The Internet of Things on AWS – Official Blog
Building Connected Vehicle Solutions on the AWS Cloud
Update (2025): Amazon Kinesis Data Analytics for SQL Applications is retiring in 2026. Customers should migrate workloads to Amazon Managed Service for Apache Flink or Flink Studio. Please see the migration guide for additional details and step-by-step instructions.
In response to massive technological changes that are transforming the global automotive industry, the AWS Solutions team has developed the AWS Connected Vehicle solution in order to address the industry’s need for scalability, security, and flexibility when connecting products and services for next-generation vehicles. This reference architecture is designed in accordance with AWS best practices, and can be easily extended to solve a number of problems common to automotive manufacturers and suppliers. The AWS Connected Vehicle solution uses AWS CloudFormation to automatically deploy the architecture into your AWS account so you can start building your own automotive solutions in a matter of minutes.
The AWS Connected Vehicle solution consists of four layers: an ingestion services layer, a data services layer, an application services layer, and a platform API layer. Each layer strategically implements key AWS services that work together to enable secure, fast, simple, and scalable consumption, delivery, storage, and analysis of connected vehicle data.
{kind=link}
Here’s a quick tour of the solution and some of the architectural considerations that drove the development of this reference architecture.
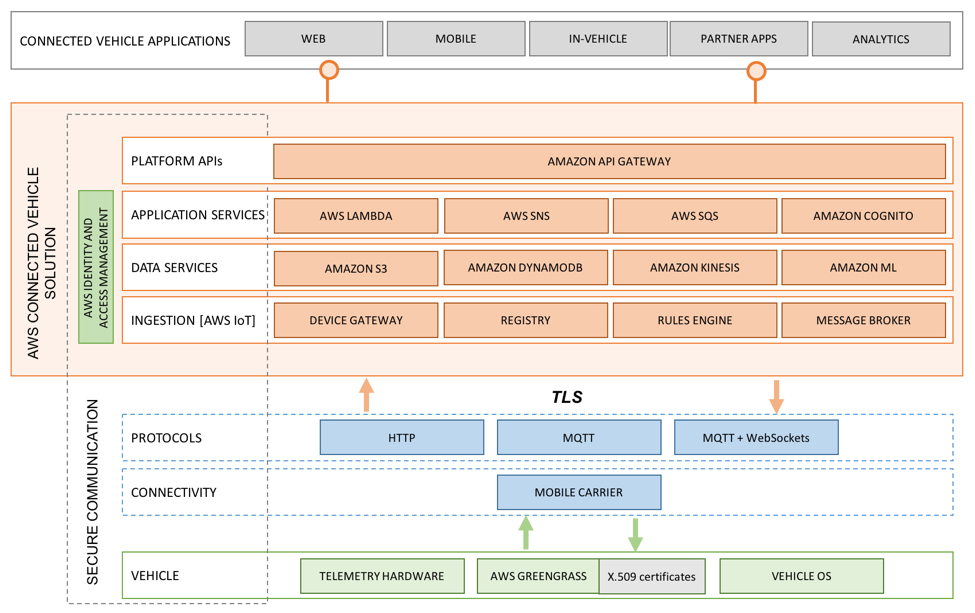
The bedrock of any successful cloud-based connected vehicle solution is the secure and scalable ingestion and rapid processing of connected vehicle data. To accomplish this, the AWS Connected Vehicle solution leverages AWS IoT, a managed cloud platform that lets connected devices easily and securely interact with cloud applications and other devices. Click here for a detailed introduction to the AWS IoT platform components.
The AWS IoT Device SDK makes it easy to seamlessly authenticate and connect devices with the Device Gateway and securely communicate with your AWS environment. AWS IoT automatically scales to support billions of devices and trillions of messages, and can reliably process and route those messages to other AWS services using a simple rules engine.
