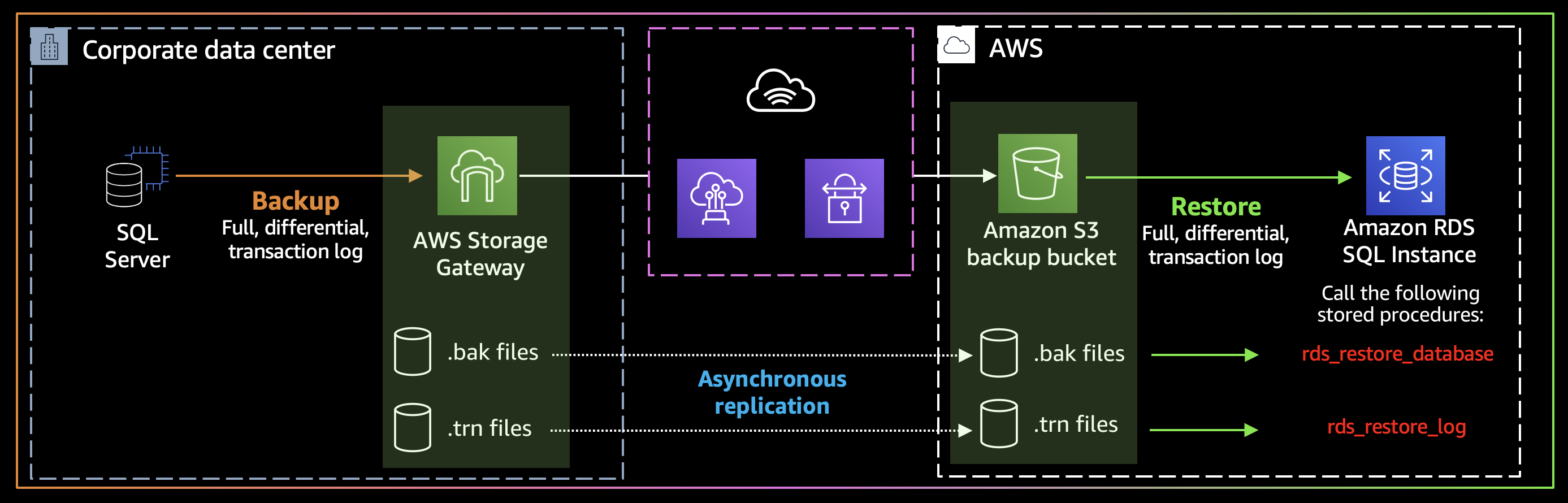
Figure 2 Corporate data center to Amazon RDS with AWS Storage Gateway
In the second scenario, you have your SQL Server database on your data center, and you decided to use AWS as your DR site. You can transfer full, differential, and transaction log backups to your Amazon S3 bucket. To simplify the process, consider using AWS Storage Gateway. Storage Gateway is a hybrid storage appliance that you deploy on your network. Storage Gateway exposes a file share on your network, which you may use as the target for SQL Server backups. Backup files on Storage Gateway are seamlessly uploaded over the VPN or AWS Direct Connect to your S3 bucket. From this bucket, full, differential, and transaction log backups can be restored to your Amazon RDS for SQL Server Instance. Based on your RTO requirements, you may choose to keep an Amazon RDS for SQL Server instance running in AWS. If your RTO allows longer periods of downtime, then you can launch your Amazon RDS for SQL Server instance when a disaster occurs. When the Amazon RDS for SQL Server Instance deployment is complete, you can start the restore process.
Failover and failback
In this scenario, failover after a disaster is the restoration of backup files to a new Amazon RDS for SQL Server instance. If your choice is multi-region DR, then the process also involves the time to transfer the backup files between AWS regions. A failback returns production to the original or new primary location after a disaster is resolved.
For failback, you must create, transfer, and restore the SQL database backup files to your original AWS region. While in-region DR may not require a failback, multi-region DR for Amazon RDS for SQL Server requires you to restore database(s) from full and differential backup files transferred from the other AWS region.
If you failover from your datacenter to Amazon RDS for SQL Server instance on AWS, then you can restore the last full backup, the last differential backup, and all transaction log backups to your Amazon RDS for SQL Server instance. After recovering your datacenter from the disaster, you can create full and differential backups of your Amazon RDS for SQL Server instance instance and transfer these backup files to your datacenter for recovery.
Benefits
This solution has the following benefits:
- Backup/Restore is simple and easy to implement DR technology.
- Replicate backup files to one or more destination buckets with S3 replication into the same or different AWS Regions for DR.
- Store backup files across a range of various S3 Storage Classes to optimize DR related costs.
- Work well with consolidation, since databases to instances are often not 1:1.
- You can leverage AWS KMS to encrypt internally, and at the S3 object layer.
Relative cost
Amazon S3 offers pay-as-you-go pricing and unlimited capacity. You can reduce your backup storage costs by optimizing S3 storage classes. S3 Lifecycle policy and S3 Intelligent-Tiering allows your data to transfer automatically to a different storage class without any changes to your application, and you can save on backup storage costs.
