AWS Database Blog
Architect a disaster recovery for SQL Server on AWS: Part 2
In this series of posts (Part 1, Part 2, Part 3 and Part 4), we compare and contrast the disaster recovery (DR) solutions available for Microsoft SQL Server on Amazon Elastic Compute Cloud (Amazon EC2). This post introduces three methods for implementing DR for SQL Server on AWS: SQL Server backup and restore, SQL Server log shipping, and SQL Server database mirroring.
SQL Server Backup and restore
Even when you have some kind of high availability (HA) and DR technology in place, you still need to have backups in case this technology fails, such as accidental deletion of data or data corruption. Backups are the baseline for any DR strategy. Backup strategy depends on the recovery model of the SQL Server database. A recovery model is a database property that controls how transactions are logged, whether the transaction log requires (and allows) backing up, and what kinds of restore operations are available.
Depending on the recovery model of the database, you can take three types of backups within SQL Server:
- Full backup – Backs up the whole database, all extents from all data files, and backs up the transaction logs required in order to recover the database after a restore operation. This backup is supported in all recovery models.
- Differential backup – Backs up the extents modified since the last full backup. Like full backups, this method is supported in all recovery models.
- Log backup – Backs up the active portion of the transaction log. Transaction log backups are especially important on databases that support OLTP (online transaction processing), because they allow a point-in-time recovery (PITR) to the point immediately before the disaster occurred.
RTO and RPO
If you’re using backups for your choice of DR for SQL server, the maximum duration of the recovery process and therefore the downtime is the Recovery Time Objective (RTO). RTO depends on multiple factors, such as network throughput, which dictates how much time is required to transfer backup files over the network, as well as the size and the number of backup files. In a recovery scenario for a database that has multiple differential and log backups, as a first step of recovery you should restore the last full backup, most recent differential backup, and all log backups taken afterward. Broadly speaking, your Recovery Point Objective (RPO) dictates the log backup intervals. You should also consider log backup duration when designing your backup strategies for DR.
Best practices
You can consider using Amazon Simple Storage Service (Amazon S3) as storage for backups. Amazon S3 provides highly durable object storage and supports built-in replication capabilities in and across Regions. With the tiered storage option, Amazon S3 also provides cost-effective storage for infrequently accessed data such as backups. We also recommend setting up a gateway VPC endpoint for Amazon S3. A VPC endpoint enables private connections between your VPC and supported AWS services and VPC endpoint services powered by AWS PrivateLink.
Another backup storage option for SQL server is Amazon FSx. FSx for Windows File Server and FSx for NetApp ONTAP provides fully managed SMB file servers for storing backup files. In the event of a hardware or operating system error, if your data is on a local drive on that inaccessible SQL Server, it takes much longer to perform a restore. Instead, if the backups are on a network share, you can immediately start restoring those backups onto another server.
If you use AWS as a DR site, you can consider using AWS Storage Gateway as your backup storage on your data center to transmit backup files to an S3 bucket on AWS.
You can also use AWS SQLServer-Backup Automation document to automate the process.
Solution overview
The following diagram illustrates the architecture of a backup and restore solution.

Figure: Backup and Restore
In this scenario, you configure your SQL Server database on an EC2 instance, and transfer full, differential, and transaction log backups between your on-premises database and SQL Server in the AWS Cloud. To speed up the backup and restore process, you can consider using Storage Gateway. Storage Gateway is a hybrid storage appliance that you deploy on your network. Storage Gateway exposes a file share on your network, which you may use as the target for SQL Server backups. To speed up backup operations, Storage Gateway contains a configurable local cache. The best practice is to set up this cache large enough to store the whole backup. Cached backups are seamlessly uploaded over the VPN or Direct Connect to an S3 bucket on AWS.
From this bucket, the full, differential, or transaction log backups can be downloaded to a file system and then restored to SQL Server on EC2. Therefore, you can keep your on-premises and cloud databases in sync until you’re ready to do the cutover to AWS.
Failover and failback
In case of disaster, you can fail over your SQL database after you successfully complete the restore operation (RTO). This is manual process. You can use this as one of the possible strategies of disaster recovery.