To add enhanced local compute, messaging, caching, and sync capabilities to your vehicle, you can use AWS Greengrass. AWS Greengrass Core is software that runs on your connected vehicle and works in conjunction with the IoT Device SDK to extend AWS to act locally on data produced by the vehicle. As a result, you can easily preprocess vehicle data, enable offline interaction, and manage over-the-air updates using the same simple code you use to write AWS Lambda functions.
Once you’ve delivered your connected vehicle data into the AWS Cloud, you need a reliable way to store it. Because connected vehicle solutions can store sensitive data from hundreds of thousands of vehicles from all over the world, your storage solution must be secure, scalable, and globally available. Amazon S3 meets all of these requirements and is designed to provide 99.99% availability and 99.999999999% durability of data. But how do we move connected vehicle data from AWS IoT to an Amazon S3 bucket?
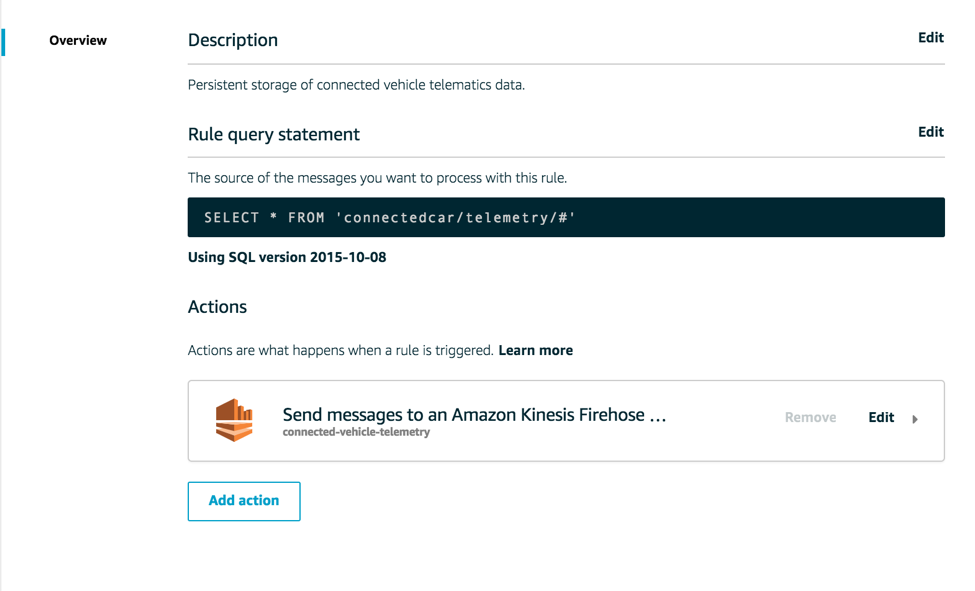
The answer is Amazon Kinesis Firehose, a managed and scalable data delivery service capable of capturing, transforming, compressing, and encrypting terabytes of streaming data before delivering it to Amazon S3. This makes connected vehicle data storage as simple as specifying Amazon Kinesis Firehose as a destination in the AWS IoT rules engine.
It is important to consistently load batches of raw data from AWS IoT to Amazon S3 so it can later be queried, analyzed, and replayed. But, certain events, such as warnings or anomalies, require real-time processing. For these use cases, you can leverage Amazon Kinesis Analytics and Amazon Kinesis Streams.
