AWS for Industries
Edge-to-Cloud Architecture for Real-Time Surgical Intelligence with AWS and NVIDIA
Every year, over 300 million surgeries are performed globally. The operating room (OR) has long been a place of remarkable human skill, but also remarkable variability—two surgeons, same procedure, same hospital, potentially very different approaches and outcomes. In a recent Johnson and Johnson report, 95% of surgeons say better surgical software would help them improve care, yet the infrastructure to deliver it remains fragmented. With an increasing percentage of procedures being video captured, the opportunity to unlock clinical insights from this data is immense. Just one minute of HD surgical video contains 25 times the data of a CT scan — creating massive storage and transmission demands – and most healthcare facilities operate on legacy infrastructure with insufficient bandwidth and limited throughput, where network congestion delays critical data transmission.
Johnson & Johnson MedTech recently announced a major milestone in Surgical Intelligence through its Polyphonic™ ecosystem across hospitals in Abu Dhabi, collaborating with the Department of Health of Abu Dhabi, AWS and NVIDIA, alongside other technology and clinical partners. Polyphonic is designed as an open surgical intelligence ecosystem — connecting multimodal data, AI development, clinical workflows, and applications across hospitals, technologies, and partners.
With a growing ecosystem of participating healthcare and technology leaders, the initiative represents one of the first efforts to create a scalable foundation for AI in surgery — from real-time intelligence in the OR to research, model development, and future clinical applications.
This post explores representative edge-to-cloud architectural patterns and enabling technologies that can support the next generation of intelligent surgical environments. The examples below are illustrative of how interoperable AI infrastructure may be deployed to advance Surgical Intelligence at scale.
Using open-source frameworks including AWS IoT Greengrass and NVIDIA Holoscan platform, we demonstrate how edge-to-cloud operations enable sub-20ms clinical decision support — processing at the edge where data is generated, with cloud infrastructure providing scalable model training on anonymized data. This architecture addresses the interoperability standards that 98% of healthcare respondents say would deliver meaningful improvements,[1] unlocking the surgical video data that has remained trapped in the “black box” of the OR.
Three AI use cases transforming the operating room
The OR generates data across dozens of dimensions, but not all of it is equally actionable, and not all of it can wait. Three AI capabilities sit at the center of this architecture — not because they are the only possibilities, but because they address the three layers any surgical AI system must solve before it can scale.
De-identification ensures patient and staff identities are masked at the point of capture, using NVIDIA’s pre-trained models integrated into the sensor processing pipeline with Holoscan. Real-time masking at the edge means data is clean before it ever leaves the room — simplifying compliance across jurisdictions and enabling everything downstream.
Surgical phase recognition transforms raw video into structured clinical knowledge. AI classifies which step of a procedure is underway in real time — systems have achieved 93–95% accuracy in procedures such as sleeve gastrectomy, with the ability to detect missing or unexpected steps. Knowing the phase transforms how the surgical team is supported: it enables real-time workflow analytics, training feedback, and creates the temporal context that makes outcome correlation meaningful. A recording is only video; a recording tagged by phase is a structured dataset.
Instrument detection closes the loop between what tools were used, how, and with what outcome. Real-time identification and tracking supports intraoperative awareness, instrument counts, and safety checks — combined video and sensor approaches have achieved 90.3% detection rates, with recent multi-tool tracking systems demonstrating real-time inference at state-of-the-art performance. Beyond the procedure itself, instrument tracking feeds surgical training, quality review, and outcome correlation that identifies which tool patterns lead to better results.
Each capability enables the next. Together, they turn a video stream into a learning system.
Solution architecture for real-time surgical intelligence
The architecture organizes into three layers that form a continuous loop: the edge layer in the OR where real-time inference happens, the cloud layer where models are trained and improved, and the bridge layer that connects them securely and manages the fleet at scale. Each layer has a distinct role, and the value of the system comes from how they work together.
