IBM & Red Hat on AWS
Building data integration with IBM Planning Analytics SaaS and AWS Lambda
Customers across different industries are looking for ways to use all of their data to enhance their planning and decision-making processes. They seek solutions to integrate data from various sources, aiming to build innovative AI solutions, gain a 360-degree view of their operations, and uncover new insights to differentiate their businesses.
IBM Planning Analytics (PA) is an advanced analytics solution that helps organizations automate planning, budgeting, forecasting, and analysis processes. Available as a fully managed SaaS on AWS, PA uses an in-memory database to produce real-time insights, with AI-infused forecasting.
In this blog, we will show you how you can streamline data workflows and enhance your data-driven decision making process by integrating PA with AWS data repositories such as Amazon Simple Storage Service (Amazon S3) and Amazon Relational Database Service (Amazon RDS). By utilizing open-source tools, serverless applications with an event-driven architecture, AWS Lambda, and Python libraries you can fetch, process, and prepare data for integration. This approach streamlines your workflows and enhances data-driven decision-making.
Solution overview
IBM Planning Analytics is powered by the TM1 OLAP Engine, providing a flexible, scalable platform designed for multidimensional data analysis and collaborative planning. It organizes data into multidimensional cubes, with dimensions representing different data categories. Users interact with these cubes to input, analyze, and manipulate data.
AWS Lambda is a serverless compute service that enables you to execute code in response to events, without managing servers. TM1py is an MIT licensed open-source Python package that wraps the TM1 REST APIs in a simple to use library.
In this blog, we’re exploring different scenarios to demonstrate how you can use AWS Lambda with TM1py to simplify the process of exchanging data between AWS repositories like Amazon S3 and Amazon RDS, and IBM Planning Analytics Cubes and Dimensions.
AWS Secrets Manager helps us secure our IBM Planning Analytics credentials. While Amazon API Gateway can be used to invoke our AWS Lambda functions to execute the data flows. In this blog, we’re invoking our REST APIs from Amazon API Gateway for a simple test. But, one possible scenario that can be created, is using IBM Planning Analytics TurboIntegrator (TI) jobs to invoke the AWS Lambda APIs to automate such flows.
The diagram below (figure 1) shows how you can use AWS Lambda to build these data integrations flows.
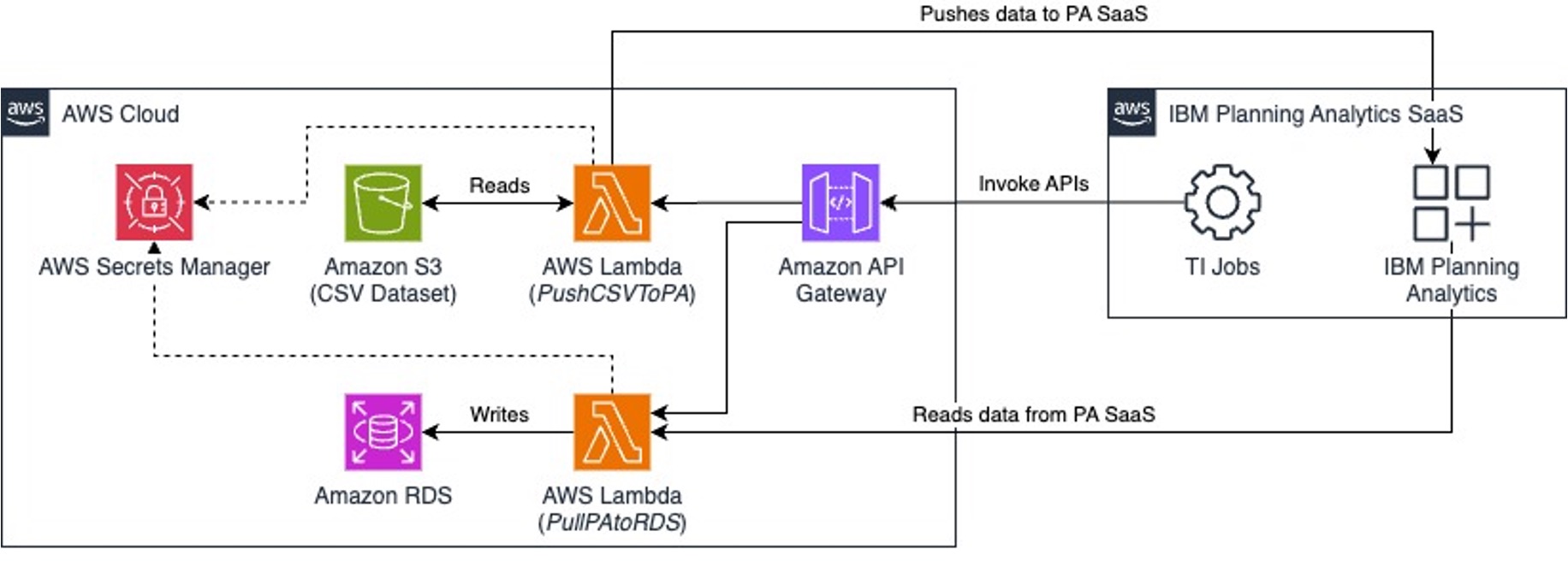
Figure 1. Loading and consuming data from IBM Planning Analytics SaaS using AWS Lambda with TM1py.
In the sections below, we’ll describe how you can create these AWS Lambda functions with TM1py, to push and pull data from IBM Planning Analytics.
Prerequisites
- Access to an AWS account, with permissions to create the resources described in the implementation steps section
- Access to an IBM Planning Analytics SaaS environment on AWS, with Modeler or Admin access
- This blog assumes familiarity with: AWS Lambda, AWS Lambda Layers, AWS CloudShell , Amazon S3, Amazon RDS for PostgreSQL, Amazon Virtual Private Cloud (Amazon VPC), Amazon API Gateway, AWS Secrets Manager, AWS Identity and Access Management (IAM), IBM Planning Analytics, Python and TM1Py
- Python v3.11 with the following libraries: tm1py, pandas, numpy, openpyxl, psycopg2-binary
Costs
You are responsible for the cost of the AWS services used when deploying the solution described in this blog, on your AWS account. For cost estimates, see the pricing pages for AWS Lambda, Amazon S3, Amazon RDS for PostgreSQL, Amazon API Gateway, AWS Secrets Manager and Amazon VPC and any other services that you choose to use as part of your implementation.
Implementation steps
Obtain your Planning Analytics API key
- Login to your IBM Planning Analytics SaaS on AWS.
- From the Welcome to Planning Analytics page, click on your user name on the top right corner to display the Personal menu. From it, click on Manage API Keys (figure 2).