Amazon Kinesis Analytics makes it easy to build real-time streaming analytics applications using standard SQL code. As connected vehicle data moves through your Kinesis Firehose delivery stream, your streaming application will execute SQL code against the flowing data and extract interesting records. Using Amazon Kinesis, you can perform advanced anomaly detection and windowed aggregate functions, and enable real-time processing with just a few lines of simple SQL code. The following sample SQL code employs an unsupervised machine learning algorithm called random cut forest in order to assign anomaly scores to oil temperature records:
CREATE OR REPLACE STREAM "TEMP_STREAM" (
"ts" TIMESTAMP,
"oil_temp" DOUBLE,
"trip_id" VARCHAR(64),
"vin" VARCHAR(32),
"ANOMALY_SCORE" DOUBLE);
CREATE OR REPLACE STREAM "ANOMALY_OUTPUT_STREAM" (
"ts" TIMESTAMP,
"value" DOUBLE,
"trip_id" VARCHAR(64),
"vin" VARCHAR(32),
"ANOMALY_SCORE" DOUBLE,
"telemetric" VARCHAR(32));
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "TEMP_STREAM"
SELECT STREAM "ts","val", "trip_id", "vin", ANOMALY_SCORE FROM
TABLE(RANDOM_CUT_FOREST(
CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM_001" WHERE "name" = 'oil_temp')));
CREATE OR REPLACE PUMP "OUTPUT_PUMP" AS INSERT INTO "ANOMALY_OUTPUT_STREAM"
SELECT STREAM *,'oil_temp' as telemetric FROM "TEMP_STREAM";You can then extract these anomalies and send them to an Amazon Kinesis Stream to be processed by custom microservices. When developing these microservices, you should build them in an agile, scalable, and maintainable way. The easiest way to do this on the AWS Cloud is to use AWS Lambda functions which natively enable event-driven, on-demand data processing and automatically scale to meet the demand of your connected vehicle data. Additionally, since Lambda functions are serverless, you can run your code without provisioning or managing servers. Just upload your code, define a trigger, and Lambda takes care of everything required to run and scale your code.
Once your microservices process the data, you need to make sure that downstream applications can easily consume the results. One simple way to accomplish this is with Amazon DynamoDB, a fast, flexible, and massively scalable database solution that allows you to query terabytes of data with millisecond latency.
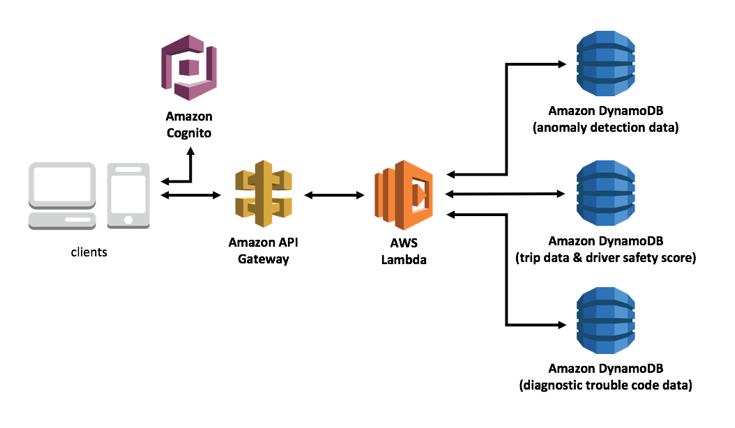
With your data in managed DynamoDB tables, you now need a streamlined method for retrieving this data for a variety of mobile, web, or in-vehicle applications. One easy method is to use Amazon’s managed API creation, management, and publishing service, API Gateway. The AWS Connected Vehicle solution is deployed with a tailored RESTful API that acts as a ‘front door’ for a Lambda function that can process requests from mobile and web apps and third-party service providers. Authorization and access control is handled via integration with Amazon Cognito User Pools, allowing drivers with authenticated profiles to retrieve only the data they own. With a few clicks, you can add methods to the API and provide extended access to backend data and business logic.
While there is no limit to the kinds of connected vehicle services and applications you can build with the AWS Connected Vehicle solution, the reference architecture comes packaged with a variety of high-level services to showcase solutions that address common problems in the automotive space, and help demonstrate microservice application development on top of the AWS Connected Vehicle solution.