Backups don’t provide failback automatically. You have to manually restore the database backups to bring the databases to consistent state.
Benefits
The backup and restore solution has the following benefits:
- It’s simple and easy to implement DR technology
- All backup types are supported in all SQL Server editions
- Backup files can be copied to between AWS Regions
Relative cost
With AWS Storage Gateway for your SQL Server backups, you can simplify your backup operations and reduce your storage costs by moving your backup files to Amazon S3. Full, differential, and transaction log backups are supported in all SQL Server editions.
SQL Server Log shipping
Log shipping is a technology that you can use to implement disaster recovery. You can use log shipping to send transaction log backups from your primary, on-premises SQL Server database to one or more secondary (warm standby) SQL Server databases that are deployed on EC2 instances or Amazon RDS for SQL Server DB instances in the AWS Cloud. You need to set up log shipping for each individual database. To set up log shipping on Amazon RDS for SQL Server, you have to use your own custom scripts.
RPO and RTO
Transaction log shipping is often used as a disaster recovery solution but also can be used as a high availability solution when you have flexible RTO and RPO requirements, because the difference in state between a primary database and its secondary database is significantly larger. The replica lag is larger because transaction log files are sent asynchronously and have to be applied in their entirety to a secondary database. Log shipping provides an RPO of minutes and an RTO of minutes to hours. Log shipping is more appropriate in DR scenarios in which you require a load delay, because that isn’t possible with mirroring or Always On availability groups.
Best practices
Keep in mind the following best practices:
- Never change database recovery model to simple or bulk logged and change it back to full recovery. Doing so breaks the transaction log chain to stop log shipping from running.
- You can take no other transaction log backups than those used for log shipping. Doing so breaks the log shipping chain.
- If you’re setting up restoration frequently (for example, every 15 mins), all the existing connections have to be stopped every 15 mins before restoration. Choose log shipping when you want to read from the secondary database, but you don’t require readability during a restore operation.
Solution overview
The following diagram illustrates the architecture of a hybrid log shipping solution.

Figure: Log shipping
In this scenario, you configure a warm standby SQL Server database on an EC2 instance and send transaction log backups asynchronously between your on-premises database and the warm standby server in the AWS Cloud. The transaction log backups are then applied to the warm standby database. When all the logs have been applied, you can perform a manual failover and cut over to the cloud.
If you want to configure in-Region DR for a primary database running on AWS, we recommend running the primary and secondary DB instances in separate Availability Zones, and optionally you can configure a monitor instance to track all the details of log shipping. Also, if you want to configure multi-Region DR with in AWS, you can set up log shipping between the instances running in two different Regions.
Failover and failback
A log shipping configuration doesn’t provide automatic failover from the primary server to the secondary server. If the primary database becomes unavailable, any of the secondary databases can be brought online manually. Failover must be manually initiated on the secondary server. It requires an amount of administrative effort. There is not a monitor agent that coordinates the failover. You essentially decide when to bring the databases online on the secondary server.
After the failover, your production databases are no longer in sync with the DR databases. You can’t just fail your databases back, so log shipping has to be reconfigured. You have to take a full and log backup from the DR databases and restore them over to your production databases.
Benefits
Log shipping has the following benefits:
- Easy to set up and manage
- Relatively inexpensive solution
- Delayed recovery- Ability to recover from a previous point in time
- Doesn’t require Active Directory and Windows Server failover clustering
- Multiple secondaries can be configured
- Standby databases can be available for read-only queries
- Can be combined with other HA and DR technologies
- Supported in all SQL editions except Express edition
Relative cost
Log shipping requires SQL Server Web edition and up. Setting up and operation is relatively straightforward but incurs administrative overhead. Additionally, after a disaster, the change of endpoint increases the complexity of operations. Failback requires reconfiguration of the log shipping in reverse direction from scratch.
SQL Server Database mirroring
Database mirroring works by sending a stream of log records from the primary to secondary servers. In database mirroring, these servers are called the principal and the mirror. All data modifications must be done on the primary server. With database mirroring, the database on the mirror server is in restoring mode and inaccessible to the clients. Database mirroring is deprecated in latest version of SQL Server.
