AWS Compute Blog
Understanding database options for your serverless web applications
Many web developers use relational databases to store and manage data in their web applications. As you migrate to a serverless approach for web development, there are also other options available. These can help improve the scale, performance, and cost-effectiveness of your workloads. In this blog post, I highlight use-cases for different serverless database services, and common patterns useful for web applications.
Using Amazon RDS with serverless web applications
You can access Amazon RDS directly from your AWS Lambda functions. The RDS database, such as Amazon Aurora, is configured within the customer VPC. The Lambda function must be configured with access to the same VPC:

There are special considerations for this design in busy serverless applications. It’s common for popular web applications to experience “spiky” usage, where traffic volumes shift rapidly and unpredictably. Serverless services such as AWS Lambda and Amazon API Gateway are designed to automatically scale to meet these traffic increases.
However, relational databases are connection-based, so they are intended to work with a few long-lived clients, such as web servers. By contrast, Lambda functions are ephemeral and short-lived, so their database connections are numerous and brief. If Lambda scales up to hundreds or thousands of instances, you may overwhelm downstream relational databases with connection requests. This is typically only an issue for moderately busy applications. If you are using a Lambda function for low-volume tasks, such as running daily SQL reports, you do not experience this behavior.
The Amazon RDS Proxy service is built to solve the high-volume use-case. It pools the connections between the Lambda service and the downstream RDS database. This means that a scaling Lambda function is able to reuse connections via the proxy. As a result, the relational database is not overwhelmed with connections requests from individual Lambda functions. This does not require code changes in many cases. You only need to replace the database endpoint with the proxy endpoint in your Lambda function.
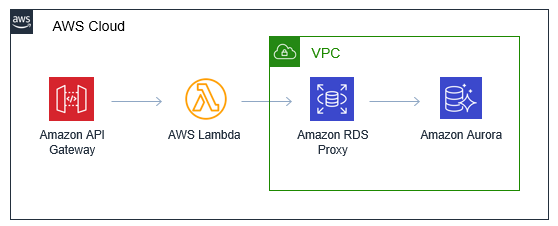
As a result, if you need to use a relational database in a high-volume web application, you can use RDS Proxy with minimal changes required.
Using Amazon DynamoDB as a high-performance operational database
Amazon DynamoDB is a high-performance key-value and document database that operates with single-digit millisecond response times at any scale. This is a NoSQL database that is a natural fit for many serverless workloads, especially web applications. It can operate equally well for low and high usage workloads. Unlike relational databases, the performance of a well-architected DynamoDB table is not adversely affected by heavy usage or large amounts of data storage.
For web applications, DynamoDB tables are ideal for storing common user configuration and application data. When integrated with Amazon Cognito, you can restrict row-level access to the current user context. This makes it a frequent choice for multi-tenant web applications that host data for many users.
DynamoDB tables can be useful for lookups of key-based information, in addition to geo-spatial queries in many cases. DynamoDB is not connection-based, so this integration works even if a Lambda function scales up to hundreds or thousands of concurrent executions. You can query directly from Lambda with minimal code:
const AWS = require('aws-sdk')
AWS.config.region = process.env.AWS_REGION
const documentClient = new AWS.DynamoDB.DocumentClient()
// Construct params
const params = {
TableName: 'myDDBtable',
Item: {
partitionKey: 'user-123',
sortKey: Date.now(),
name: 'Alice',
cartItems: 3
}
}
// Store in DynamoDB
const result = await documentClient.put(params).promise()
Using advanced patterns in DynamoDB, it’s possible to build equivalent features frequently found in relational schemas. For example, one-to-many tables, many-to-many tables, and ACID transactions can all be modeled in a single DynamoDB table.
Combining DynamoDB with RDS
While DynamoDB remains highly performant for high volumes of traffic, you need to understand data access patterns for your application before designing the schema. There are times where you need to perform ad hoc queries, or where downstream application users must use SQL-based tools to interact with databases.
In this case, combining both DynamoDB and RDS in your architecture can provide a resilient and flexible solution. For example, for a high-volume transactional web application, you can use DynamoDB to ingest data from your frontend application. For ad hoc SQL-based analytics, you could also use Amazon Aurora.
By using DynamoDB streams, you can process updates to a DynamoDB table using a Lambda function. In a simple case, this function can update tables in RDS, keeping the two databases synchronized. For example, when sales transactions are saved in DynamoDB, a Lambda function can post the sales information to transaction tables in Aurora.
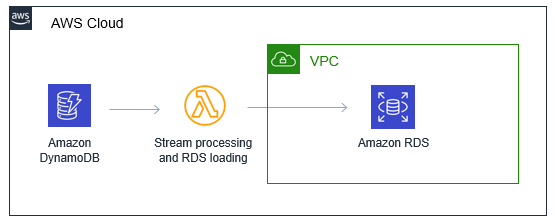
Both the Lambda function and RDS database operate with the customer’s VPC, while DynamoDB is outside the VPC. DynamoDB Streams can invoke Lambda functions configured to access the VPC. In this model, RDS users can then run ad hoc SQL queries without impacting operational data managed by DynamoDB.
High-volume ETL processes between DynamoDB and RDS
For high-volume workloads capturing large numbers of transactions in DynamoDB, Lambda may still scale rapidly and exhaust the RDS connection pool. To process these flows, you may introduce Amazon Kinesis Data Firehose to help with data replication between DynamoDB and RDS.

- New and updated items in DynamoDB are sent to a DynamoDB stream. The stream invokes a stream processing Lambda function, sending batches of records to Kinesis Data Firehose.
- Kinesis buffers incoming messages and performs data transformations using a Lambda function. It then writes the output to Amazon S3, buffering by size (1–128 MB) or interval (60–900 seconds).
- The Kinesis Data Firehose transformation uses a custom Lambda function for processing records as needed.
- Amazon S3 is a durable store for these batches of transformed records. As objects are written, S3 invokes a Lambda function.
- The Lambda function loads the objects from S3, then connects to RDS and imports the data.
This approach supports high transaction volumes, enabling table item transformation before loading into RDS. The RDS concurrent connection pool is optimized by upstream batching and buffering, which reduces the number of concurrent Lambda functions and RDS connections.
Conclusion
Web developers commonly use relational databases in building their applications. When migrating to serverless architectures, a web developer can continue to use databases like RDS, or take advantage of other options available. RDS Proxy enables developers to pool database connections and use connection-based databases with ephemeral functions.
DynamoDB provides high-performance, low-latency NoSQL support, which is ideal for many busy web applications with spiky traffic volumes. However, it’s also possible to use both services to take advantage of the throughput of DynamoDB, together with the flexibility of ad hoc SQL queries in RDS.
For extremely high traffic volumes, you can introduce Kinesis Data Firehose to batch and transform data between DynamoDB and RDS. In this case, you separate the operational database from the analytics database. This solution uses multiple serverless services to handle scaling automatically.
To learn more about AWS serverless database solutions for web developers, visit https://aws.amazon.com/products/databases/.