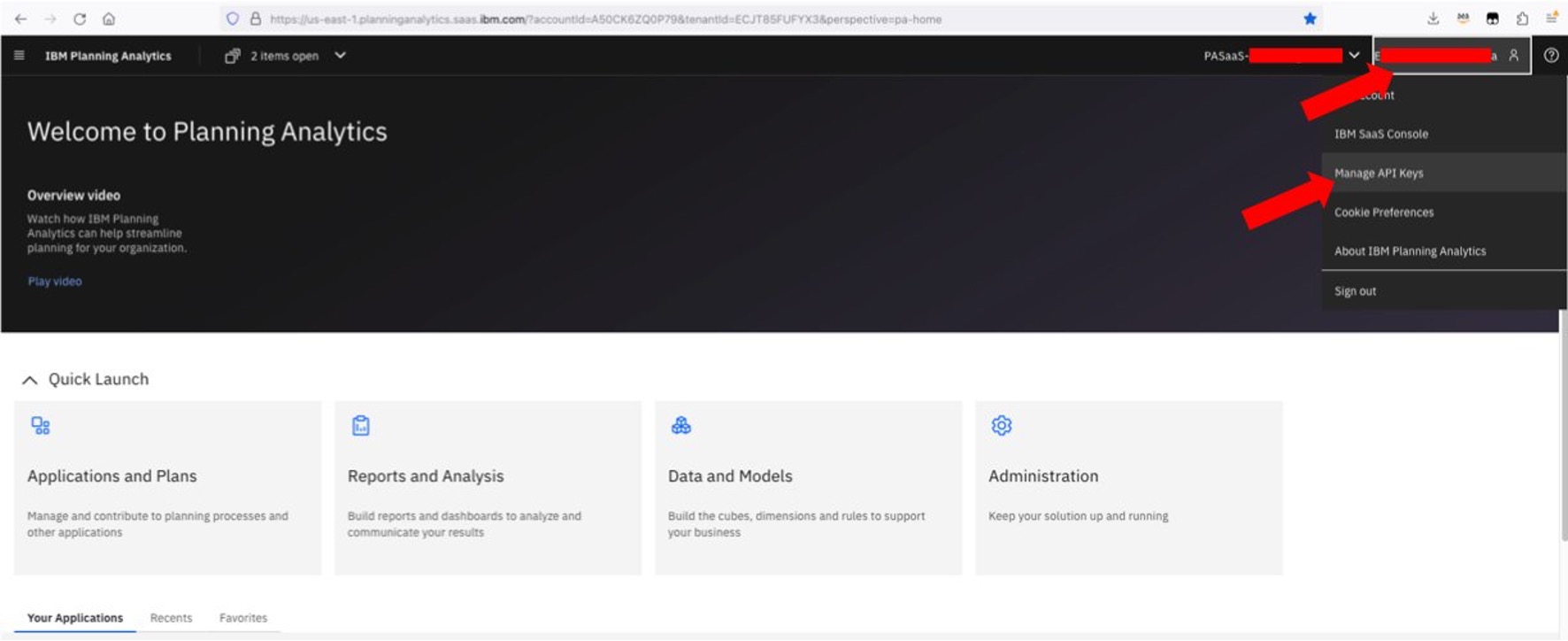
Figure 2. Navigate to Manage API Keys on the IBM Planning Analytics web interface.
- From the API Keys window, click Generate Key to display the Generate API Key Enter an API key name and click Generate key (figure 3).
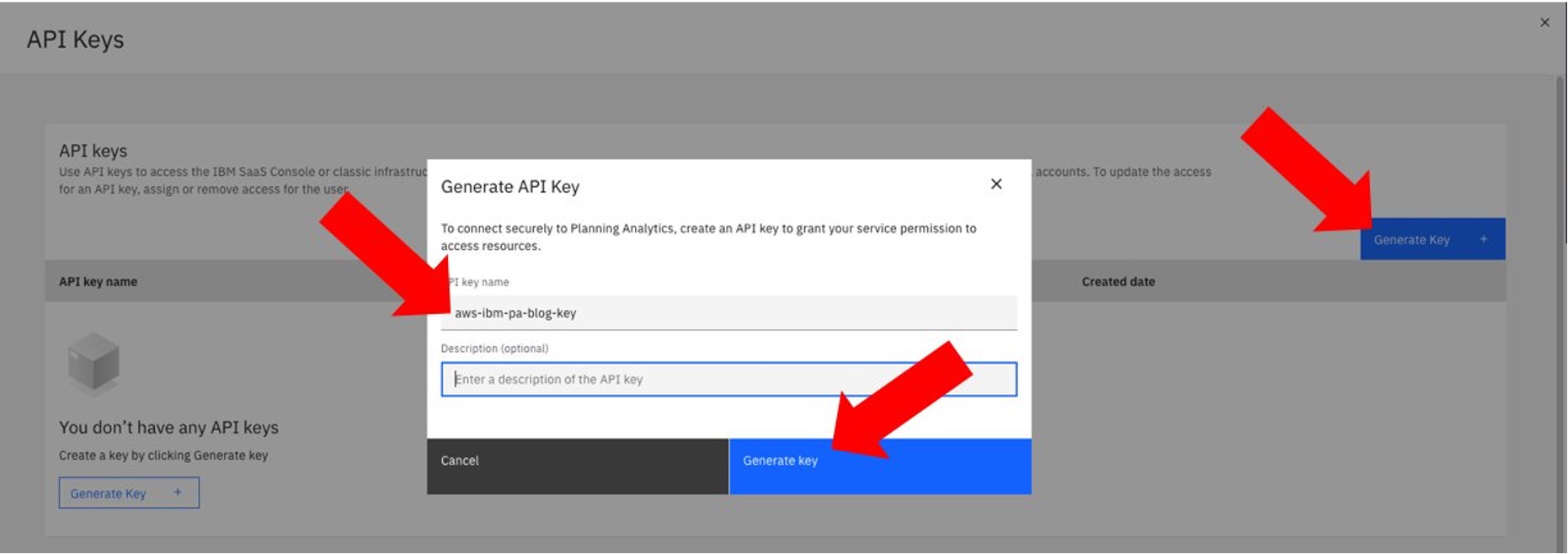
Figure 3. Generate and download an IBM Planning Analytics API key.
- Once the key has been generated, you will be provided with the options to copy its value, or download it as a JSON file.
- Take note of your PA API endpoint URL. Refer to the IBM Planning Analytics documentation to understand its format:
- Keep your newly create API key at hand, you will use it later to allow your AWS Lambda functions to connect to Planning Analytics.
Store your IBM Planning Analytics credentials in AWS Secrets Manager
- Login to the AWS Management console.
- Connect to AWS CloudShell and run the commands below to create an AWS Secrets Manager secret with your IBM Planning Analytics credentials generated on steps 3-to-5 above:
$ aws secretsmanager create-secret \
--name "ibm-pa-conn-secret" \
--description "Secret for IBM Planning Analytics API" \
--secret-string '{
"api_endpoint": "<<REPLACE_WITH_YOUR_API_ENDPOINT_URL>>",
"user": "<<REPLACE_WITH_YOUR_USERNAME>>",
"password": "<<REPLACE_WITH_YOUR_PASSWORD>>"
}‘Load data to Amazon S3
In this blog we’re using a sample dataset for coffee chain sales. This sample dataset is owned and maintained by IBM, for IBM Cognos Analytics
- Create an Amazon S3 bucket and 2 folders: to_ibm-pa-saas and python-libs.
- Download the sample IBM dataset using AWS CloudShell, and copy it to your Amazon S3 bucket:
$ wget https://public.dhe.ibm.com/software/data/sw-library/cognos/mobile/C11/data/Coffee_Chain_2020-2022.zip
$ unzip Coffee_Chain_2020-2022.zip
$ aws s3 cp Coffee_Chain_2020-2022.csv s3://${S3_BUCKET_NAME}/to_ibm-pa-saas/Create an Amazon RDS for PostgreSQL database
Create an Amazon RDS instance to import data from IBM Planning Analytics. For simplicity, our test environment is using a single Amazon RDS for PostgreSQL database instance in the Default VPC. Refer to the Infrastructure security in Amazon RDS when deploying Amazon RDS in your AWS accounts.
- Our Amazon RDS instance is created with the following settings:
- DB instance ID: ibm-pa-blog-rds
- Engine version: 2
- DB name: IBMPADB
- AWS Secrets Manager for our database Master Credentials
- Security Group with an inbound rule allowing access on port 5432 from our Amazon VPC CIDR range
You can follow the AWS Quick Start for Amazon RDS, or the AWS documentation to create a PostgreSQL DB instance.
Create AWS IAM Role and IAM Policy for AWS Lambda
For simplicity, we’re using the same IAM Role for all of our AWS Lambda functions. Follow the least-privilege principle when deploying Lambda functions in your AWS account. Refer to the Lambda execution role documentation to create specific roles for each Lambda function.