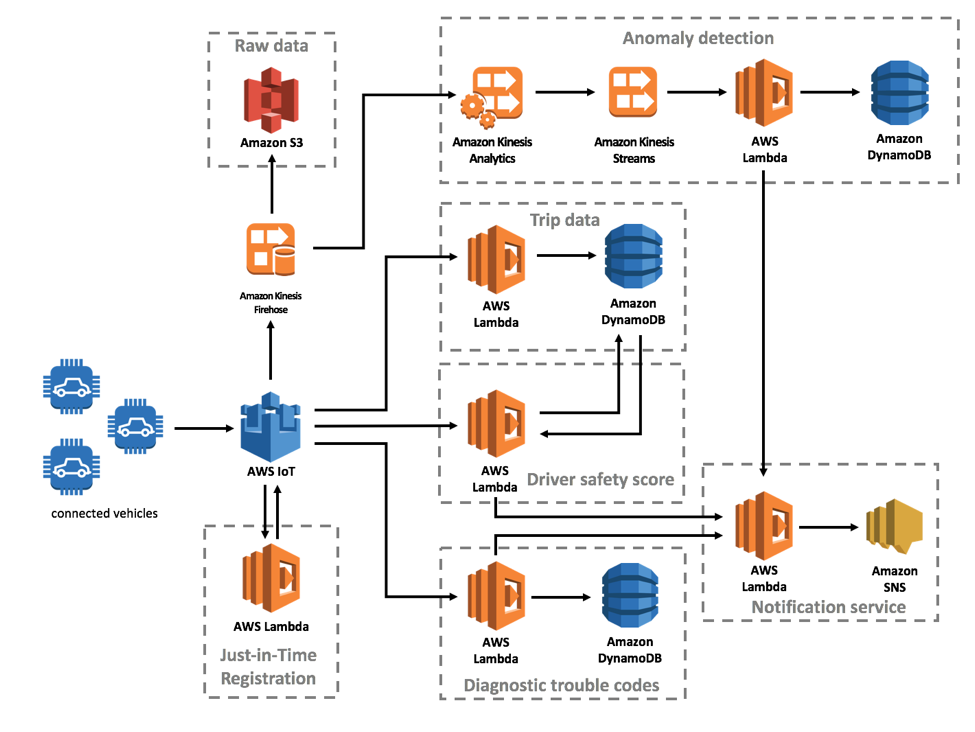
The just-in-time-registration (JITR) use case shows you how to simplify the process of registering a new vehicle with AWS IoT. The JITR workflow triggers an AWS Lambda function that activates a signed, unknown vehicle certificate, and attaches a custom security policy to it, enabling it to be used for authentication and authorization with AWS IoT.
The anomaly detection use case demonstrates how you can detect outliers in streaming data using Amazon Kinesis. As raw vehicle sensor data streams to Amazon S3 through an Amazon Kinesis Firehose delivery stream, an Amazon Kinesis Analytics application analyzes each record, extracts anomalies, and sends those records to an Amazon Kinesis Stream, triggering an AWS Lambda function that stores the data and notifies the driver of any issues.
The trip data use case demonstrates the consumption and storage of connected vehicle data that was previously processed by AWS Greengrass. Vehicle sensor data is aggregated on the vehicle and pushed to the AWS Connected Vehicle solution at regular intervals, and then stored in an Amazon DynamoDB table. Upon completion of a trip, a driver safety score microservice is triggered, which uses the aggregated trip data to calculate a safety score based on the driver’s speed, idling, and acceleration metrics, then subsequently notifies the driver.
Finally, diagnostic trouble code (DTC) detection is a simple but valuable use case that improves the vehicle ownership and maintenance experience. When DTCs are detected by AWS IoT, it invokes an AWS Lambda function that stores the DTC in an Amazon DynamoDB table, translates the DTC into layman’s terms, and then alerts the driver of the issue.
In addition to providing scalable, modular, API-driven applications, the AWS Connected Vehicle solution uses AWS services that are entirely managed and serverless. Therefore, you do not need to worry about patching, managing, or scaling your infrastructure to meet the demand of more users or vehicles. Furthermore, since this reference architecture is open-source, and leverages a pay-as-you-go pricing model, there is no need to worry about software licenses or contracts, or long-term purchase agreements. As with other AWS services, you pay for only what you use. As a result, users of the AWS Connected Vehicle solution can focus on building innovative applications and solutions instead of worrying about overhead management and administrative tasks.
Build away, automotive innovators and industry changers! We can’t wait to see what you create with the AWS Connected Vehicle solution.