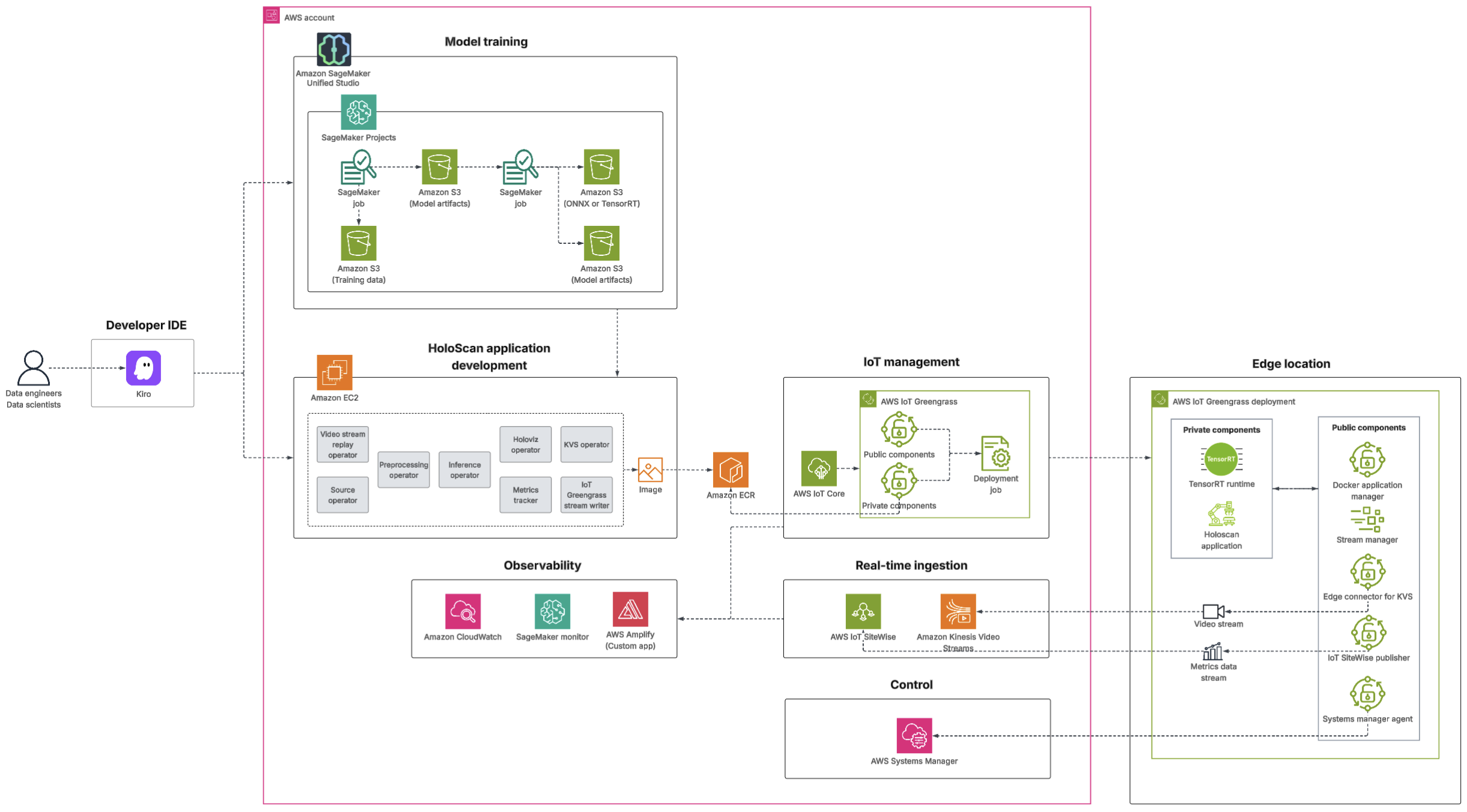
Figure 1: High-level architecture diagram of an edge to cloud configuration
The edge (OR)
At the center of an efficient edge-to-cloud architecture for the OR is the NVIDIA IGX platform. It combines enterprise-level hardware, software, and support, and it serves as the industrial grade foundation for real-time sensor processing. Powered by the NVIDIA Holoscan platform, a domain-agnostic multimodal AI sensor processing library, the edge component transforms raw video feeds and other OR-specific data into actionable intelligence with ultra-low latency. Beyond raw performance, this edge layer acts as a vital security gatekeeper: by applying de-identification protocols locally, sensitive information is stripped away before any data egresses to the cloud, ensuring robust privacy protection.