- Create an IAM policy named ibmpa-lambda-policy with the following permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<<YOUR_AMAZON_S3_BUCKET>>",
"arn:aws:s3:::<<YOUR_AMAZON_S3_BUCKET>>/*"
]
},
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
"arn:aws:secretsmanager:<<AWS_REGION>>:<<YOUR_AWS_ACCOUNT_ID>>:secret:<<IBM_PA_AWS_SECRET>>",
"arn:aws:secretsmanager:<<AWS_REGION>>:<<YOUR_AWS_ACCOUNT_ID>>:secret:<<AMAZON_RDS_SECRET>>"
]
},
{
"Effect": "Allow",
"Action": [
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface"
],
"Resource": [
"arn:aws:ec2:<<AWS_REGION>>:<<YOUR_AWS_ACCOUNT_ID>>:subnet/*",
"arn:aws:ec2:<<AWS_REGION>>:<<YOUR_AWS_ACCOUNT_ID>>:network-interface/*",
"arn:aws:ec2:<<AWS_REGION>>:<<YOUR_AWS_ACCOUNT_ID>>:security-group/*"
]
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeVpcs",
"ec2:DescribeSubnets",
"ec2:DescribeSecurityGroups"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup"
],
"Resource": [
"arn:aws:logs:*:<<YOUR_AWS_ACCOUNT_ID>>:log-group:*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:<<YOUR_AWS_ACCOUNT_ID>>:log-group:*:log-stream:*"
}
]
}
- Create an IAM role for AWS Lambda, assigning to it the ibmpa-lambda-policy policy created on the previous step. Name it ibmpa-lambda-role, and copy its ARN.
Create an AWS Lambda Layer with the required Python libraries
- Use AWS CloudShell and run the commands below to install Python 3.11:
$ sudo dnf install python3.11 -y
$ sudo dnf install python3.11-pip -y- Execute the commands below to create an AWS Lambda Layer for TM1py (figure 4):
$ pip3.11 install virtualenv
$ mkdir python
$ cd ~/python
$ python3.11 -m venv layer
$ source layer/bin/activate
$ pip3.11 install tm1py pandas numpy openpyxl psycopg2-binary --target .
$ deactivate
$ rm -fR *.dist-info
$ find . -type d -name "tests" -exec rm -rfv {} +
$ find . -type d -name "__pycache__" -exec rm -rfv {} +
$ rm -fR layer
$ cd ../
$ zip -r tm1py_layer.zip python
Figure 4. Create the TM1py zip package for AWS Lambda.
- Upload your TM1py AWS Lambda layer file to an Amazon S3 bucket:
$ aws s3 cp tm1py_layer.zip s3://${S3_BUCKET_NAME}/python-libs/- Execute the command below to create the TM1py layer for Python:
$ LAMBDA_LAYER_ARN=$(aws lambda publish-layer-version \
--layer-name TM1py_Layer \
--description "TM1py Python 3.11 Lambda Layer" \
--content S3Bucket=${S3_BUCKET_NAME},S3Key=python-libs/tm1py_layer.zip \
--compatible-runtimes python3.11 \
--query 'LayerVersionArn' \
--output text)Create the AWS Lambda functions
Push data from Amazon S3 into IBM Planning Analytics
The first case we’re testing is the data upload from a CSV file in Amazon S3 to IBM Planning Analytics. This is a proof of technology solution, not meant for a production environment.
- Using your preferred IDE, create a Python file with the code sample below and upload it to AWS CloudShell:
import os, boto3, logging, json, traceback, pandas as pd
from TM1py.Utils import Utils
from TM1py.Objects import Cube, Dimension, Hierarchy, Element
from TM1py.Services import TM1Service
from TM1py.Utils.Utils import build_cellset_from_pandas_dataframe
from datetime import timedelta, date
from io import StringIO
# Configure logger
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def daterange(start_date, end_date):
for n in range(int((end_date - start_date).days)):
yield start_date + timedelta(n)
def upload_to_tm1(df, secret):
base_url = secret.get('base_url', '')
user = secret.get('user', '')
password = secret.get('password', '')
params = {
"base_url": base_url,
"user": user,
"password": password
}
# Connect to TM1 server using secrets
with TM1Service(**params) as tm1:
try:
# Define the dimensions and hierarchies
start_date = date(2020, 1, 1)
end_date = date(2022, 12, 31)
elements = [Element(str(single_date), 'Numeric') for single_date in daterange(start_date, end_date)]
hierarchy = Hierarchy('Coffee Sales Date', 'Coffee Sales Date', elements)
dimension = Dimension('Coffee Sales Date', [hierarchy])
if not tm1.dimensions.exists(dimension.name):
tm1.dimensions.create(dimension)
products = list(df['Product'])
elements = [Element(product, 'String') for product in products]
hierarchy = Hierarchy('Coffee Sales Product', 'Coffee Sales Product', elements)
dimension = Dimension('Coffee Sales Product', [hierarchy])
if not tm1.dimensions.exists(dimension.name):
tm1.dimensions.create(dimension)
product_types = list(df['Product Type'])
elements = [Element(product_type, 'String') for product_type in product_types]
hierarchy = Hierarchy('Coffee Sales Product Type', 'Coffee Sales Product Type', elements)
dimension = Dimension('Coffee Sales Product Type', [hierarchy])
if not tm1.dimensions.exists(dimension.name):
tm1.dimensions.create(dimension)
states = list(df['State'])
elements = [Element(state, 'String') for state in states]
hierarchy = Hierarchy('Coffee Sales State', 'Coffee Sales State', elements)
dimension = Dimension('Coffee Sales State', [hierarchy])
if not tm1.dimensions.exists(dimension.name):
tm1.dimensions.create(dimension)
types = list(df['Type'])
elements = [Element(type, 'String') for type in types]
hierarchy = Hierarchy('Coffee Sales Type', 'Coffee Sales Type', elements)
dimension = Dimension('Coffee Sales Type', [hierarchy])
if not tm1.dimensions.exists(dimension.name):
tm1.dimensions.create(dimension)
measures = ('Sales','Profit')
elements = [Element(measure, 'Numeric') for measure in measures]
hierarchy = Hierarchy('Coffee Sales Measure', 'Coffee Sales Measure', elements)
dimension = Dimension('Coffee Sales Measure', [hierarchy])
if not tm1.dimensions.exists(dimension.name):
tm1.dimensions.create(dimension)
# Create cube Coffee Sales Data
cube_name = 'Coffee Sales'
cube = Cube(cube_name, ['Coffee Sales Date', 'Coffee Sales State', 'Coffee Sales Product','Coffee Sales Product Type', 'Coffee Sales Type', 'Coffee Sales Measure'])
if not tm1.cubes.exists(cube.name):
tm1.cubes.create(cube)
logger.info("Coffee Sales PA cube and dimensions created successfully.")
# Define the measures to be pushed
pLoad = ['Profit', 'Sales']
# Create separate DataFrames for 'Profit' and 'Sales' with appropriate measures
dfs = []
# Iterate over the measures in pLoad
for measure in pLoad:
# Create a dictionary for the DataFrame
d = {
'Date': df['Date'].astype(str),
'State': df['State'].astype(str),
'Product': df['Product'].astype(str),
'Product Type': df['Product Type'].astype(str),
'Type': df['Type'].astype(str),
'Measure': measure,
'Values': df[measure].astype(float) # Convert to float if needed
}
# Append the DataFrame to the list
dfs.append(pd.DataFrame(d))
# Concatenate the DataFrames into one
df1 = pd.concat(dfs, ignore_index=True)
# Build cellset from the DataFrame and push to TM1
cellset = build_cellset_from_pandas_dataframe(df1)
# Write values to TM1 cube
tm1.cubes.cells.write_values(
cube_name=cube_name,
cellset_as_dict=cellset
)
logger.info("Data pushed to Coffee Sales PA successfully.")