RDS automated and manual snapshots/backups for DR
Amazon RDS creates and saves automated backups of your database instance during the backup window that you chose. RDS creates a storage volume snapshot of your SQL Server instance during this slot. Backups are stored on Amazon S3 in the same AWS region as the Amazon RDS for SQL Server Instance. For multi-region DR of your Amazon RDS for SQL Server Instance, which we discuss later in this post, you can enable the replication of automated backups to another AWS Region.
The first snapshot of a database instance contains the data for the full DB instance. Subsequent snapshots are incremental. This means that only the data that has changed after your most recent snapshot is stored. RDS saves the automated backups of your database instance according to the backup retention period that you specify.
You can also create a manual database snapshot at anytime. Unlike automated backups, manual snapshots aren’t subject to the backup retention period, and they don’t expire.
RPO and RTO
You can restore a database instance to a specific point in time. This feature is called point-in-time recovery. RDS uploads the transaction logs for DB instances to Amazon S3 every five minutes. So the RPO you should expect is five minutes. The RTO value would be the time to restore a DB instance to that point in time. This time objective includes the time it takes to launch a new Amazon RDS for SQL Server instance.
If you choose to work with this method, you should consider the following:
- Use AWS Backup to manage backups of Amazon RDS DB instances.
- There is a manual snapshot limit (100 snapshots per region) that does not apply to automated backups. Manual snapshots are not automatically deleted. Therefore, you should implement a solution to clean these explicitly.
- Test your backups regularly by performing test restores.
Solution overview
The following diagram illustrates the architecture of this solution. Amazon RDS creates and saves automated backups of your DB instance during the backup window in the same region.
In case of a disaster, you can create a new database instance by restoring the DB instance from your latest snapshot. When you restore a DB instance, a new DB instance is created.

Figure 3 Amazon RDS automated backups in the same region.
Replicating Automated Backups to another AWS Region (Multi-Region DR)
You can configure your Amazon RDS for SQL server instance to replicate snapshots and transaction logs to another AWS Region. You can enable Amazon RDS backup replication on new or existing DB instances.
Although a DB instance-level backup runs daily during your preferred backup window, transaction log backups are initiated every five minutes. In a multi-region DR use case for RDS, both the daily volume snapshots and transaction logs are sent to another AWS region. The copy operation incurs some time. This additional time increases the RTO in a multi-AZ DR scenario. The size of the backup and the distance between regions are important factors that affect this additional time required.

Figure 4 Replicating Amazon RDS Automated Backups to another AWS Region
Failover and failback
In case of disaster, you can failover your RDS database instance after successful completion of the restore operation. The failover of your RDS database instance is a manual process. Both the in-region and multi-region DR setups require you to create a new RDS database instance before the restoration begins. After your RDS database instance is successfully setup, the restore operation takes place and failover completes. The failback process is the same, and you have to transfer and restore the RDS database backups to your primary region after a disaster.
Benefits
This solution has the following benefits:
- Database instance snapshots are incremental after the first full snapshot.
- You can use manual snapshots for long term retention.
- You can copy snapshots across AWS accounts/regions.
- You can restore in different AWS accounts/regions.
Relative cost
In-region DR only incurs storage costs. When you replicate the automated backups to another AWS region, data transfer charges apply. After the DB snapshot is copied, standard charges also apply to storage in the destination region.
Cross-region automated backups are cost-effective and help save on compute and licensing costs. You don’t have to run live RDS DB instances until you must initiate DR. This significantly reduces management overhead, thereby enabling database administrators to focus on other tasks, in addition to making sure of compliance and data integrity with a low RPO.
Summary
The choice of DR solution depends on your requirements and budget, as well as your version and edition of RDS for SQL Server database engine.
In this post, we discussed SQL Server native backup/restore capability in Amazon RDS for SQL Server, as well as RDS automated and manual backups to support DR. We also discussed SQL versions and editions to implement the DR capabilities for in-region and multi-region with AWS. In our next post, we talk through RDS Multi-AZ Read replicas, AWS DMS, and CLOUDBASIX technologies for DR use cases.
About the Authors
 Ganapathi Varma Chekuri is a Database Specialist Solutions Architect at AWS. Ganapathi works with AWS customers providing technical assistance and designing customer solutions on database projects, helping them to migrate and modernize their existing databases to AWS cloud.
Ganapathi Varma Chekuri is a Database Specialist Solutions Architect at AWS. Ganapathi works with AWS customers providing technical assistance and designing customer solutions on database projects, helping them to migrate and modernize their existing databases to AWS cloud.
 Baris Furtinalar is a Senior Solutions Architect who is part of specialists in Microsoft architectures team at AWS. He is passionate about cloud computing and he believes this shift to the cloud helps companies transform their businesses, gain agility, and improve operational responsiveness. He comes from a diverse background including SQL database administration, virtualization and system security. He designed, implemented and supported Windows/SQL server deployments since 2000.
Baris Furtinalar is a Senior Solutions Architect who is part of specialists in Microsoft architectures team at AWS. He is passionate about cloud computing and he believes this shift to the cloud helps companies transform their businesses, gain agility, and improve operational responsiveness. He comes from a diverse background including SQL database administration, virtualization and system security. He designed, implemented and supported Windows/SQL server deployments since 2000.