The NVIDIA IGX 700 provides the computational power needed for simultaneous multi-model inference while maintaining the low latency required for surgical applications.
Edge AI with NVIDIA IGX and Holoscan
Building a production-ready edge AI application requires more than a trained model. It requires a stack that can handle high-bandwidth sensor data with deterministic latency. By pairing NVIDIA IGX with the NVIDIA Holoscan platform, developers can turn a research prototype into a robust edge deployment.
At the core of the Holoscan deployment is the Inference Operator (InferenceOp). Although Holoscan is framework-agnostic, it’s designed to use NVIDIA TensorRT in the background for maximizing inferencing workloads. TensorRT optimizes your neural network by performing layer fusion, precision calibration, and kernel auto-tuning specifically for the CUDA-based architecture. When you define an inference task in Holoscan, you don’t need to manually write TensorRT boilerplate. The SDK’s inference module handles the transition. For example, you can provide a trained model in ONNX format, and Holoscan inference operator automatically converts it into a serialized TensorRT engine file during the first execution. Subsequent runs will skip the conversion, loading the optimized engine file directly into GPU memory for near-instantaneous inference.
One of the biggest challenges in edge AI deployments is environment drift, where applications work on a development kit but fail in production due to library mismatch. The Holoscan application will be containerized as a deployable bundle, including its runtime dependencies, configuration, and hardware specific NVIDIA TensorRT engine. It will then be wrapped as an AWS IoT Greengrass component with the required recipe, artifacts, and lifecycle definitions, and deployed to the target edge devices using the Greengrass deployment process. This workflow allows creating deployable components from a trained model and details of the target deployment hardware, benchmarks the application performance in a test environment, and allows deployment and production monitoring.
The cloud (AWS)
The edge delivers real-time decision support in the OR, but the intelligence behind those decisions is built, trained, and continuously improved in the cloud. AWS Cloud services provide the scalable infrastructure for model training, storage, and orchestration.
Data scientists can use Amazon SageMaker to build an end-to-end machine learning (ML) lifecycle starting from data annotation to hardware-specific model compilation for surgical videos. Here, we are using a Computational Analysis and Modeling of Medical Activities (CAMMA) dataset and converting raw surgical video into labeled training data, training models on GPU-accelerated infrastructure, and producing versioned artifacts that flow into the Holoscan packaging pipeline. The code in the src/model_training/ folder shows exactly how surgical instrument detection and surgical phase recognition use-cases come together.
Data preparation with Amazon SageMaker Processing
Surgical video datasets rarely arrive in the format a model expects. Raw footage from hospitals comes with proprietary annotation schemas—nested JSON files describing tool bounding boxes, phase labels, and frame metadata—that must be normalized before a training job can consume them. Rather than running this conversion on a data scientist’s laptop, we execute it as a SageMaker processing job. The job reads the raw dataset from Amazon Simple Storage Service (Amazon S3), converts annotations into the format each model architecture expects (YOLO-format labels for instrument detection, sliding-window frame sequences for phase recognition), and writes the prepared dataset back to Amazon S3.
This matters for two reasons: It scales—the same job prepares 10 videos or 10,000 without code changes, and it leaves a complete audit trail. Every dataset used to train a production model can be traced back to the exact source of videos and the annotation version and conversion logic that produced it. That traceability is a hard requirement for FDA ML pipeline audits and building it in from the start is far less expensive than retrofitting it later.
Training surgical instrument detection
The two use cases have different modeling needs, and the pipeline handles both natively:
- Surgical instrument detection uses a YOLOv8 object detection model—a PyTorch-based architecture that identifies and localizes surgical tools in individual video frames. It’s the workhorse for intraoperative awareness, instrument counts, and safety checks.