except Exception as e:
traceback_message = traceback.format_exc()
error_message = f"Error uploading data to TM1: {str(e)}\n{traceback_message}"
logger.error(error_message)
return {
'statusCode': 500,
'body': json.dumps(error_message)
}
def get_secret_value(secret_name, aws_region):
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=aws_region
)
try:
get_secret_value_response = client.get_secret_value(SecretId=secret_name)
secret = json.loads(get_secret_value_response['SecretString'])
logger.info('secret: %s', secret)
return secret # Return the secret when successfully retrieved
except Exception as e:
logger.error(f"Error retrieving secret {secret_name}: {str(e)}")
raise # Raise the exception to be handled by the caller
def lambda_handler(event, context):
secret_name = os.environ.get('SECRET_NAME')
aws_region = os.environ.get('AWS_REGION')
bucket_name = os.environ.get('S3_BUCKET')
file_key = os.environ.get('FILE_KEY')
# Get secret from AWS Secrets Manager
try:
secret = get_secret_value(secret_name, aws_region)
except Exception as e:
logger.error("Error processing secret retrieval:", exc_info=True)
return {
'statusCode': 500,
'body': json.dumps(f"Error processing secret retrieval: {str(e)}")
}
s3 = boto3.client('s3')
try:
# Read CSV file from S3
response = s3.get_object(Bucket=bucket_name, Key=file_key)
csv_content = response['Body'].read().decode('utf-8')
# Parse CSV content using Pandas
df = pd.read_csv(StringIO(csv_content))
df['Date'] = df['Date'].astype(str)
df['Product'] = df['Product'].astype(str)
df['Product Type'] = df['Product Type'].astype(str)
df['State'] = df['State'].astype(str)
df['Type'] = df['Type'].astype(str)
df['Profit'] = pd.to_numeric(df['Profit'], errors='coerce')
df['Sales'] = pd.to_numeric(df['Sales'], errors='coerce')
except Exception as e:
logger.error(e)
return {
'statusCode': 500,
'body': 'Error occurred while reading or parsing the CSV file.'
}
try:
# Uploade the Pandas data to TM1 using your IBM PA credentials
upload_to_tm1(df, secret)
except Exception as e:
logger.error(f"Error uploading data to TM1: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps(f"Error uploading data to TM1: {str(e)}")
}
return {
'statusCode': 200,
'body': json.dumps('Data uploaded to Planning Analytics successfully.')
}
- Run the commands below to create your AWS Lambda function. Use the ARN of the Lambda Layer created on step 17, and the ARN of the AWS IAM role create on step 13:
$ zip blog_coffee_sales_to_ibm_pa.zip blog_coffee_sales_to_ibm_pa.py
$ aws lambda create-function \
--function-name blog_coffee_sales_to_ibm_pa \
--runtime python3.11 \
--handler lambda_function.lambda_handler \
--zip-file fileb://blog_coffee_sales_to_ibm_pa.zip \
--role <<REPLACE_WITH_IAM_ROLE_ARN>> \
--environment Variables={FILE_KEY=to_ibm-pa-saas/Coffee_Chain_2020-2022.csv,S3_BUCKET=${S3_BUCKET_NAME},SECRET_NAME=ibm-pa-conn-secret} \
--timeout 60 \
--layers ${LAMBDA_LAYER_ARN} \
--region ${AWS_REGION}Pull data from IBM Planning Analytics into Amazon RDS
To access Amazon RDS directly from your AWS Lambda functions, the Lambda function must be configured with access to the same Amazon VPC as the Amazon RDS database. Refer to the Understanding database options for your serverless web applications blog for additional information.
20. Create a Python file with the code sample below, and upload it to AWS CloudShell:
import json, logging, os, boto3, psycopg2, pandas as pd
from psycopg2 import sql
from datetime import datetime
from TM1py.Services import TM1Service
from TM1py.Utils.Utils import build_pandas_dataframe_from_cellset
# Configure logger
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def get_secret_value(secret_name, aws_region):
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=aws_region
)
try:
get_secret_value_response = client.get_secret_value(SecretId=secret_name)
secret = json.loads(get_secret_value_response['SecretString'])
logger.info('Secret retrieved successfully')
return secret
except Exception as e:
logger.error(f"Error retrieving secret {secret_name}: {str(e)}")
raise
def lambda_handler(event, context):
# Environment variables
rds_secret_name = os.environ.get('RDS_SECRET_NAME')
tm1_secret_name = os.environ.get('TM1_SECRET_NAME')
aws_region = os.environ.get('AWS_REGION')
db_name = os.environ.get('DB_NAME')
db_host = os.environ.get('DB_HOST')
db_port = os.environ.get('DB_PORT')
try:
# Retrieve secrets for RDS connection
secret = get_secret_value(rds_secret_name, aws_region)
db_user = secret.get('username', '')
db_password = secret.get('password', '')
# TM1 connection parameters
tm1_secret = get_secret_value(tm1_secret_name, aws_region)
base_url = tm1_secret.get('base_url', '')
user = tm1_secret.get('user', '')
password = tm1_secret.get('password', '')
# TM1 connection parameters
params = {
"base_url": base_url,
"user": user,
"password": password
}
# Connect to TM1 and retrieve data
with TM1Service(**params) as tm1:
# Execute MDX query
mdx = """
SELECT NON EMPTY {[Coffee Sales Measure].[Coffee Sales Measure].MEMBERS} ON 0,
NON EMPTY {[Coffee Sales Date].[Coffee Sales Date].MEMBERS} *
{[Coffee Sales State].[Coffee Sales State].MEMBERS} *
{[Coffee Sales Type].[Coffee Sales Type].MEMBERS} *
{[Coffee Sales Product Type].[Coffee Sales Product Type].MEMBERS} *
{[Coffee Sales Product].[Coffee Sales Product].MEMBERS} ON 1 FROM [Coffee Sales]
"""
cellset = tm1.cubes.cells.execute_mdx(mdx)
# Build DataFrame from cellset
df = build_pandas_dataframe_from_cellset(cellset, multiindex=False)
# Rename columns
df.columns = ['Date', 'State', 'Product', 'Product Type', 'Type', 'Measure', 'Value']
df_pivot = df.pivot_table(index=['Date', 'State', 'Product', 'Product Type', 'Type'], columns='Measure', values='Value').reset_index()
df_pivot.columns = ['Date', 'State', 'Product', 'Product Type', 'Type', 'Profit', 'Sales']
# Connect to Postgres database
connection = psycopg2.connect(
host=db_host,
database=db_name,
user=db_user,
password=db_password,
port=db_port
)
with connection.cursor() as cursor:
# Check if table exists, if not create it
cursor.execute("""
CREATE TABLE IF NOT EXISTS coffeesales (
id SERIAL PRIMARY KEY,
date DATE,
state VARCHAR(255),
product VARCHAR(255),
product_type VARCHAR(255),
type VARCHAR(255),
profit FLOAT,
sales FLOAT
)
""")
connection.commit()
# Insert data into Postgres table
insert_query = """
INSERT INTO coffeesales (date, state, product, product_type, type, profit, sales)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
for index, row in df_pivot.iterrows():
cursor.execute(insert_query, (
row['Date'], row['State'], row['Product'], row['Product Type'], row['Type'], row['Profit'], row['Sales']
))
connection.commit()
# Retrieve the first 5 items from the table for validation
cursor.execute("SELECT * FROM coffeesales LIMIT 5")
rows = cursor.fetchall()
# Convert rows to JSON format
results = []
for row in rows:
result = {
'id': row[0],
'date': str(row[1]),
'state': row[2],
'product': row[3],
'product_type': row[4],
'type': row[5],
'profit': row[6],
'sales': row[7]
}
results.append(result)
logger.info("Data successfully inserted into Postgres.")