The technology can work in either synchronous or asynchronous modes, which are also called synchronous and asynchronous commits. Synchronous database mirroring is available in two different modes: high protection and high availability. The only difference between these two modes is automatic failover support. SQL Server supports automatic failover in high availability mode; however, it requires you to have a third SQL Server instance, called a witness, which helps support quorum in the configuration.
You can use database mirroring to set up a hybrid cloud environment for your SQL Server databases. This option requires SQL Server Enterprise edition. In this scenario, your principal SQL Server database runs on premises, and you create a warm standby in the cloud. You replicate your data asynchronously, and perform a manual failover when you’re ready for cutover. After you have migrated the database to the AWS Cloud, you can add a secondary replica by using an Always On availability group for high availability and resiliency purposes.
RPO and RTO
Replication is asynchronous. The RPO depends on lag and network bandwidth between the principal and mirror database.
The lag can become large if the principal or mirror servers are under a heavy load. RTO depends on the time taken to force the service, which uses the mirror server as a warm standby server. Database mirroring provides an RPO and RTO of minutes.
Best practices
With database mirroring, running write-heavy workloads may see a performance impact, because data changes have to be confirmed both by the principal and secondary nodes. Furthermore, mirroring may result in a higher I/O load on the secondary for write-heavy workloads, or burst of such loads, such as index rebuilds. So you need to plan storage performance accordingly.
You should have a dedicated network between the servers that are involved in database mirroring. If the servers share a common network with other servers, the effective bandwidth that is available for mirroring communication impacts performance. We highly recommend that you configure database mirroring in a high-bandwidth network. The network bandwidth is dictated by the log generation rate of your application. Lower bandwidth networks can adversely impact the performance of database mirroring.
If you have multiple databases in an instance, you need to mirror each database individually. Although it’s possible to choose a different mirror server for each database, it’s a best practice to choose one mirror server for all the databases that belong to one application. If the databases in an instance belong to different applications, you can choose different mirror servers for them, but doing so adds complexity to the configuration.
Solution overview
The following diagram illustrates the architecture for hybrid database mirroring.
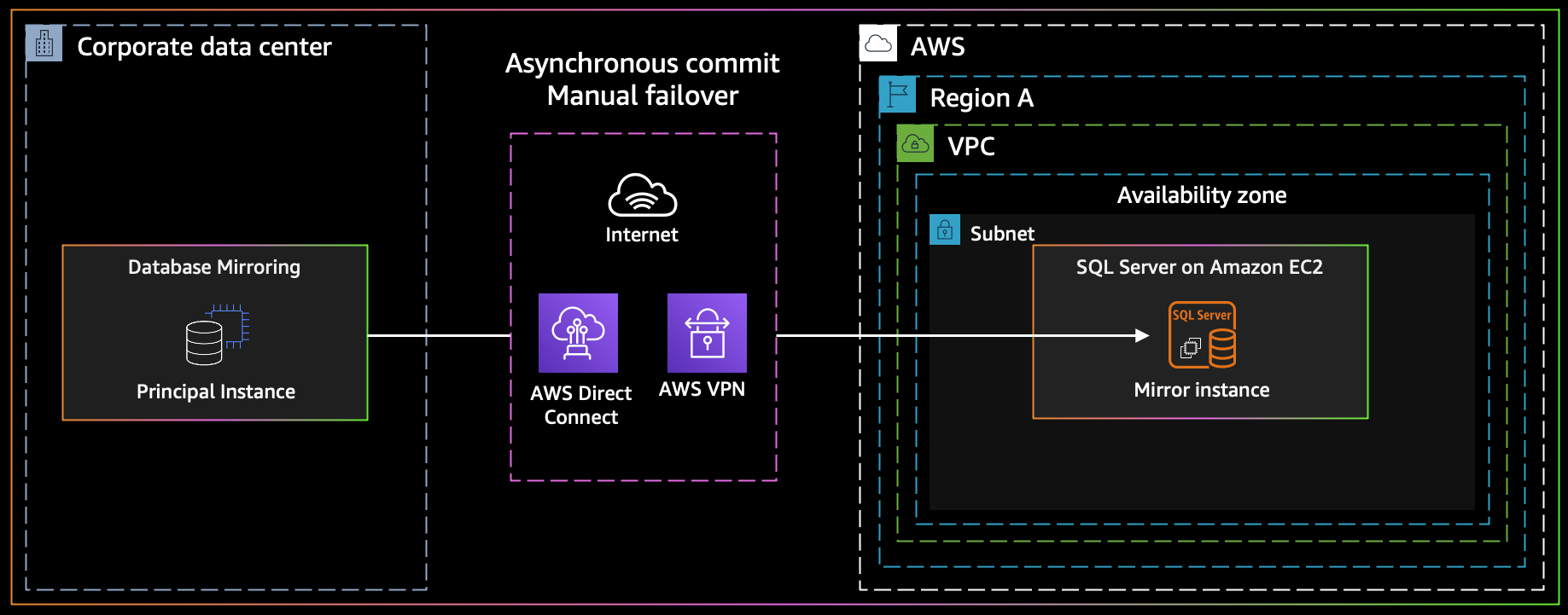
Figure: Database Mirroring
In this scenario, you configure asynchronous database mirroring between your SQL Server database on an EC2 instance and your on-premises database. The principal database sends the log for a transaction asynchronously to a mirror database in the AWS Cloud. The principal server sends a confirmation to the client, without waiting for an acknowledgement from the mirror server. Transactions commit without waiting for the mirror server to write the log to disk.