- Surgical phase recognition uses a CNN+LSTM temporal model—a ResNet backbone that encodes each frame, feeding into a recurrent layer that reasons over short sequences of frames to classify the current surgical phase. The temporal component matters: knowing whether the surgeon is in dissection or is clipping and cutting requires several seconds of context, not a single frame.
Both models train on SageMaker managed training jobs, running on GPU-accelerated instances that spin up on demand and shut down automatically when training completes. Data scientists don’t manage GPUs, patch Linux kernels, or babysit long-running jobs—they submit a training run and retrieve a versioned model artifact from Amazon S3 when it finishes. Training metrics and validation reports are tracked automatically in SageMaker Experiments, making it straightforward to compare model versions across runs.
This pipeline is loosely coupled with an edge. Nothing in the training code is aware of the target IGX 700 hardware. These artifacts are what the packaging pipeline consumes next. The pipeline retrieves the model from Amazon S3, converts it to TensorRT format for optimized inference on IGX hardware, and builds a Holoscan Application Package ready for deployment to the edge.
This cloud infrastructure enables continuous improvement through feedback loops—models trained on aggregated, anonymized data from multiple ORs are deployed back to edge devices, creating a learning system that improves with scale.
This is where the edge to cloud concept becomes concrete. Every procedure generates anonymized, de-identified data at the edge. That data flows to the cloud, where it’s used to retrain and improve models on aggregated datasets from multiple ORs. Improved models are packaged, validated, and deployed back to edge devices automatically and at scale, without rebuilding the system. The result is a surgical AI system that gets measurably better with every procedure it observes. That feedback loop—edge to cloud and back again—is what separates a point solution from a platform.
The bridge (cloud-to-edge management)
AWS IoT Greengrass runs on every IGX device and serves as the operational layer between the AI application and the hospital environment. Greengrass is an open source edge runtime with a mature component model for deploying, versioning, and orchestrating software on edge devices at scale.
The Holoscan application—packaged as a Holoscan Application Package (HAP)—is deployed as an IoT Greengrass component. The Holoscan app handles all inference workloads internally, while Greengrass orchestrates the processes between components on the device; connecting the AI application to AWS services for telemetry export, log management, stream buffering, secrets handling, and connectivity.
Flexible connectivity during procedures
Hospitals have different requirements for device connectivity during procedures. Some want real-time streaming of de-identified video and telemetry to the cloud. Others prefer devices to operate fully disconnected during surgery, with data uploaded afterward. A third model keeps all patient-related data local while sending only device telemetry—GPU health, inference latency, and deployment status—to the cloud for centralized management. The architecture supports all three without changes. IoT Greengrass components like Disk Spooler and Stream Manager buffer data locally and upload automatically when connectivity is available, and our topic hierarchy and AWS IoT Core policies keep device telemetry and patient-regulated data on separate pipelines with different access controls.
The remaining AWS services in this layer each play a focused role:
- AWS IoT Core handles device authentication and message routing, with its rules engine providing event-driven orchestration—filtering, transforming, and routing device messages to downstream services based on content (for example, triggering an AWS Lambda function when inference confidence drops below a threshold, or routing model metrics to Amazon CloudWatch while sending video metadata to Amazon S3).
- CloudWatch monitors model performance and device health across the fleet.
- AWS IoT SiteWise models the hospital asset hierarchy and stores time-series metrics.
- Lambda handles serverless workflows like continuous integration and delivery (CI/CD) triggers and deployment notifications.
Deep Dive: IoT fleet management and secure connectivity
Managing AI-enabled devices across multiple hospitals—each running different model versions for different surgical specialties—requires fleet-scale device management, provisioning, and orchestration.
Deploying models and configuration to the edge
IoT Greengrass supports two types of updates. Full package deployments deliver a new Holoscan Application Package—updated models, new use cases, or code changes. Configuration-only deployments change application behavior (blurry intensity, confidence thresholds, data egress settings) without touching the package itself. This separation means a single application can serve dozens of hospitals with different requirements—all managed through configuration rather than separate builds.