return {
'statusCode': 200,
'body': json.dumps(results)
}
except Exception as e:
error_message = f"Error: {str(e)}"
logger.error(error_message, exc_info=True)
return {
'statusCode': 500,
'body': json.dumps(error_message)
}
- Run the commands below to create your AWS Lambda function. Provide the following values to create the Environment Variables:
- ARN of the Lambda Layer created on step 17
- ARN of the AWS IAM role create on step 13
- The Amazon RDS endpoint, port and database name created on step 11
- The AWS Secrets Manager secret name for the Amazon RDS database
- The Subnet IDs for your AWS Lambda function, to access the Amazon RDS database
$ zip blog_coffee_sales_from_ibm_pa.zip blog_coffee_sales_from_ibm_pa.py
$ aws lambda create-function \
--function-name blog_coffee_sales_from_ibm_pa \
--runtime python3.11 \
--handler lambda_function.lambda_handler \
--zip-file fileb://blog_coffee_sales_from_ibm_pa.zip \
--role <<REPLACE_WITH_IAM_ROLE_ARN>> \
--environment Variables={DB_HOST=<<REPLACE_WITH_RDS_ENDPOINT>>,DB_PORT=<<REPLACE_WITH_RDS_PORT>>,DB_NAME=<<REPLACE_WITH_RDS_DBNAME>>,RDS_SECRET_NAME=<<REPLACE_WITH_SECRET_NAME_RDS>>,TM1_SECRET_NAME=ibm-pa-conn-secret} \
--timeout 60 \
--layers ${LAMBDA_LAYER_ARN} \
--region ${AWS_REGION} \
--vpc-config SubnetIds=<<REPLACE_WITH_SUBNET_1_ID>>,<<REPLACE_WITH_SUBNET_2_ID>>,SecurityGroupIds=<<REPLACE_WITH_SG_ID>>Create Amazon API Gateway REST APIs
To execute a simple integration simulation for AWS Lambda with IBM Planning Analytics, we’ve created a simple REST API called ibm-pa-test, using an API Key for authentication. Our API is configured with the following resources:
- import: POST method invoking the AWS Lambda function to push data from Amazon S3 to IBM Planning Analytics.
- export: POST method invoking the AWS Lambda function to pull data from IBM Planning Analytics to Amazon RDS.
Refer to Amazon API Gateway documentation to create APIs in your AWS account(s), and to the Security best practices in Amazon API Gateway documentation to make sure you apply appropriate security controls in your APIs.
Export data from Amazon S3 to IBM Planning Analytics
- From the Amazon API Gateway console, invoke REST API import resource (figure 5). This will trigger the execution of the AWS Lambda function to push data from the CSV file in Amazon S3 into IBM Planning Analytics.
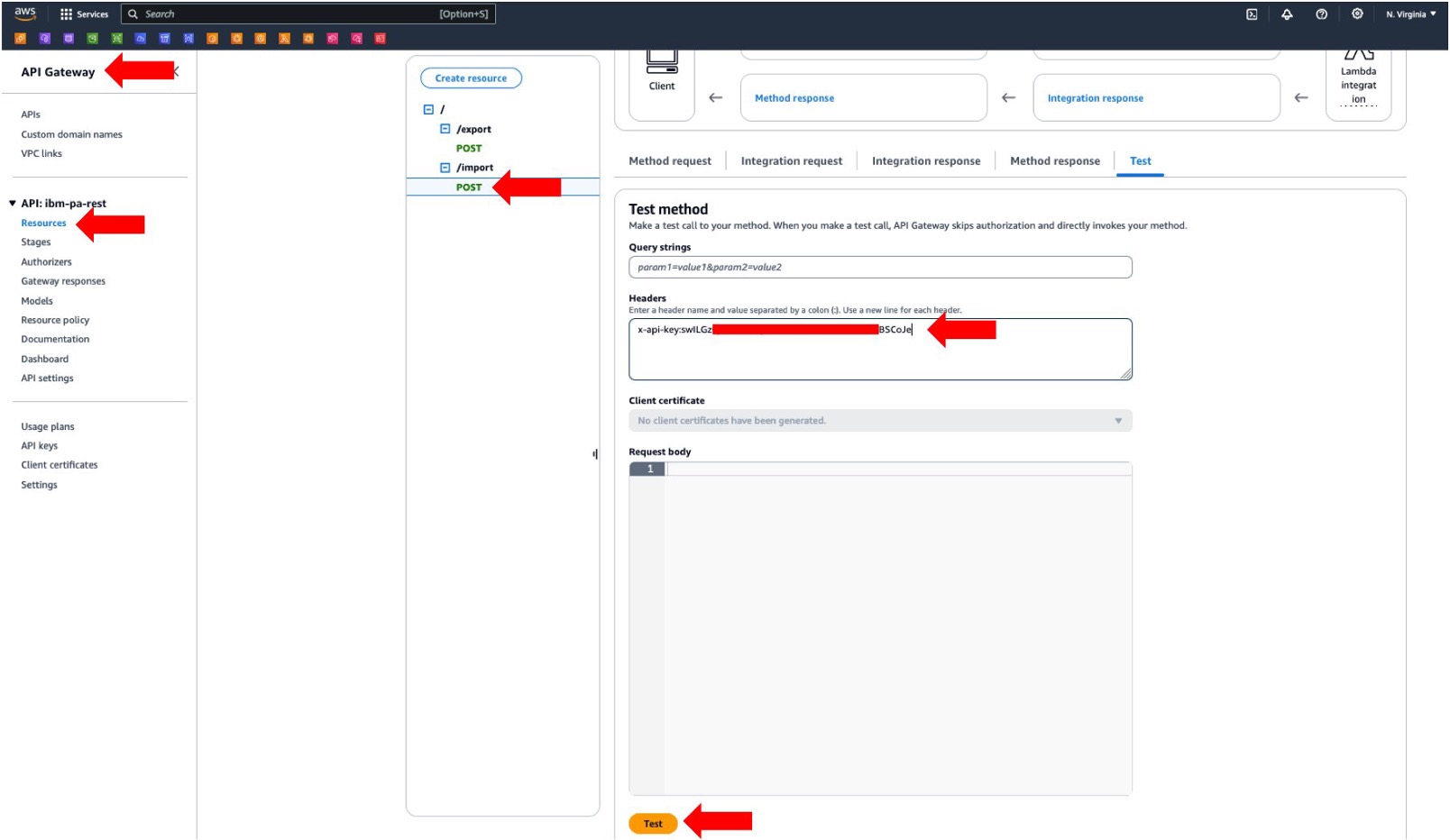
Figure 5. Invoking the REST API to push data from Amazon S3 to IBM Planning Analytics.
- Login to IBM Planning Analytics to verify the data upload
- Expand the navigation menu by clicking the icon on the top-left corner, next to IBM Planning Analytics. Click New and click Workbench to access your TM1 database (figure 6).
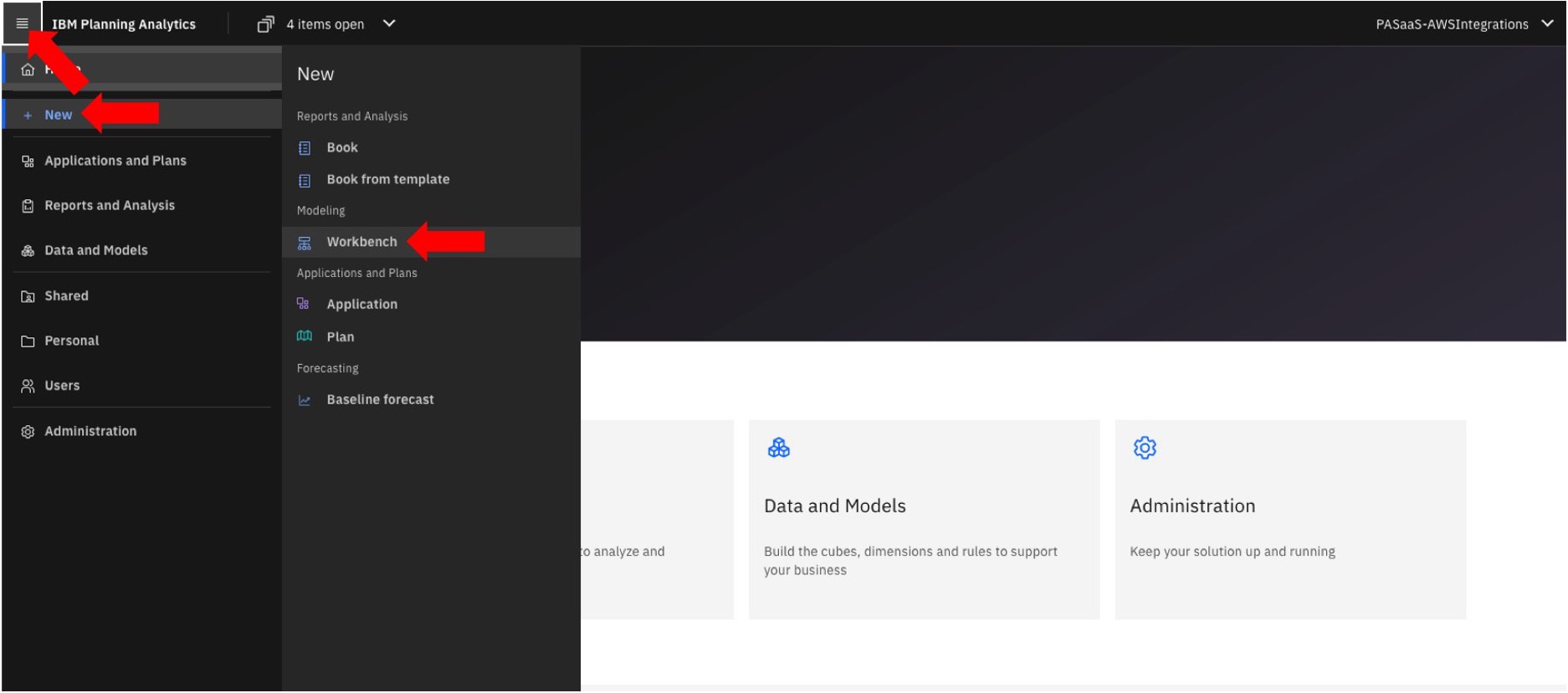
Figure 6. Navigate to the IBM Planning Analytics Workbench.