Failover and failback
If you’re using synchronous mirroring with a witness, the automatic failover takes place, thereby minimizing the database downtime. The mirror becomes the principal database and the old principal assumes the role of the mirror.
If you’re using synchronous mirroring without a witness, this option doesn’t provide automatic failover. We need to manually run the failover and bring the mirror database as new principal database.
If you’re using asynchronous mirroring, this option doesn’t provide automatic failover. If there are any transactions that didn’t make it to the mirror at the time of failure of the principal, these transactions are lost. We need to manually run the force failover by acknowledging the possibility of data loss.
When the database on the primary side becomes operational, it automatically assumes the role of the mirror. However, the mirroring session remains suspended and you need to manually resume the mirroring session.
Benefits
Database mirroring has the following benefits:
- Supports automatic database failover mechanism (with witness server)
- Configuring the database mirroring solution doesn’t require a Windows failover cluster
Relative cost
SQL database mirroring requires SQL Server Standard edition or Enterprise edition to run. Although this technology has been declared as deprecated by vendor, it’s still widely used.
Summary
In this post, we discussed SQL Server backup and restore, SQL Server log shipping, and SQL Server database mirroring technologies to implement DR on AWS. In our next post, we talk through SQL Server failover clustering; SQL Server Always On availability groups; distributed availability groups; and combining multiple DR technologies topics for DR use cases on AWS.
View the Turkic translated version of this post here.
About the Author
 Ganapathi Varma Chekuri is a Database Specialist Solutions Architect at AWS. Ganapathi works with AWS customers providing technical assistance and designing customer solutions on database projects, helping them to migrate and modernize their existing databases to AWS cloud.
Ganapathi Varma Chekuri is a Database Specialist Solutions Architect at AWS. Ganapathi works with AWS customers providing technical assistance and designing customer solutions on database projects, helping them to migrate and modernize their existing databases to AWS cloud.
 Baris Furtinalar is a Senior Solutions Architect who is part of specialists in Microsoft architectures team at AWS. He is passionate about cloud computing and he believes this shift to the cloud helps companies transform their businesses, gain agility, and improve operational responsiveness. He comes from a diverse background including SQL database administration, virtualization and system security. He designed, implemented and supported Windows/SQL server deployments since 2000.
Baris Furtinalar is a Senior Solutions Architect who is part of specialists in Microsoft architectures team at AWS. He is passionate about cloud computing and he believes this shift to the cloud helps companies transform their businesses, gain agility, and improve operational responsiveness. He comes from a diverse background including SQL database administration, virtualization and system security. He designed, implemented and supported Windows/SQL server deployments since 2000.