Both update types can target individual devices or device groups, with AWS IoT Core jobs coordinating rollouts across the fleet. All deployments are atomic and versioned, with configurable rollback policies on failure. The end-to-end flow is fully automated and runs from SageMaker training through AWS CodePipeline packaging to IoT Greengrass deployment.
Telemetry, observability, and operational support
Edge devices publish model performance metrics to structured MQTT topics, with AWS IoT Core routing telemetry to CloudWatch for monitoring, alerting, and fleet-wide dashboards. This is how we observe model performance across devices in sterile ORs without physical access. Inference latency, confidence scores, and device health are visible in near real time, with alarms firing before issues affect clinical workflows. Tracking these metrics over time also lets us detect model drift—gradual degradation in accuracy or confidence that signals a model needs retraining updated data. Biomedical engineers at each hospital site can access dashboards scoped to their facility, monitor device health, and escalate issues to the MedTech field service organization when intervention is needed.
We use Amazon Bedrock Guardrails for generating documentation and troubleshooting guides within approved boundaries for medical devices. Non-engineering staff, such as biomedical engineers, can use a natural language interface built with Amazon Connect Customer, Amazon Lex, Lambda, and Amazon Bedrock agents to query device status and deployment history in plain language, backed by real-time device data.
The model lifecycle: From training to deployed edge application
The model lifecycle moves through eight stages, each building on the last.
It begins in the developer IDE, where data engineers and data scientists design, configure, and trigger the workflows that feed both the training pipeline and the Holoscan application. From there, model training runs within Amazon SageMaker Unified Studio: SageMaker Jobs handle data preparation and training runs, MLFlow tracks experiments and artifacts for full reproducibility, and Amazon S3 stores both the source data and the resulting model artifacts. After training completes, model artifacts are converted and optimized for the target edge hardware, producing TensorRT-compatible formats ready for deployment on NVIDIA IGX devices.
The Holoscan application is then built and validated on Amazon Elastic Compute Cloud (Amazon EC2), where the optimized model artifacts are integrated directly into the Inference Operator. The application—composed of modular operators handling video ingestion, pre-processing, inference, metrics tracking, and stream output—is containerized and pushed to Amazon Elastic Container Registry (Amazon ECR), ready to be pulled to edge locations.
Deployment is managed through IoT Greengrass and AWS IoT Core, which package the application into versioned components and push them to edge devices. At the edge, the application runs in the OR—processing video locally in real time—with TensorRT handling inference and Stream Manager buffering data for cloud transmission. De-identified telemetry and video metadata flow back to the cloud through AWS IoT SiteWise and Amazon Kinesis Video Streams, while AWS Systems Manager provides centralized remote control across the entire device fleet without requiring physical access.
Observability closes the loop: CloudWatch monitors metrics and logs across all services, SageMaker Monitor tracks model performance in production and flags drift, and a custom AWS Amplify application surfaces operational dashboards for the teams managing the system.
The result is a pipeline where a data scientist can move from a new training run to a validated, deployed model on an edge device in an OR without managing infrastructure, without physical access to the device, and without rebuilding the system each time.
Conclusion
The hard problems in surgical AI aren’t algorithmic. Surgical phase recognition has been validated in peer-reviewed research at 93–95% accuracy. The challenge is building infrastructure that meets the OR where it is: constrained bandwidth, strict compliance requirements, no tolerance for latency, and hospital IT environments that weren’t designed with continuous AI deployment in mind.
That is what this architecture is designed to solve. SageMaker, IoT Greengrass, and the NVIDIA IGX and Holoscan platform each address a specific constraint. What makes them a system rather than a collection of components is the feedback loop: procedures generate anonymized data, the data trains better models, and better models deploy back to the edge across every connected OR without rebuilding the pipeline.
For teams building surgical AI today, the starting point isn’t a research question. It’s an infrastructure decision.
Get started
- Explore NVIDIA Holoscan SDK
- Learn about AWS IoT Greengrass for edge ML
- Build ML models with Amazon SageMaker