- From the Workbench console, click the Databases Expand your database instance in the navigation treeview, click on Cubes and double-click your cube’s name to create your view by dragging the Dimensions(figure7).
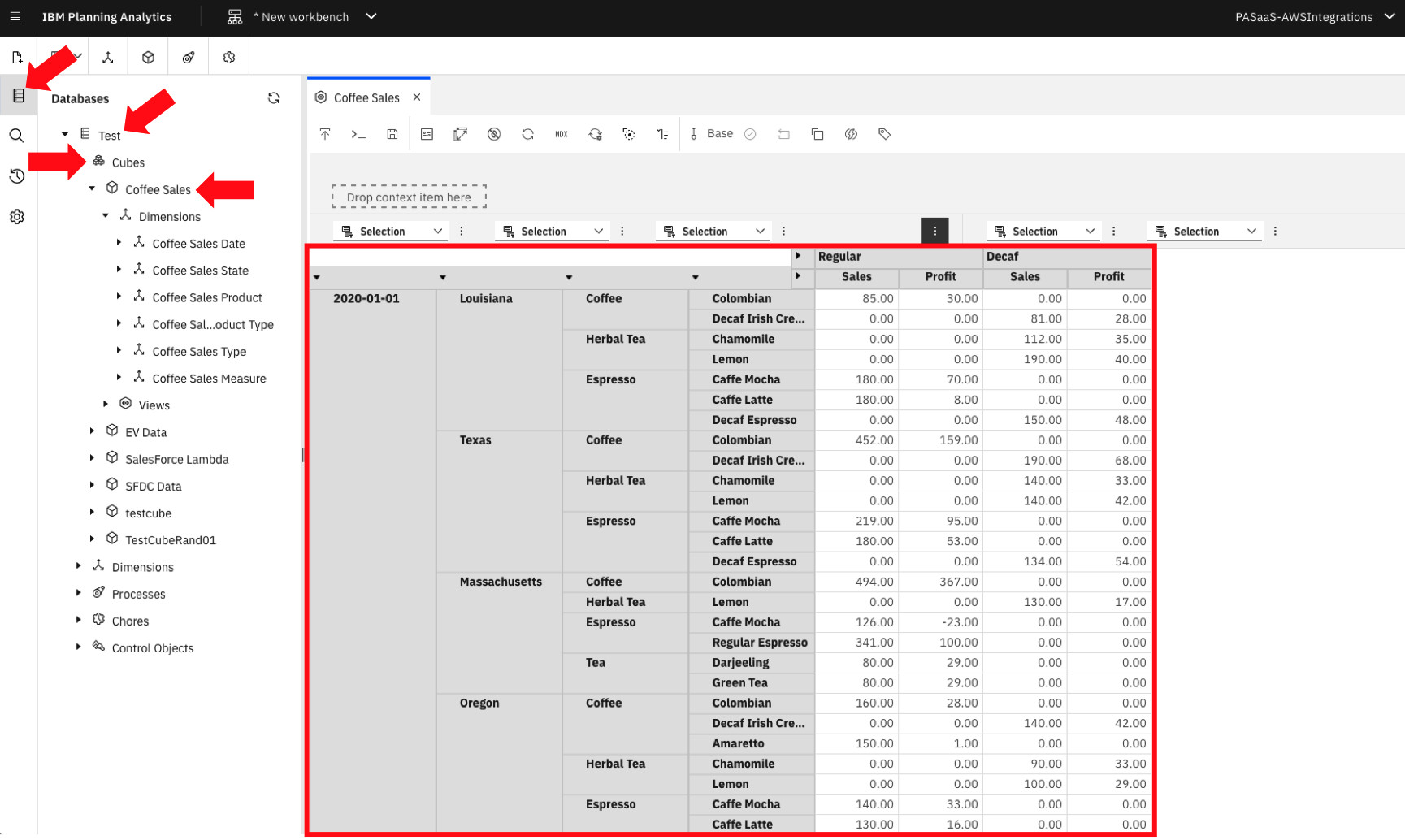
Figure 7. Data from our Amazon S3 CSV file uploaded to IBM Planning Analytics using AWS Lambda with TM1py.
- Now, let’s test the reverse flow. Let’s invoke our REST API export resource (figure 8), to trigger the execution of our AWS Lambda function to pull data from IBM Planning Analytics and persist it in our Amazon RDS database:
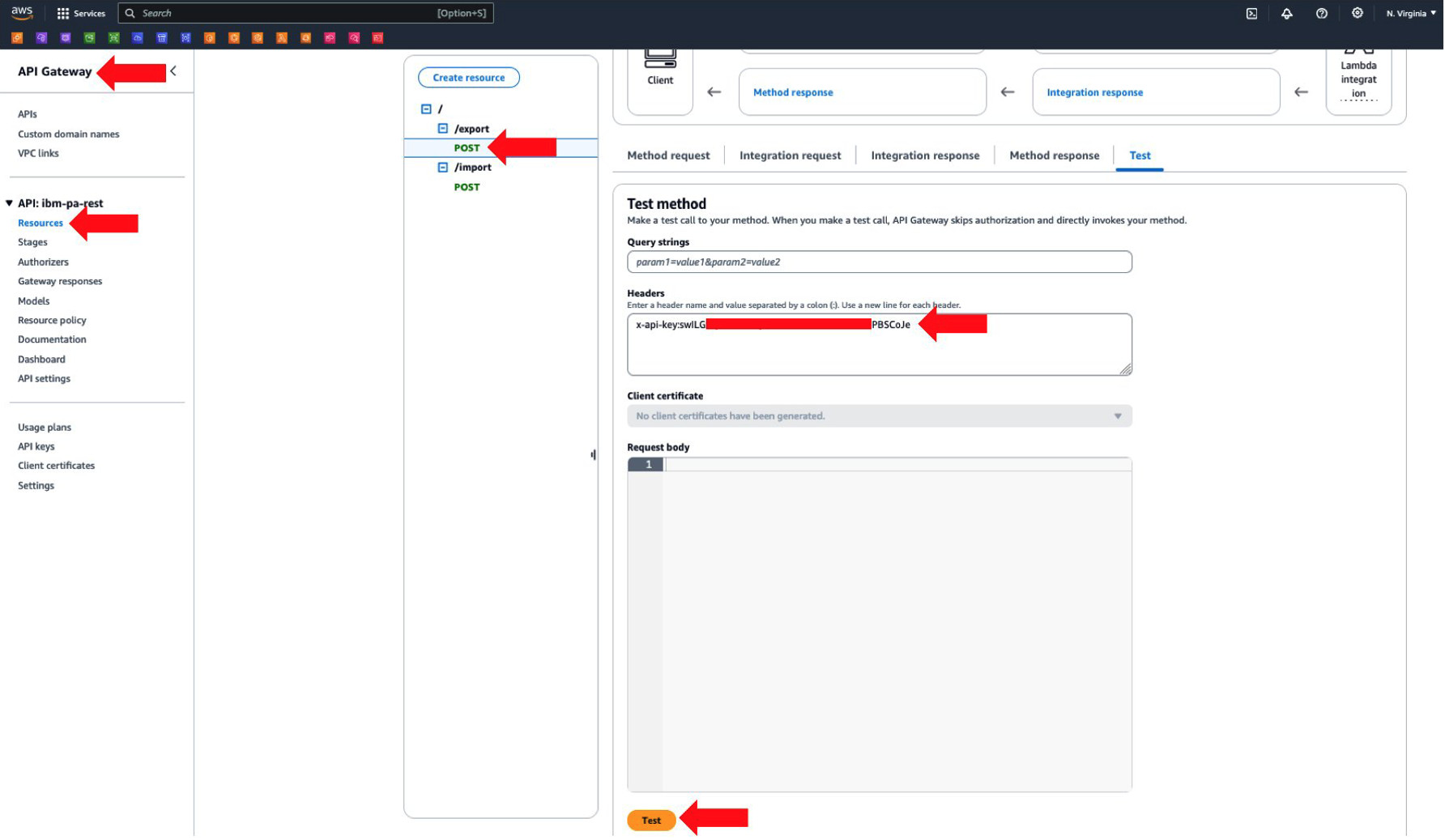
Figure 8. Invoking REST API to pull data from IBM Planning Analytics.
Once the API execution completes, it will show the execution output, with some of the data imported into our database (figure 9).
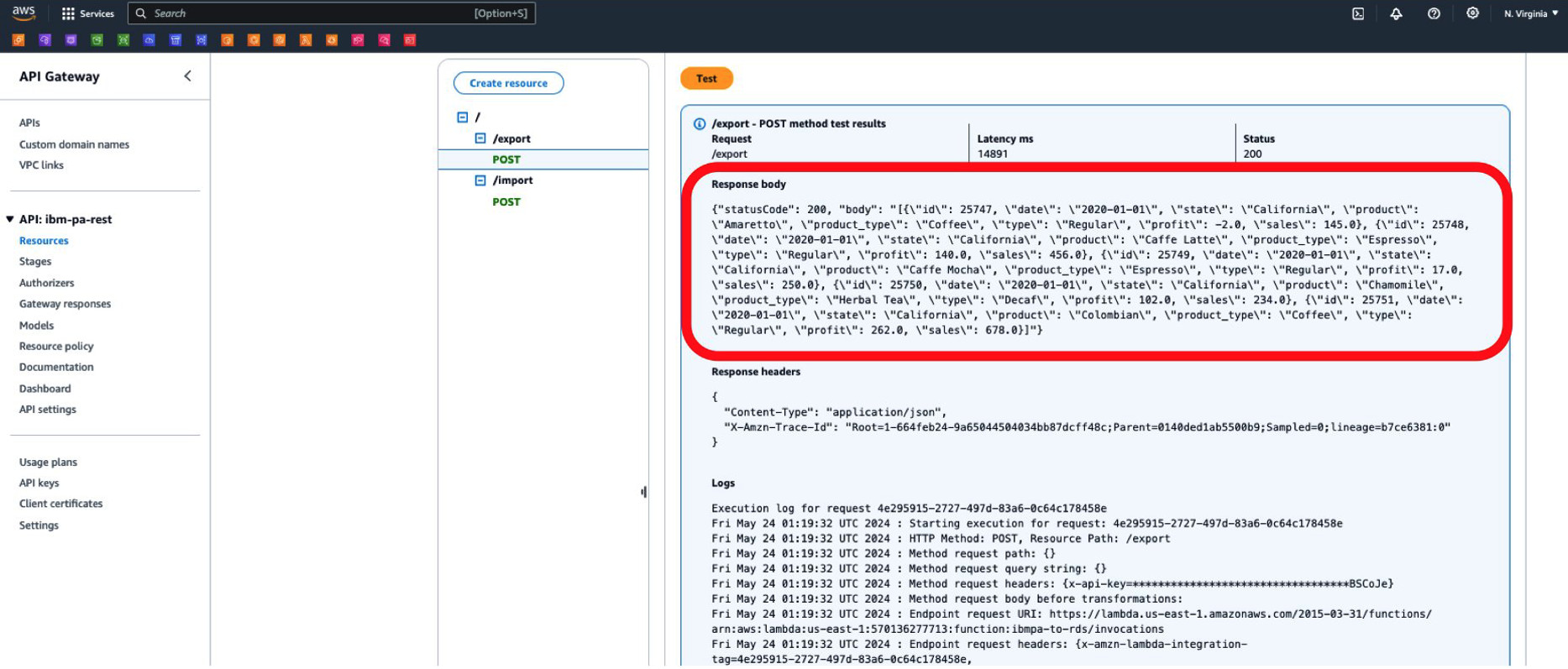
Figure 9. API execution output showing a sample of the data imported into Amazon RDS.
We can use a bastion host, in the same Amazon VPC as our Amazon RDS instance to validate that the database was successfully updated with data from IBM Planning Analytics (figure 10).
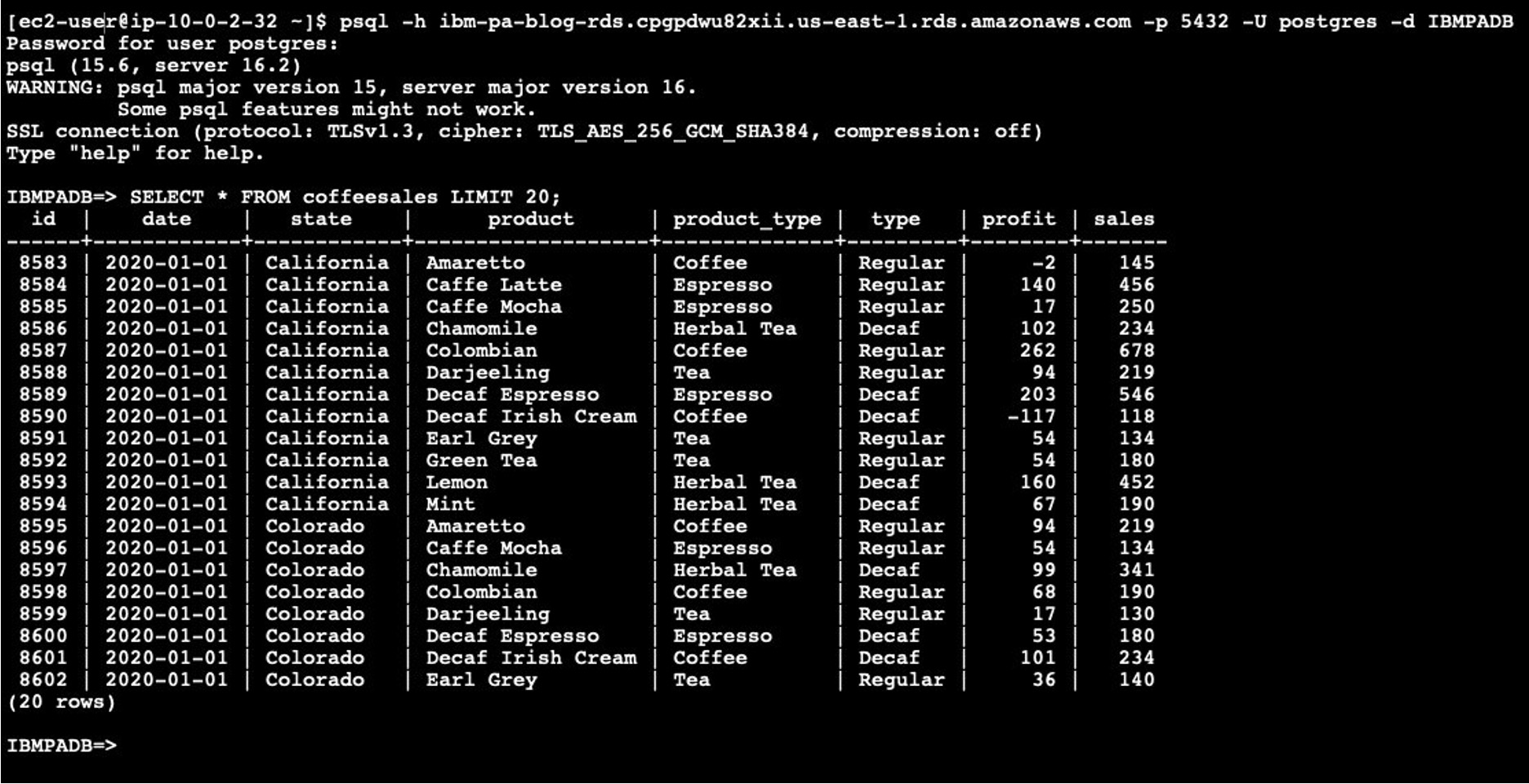
Figure 10. Querying our Amazon RDS database to validate the successful import of data from IBM Planning Analytics.
Creating different data integration architectures
By using AWS Lambda with TM1py, you can set up different ways to exchange data with IBM Planning Analytics SaaS on AWS. Figure 11 below, illustrates an example of an event-drive architecture to push Salesforce data into IBM Planning Analytics.
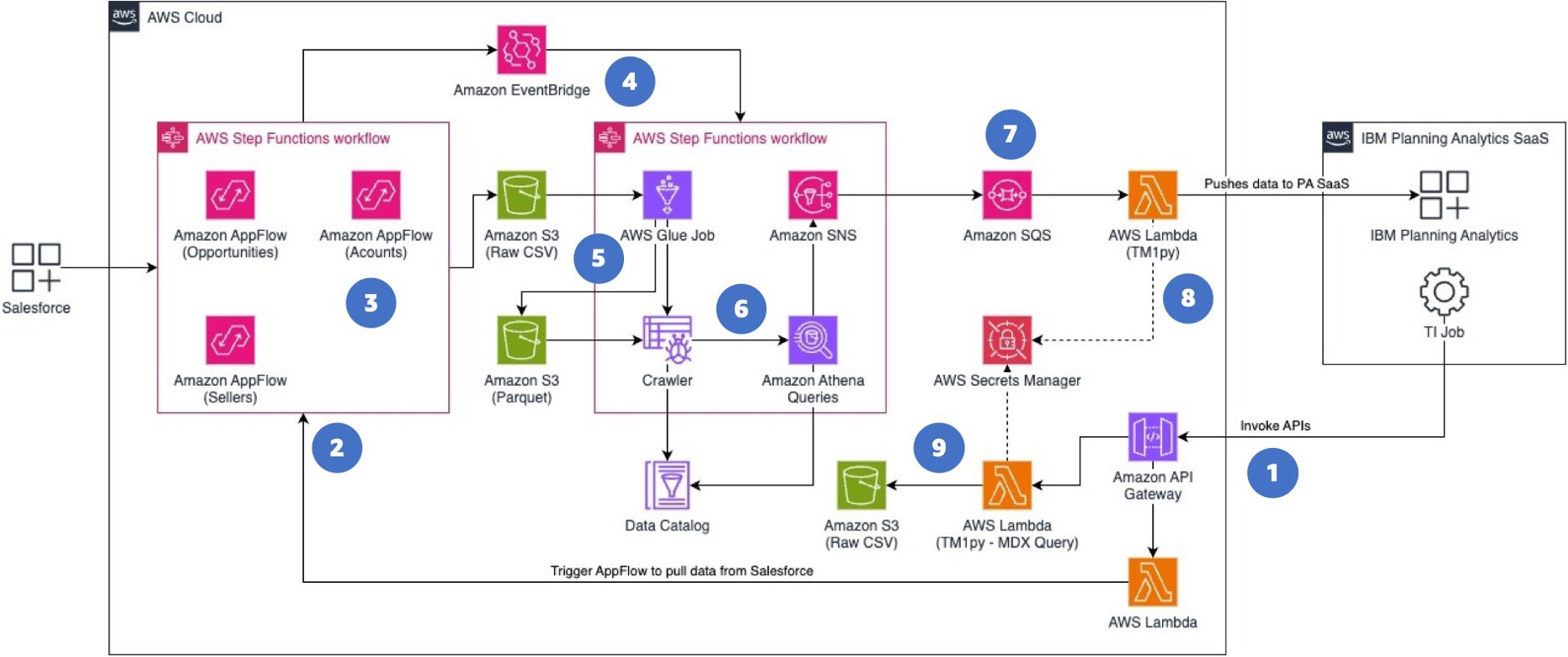
Figure 11. Using AWS services to push Salesforce data into IBM Planning Analytics.
Let’s take a closer look at this architecture flow:
- IBM Planning Analytics TurboIntegrator (TI) jobs use Amazon API Gateway to invoke APIs.
- AWS Lambda triggers AWS Step Functions for running Amazon AppFlow flows, pulling Salesforce data.
- Amazon AppFlow stores raw Salesforce data in Amazon S3 in formats like Parquet or CSV.
- Upon AppFlow completion, Amazon EventBridge notifies another Step Functions state machine to trigger an ETL pipeline.
- AWS Glue transforms Salesforce raw data and stores it in Amazon S3, while Glue Crawlers create a Data Catalog.
- AWS Step Functions can run parallel Amazon Athena queries for large data volumes, with results pushed to an Amazon SNS topic.
- An Amazon SQS queue subscribes to this SNS topic, invoking an AWS Lambda function with TM1py upon new messages.
- This Lambda function retrieves IBM Planning Analytics credentials from AWS Secrets Manager and uses TM1py to build cubes and dimensions, pushing Salesforce data into IBM Planning Analytics.
- Additionally, a Lambda function with TM1py can be invoked by TI jobs to retrieve and persist data into AWS repositories like Amazon S3.
Clean-up section
To avoid any costs on your AWS account(s), please make sure you delete any AWS Lambda functions, Amazon RDS instances and Amazon S3 buckets you have created to test this implementation.
Use the documentation listed below to delete the resources from your AWS account(s):
- Delete your Amazon RDS DB instance.
- Delete your Amazon S3 bucket.
- Delete your Amazon API Gateway REST APIs.
Use AWS CloudShell to delete your AWS Lambda functions. Example:
$ aws lambda delete-function \
--function-name blog_coffee_sales_to_ibm_pa
$ aws lambda delete-function \
--function-name blog_coffee_sales_from_ibm_pa
$ aws lambda delete-layer-version \
--layer-name TM1py_Layer \
--version-number 1Summary
This post demonstrated how to build AWS Lambda functions with TM1py to transfer data between AWS data sources like Amazon S3 and Amazon RDS, and IBM Planning Analytics SaaS on AWS. By implementing this type of integration, you can create data pipelines by connecting different data sources to your IBM Planning Analytics, automating your planning, budgeting, forecasting, and data analysis capabilities to make data-driven decisions.
Visit the AWS Marketplace for the IBM Data and AI SaaS solutions on AWS:
- IBM Planning Analytics as a Service on the AWS Marketplace
- IBM Db2 Warehouse as a Service
- IBM Netezza Performance Server as a Service
- IBM watsonx.data as a Service on AWS
- IBM on AWS Partner Page
Further content:
- What’s Under the Hood of the New IBM Planning Analytics as a Service on AWS
- Accelerate Data Modernization and AI with IBM Databases on AWS
- Making Data-Driven Decisions with IBM watsonx.data, an Open Data Lakehouse on AWS
- Migrate from self-managed Db2 to Amazon RDS for Db2 using AWS DMS
- IBM watsonx.data on AWS
- Introducing Db2 Warehouse on AWS
- Netezza Performance Server on AWS