Artificial Intelligence
Category: Amazon OpenSearch Service
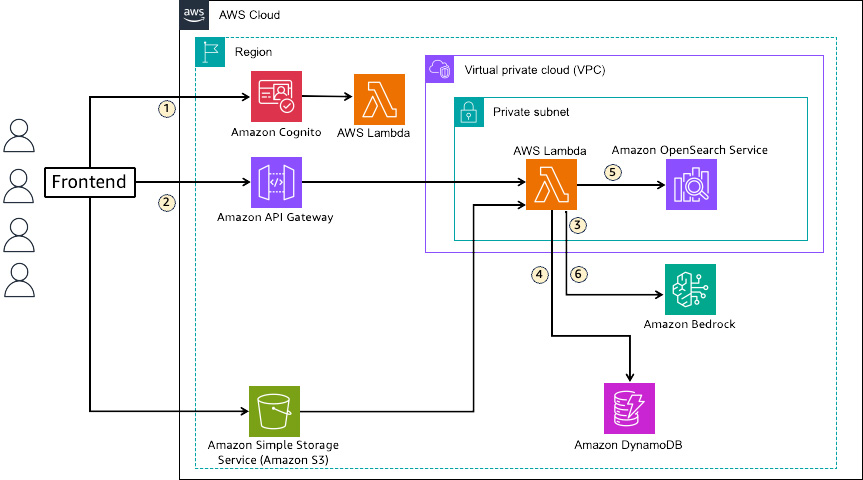
Multi-tenant RAG implementation with Amazon Bedrock and Amazon OpenSearch Service for SaaS using JWT
In this post, we introduce a solution that uses OpenSearch Service as a vector data store in multi-tenant RAG, achieving data isolation and routing using JWT and FGAC. This solution uses a combination of JWT and FGAC to implement strict tenant data access isolation and routing, necessitating the use of OpenSearch Service.
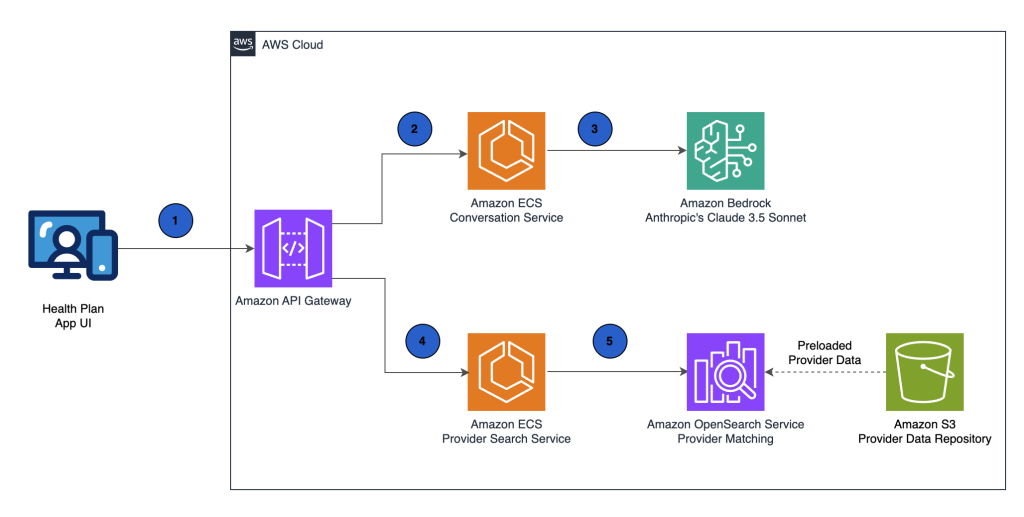
Kyruus builds a generative AI provider matching solution on AWS
In this post, we demonstrate how Kyruus Health uses AWS services to build Guide. We show how Amazon Bedrock, a fully managed service that provides access to foundation models (FMs) from leading AI companies and Amazon through a single API, and Amazon OpenSearch Service, a managed search and analytics service, work together to understand everyday language about health concerns and connect members with the right providers.
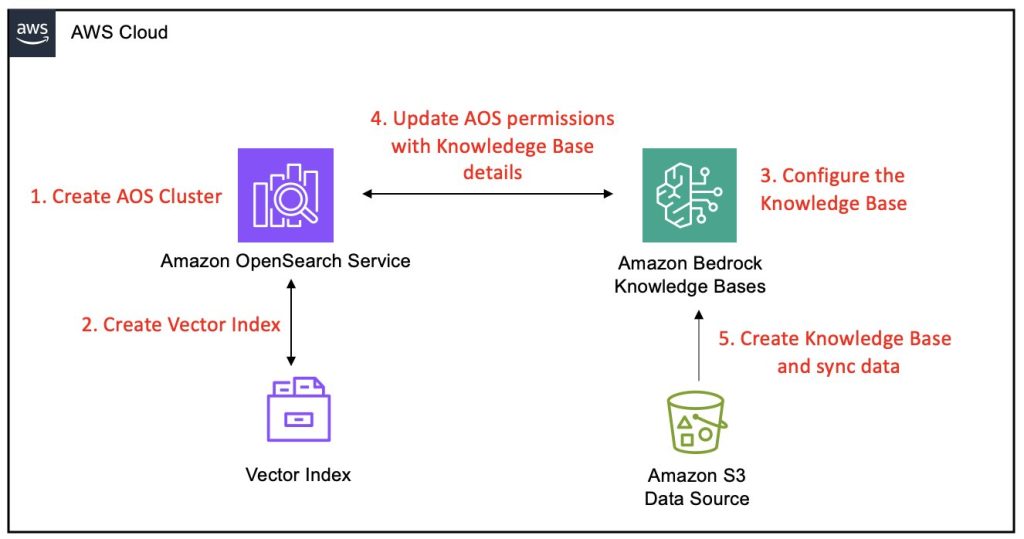
Amazon Bedrock Knowledge Bases now supports Amazon OpenSearch Service Managed Cluster as vector store
Amazon Bedrock Knowledge Bases has extended its vector store options by enabling support for Amazon OpenSearch Service managed clusters, further strengthening its capabilities as a fully managed Retrieval Augmented Generation (RAG) solution. This enhancement builds on the core functionality of Amazon Bedrock Knowledge Bases , which is designed to seamlessly connect foundation models (FMs) with internal data sources. This post provides a comprehensive, step-by-step guide on integrating an Amazon Bedrock knowledge base with an OpenSearch Service managed cluster as its vector store.

Optimize RAG in production environments using Amazon SageMaker JumpStart and Amazon OpenSearch Service
In this post, we show how to use Amazon OpenSearch Service as a vector store to build an efficient RAG application.

Adobe enhances developer productivity using Amazon Bedrock Knowledge Bases
Adobe partnered with the AWS Generative AI Innovation Center, using Amazon Bedrock Knowledge Bases and the Vector Engine for Amazon OpenSearch Serverless. This solution dramatically improved their developer support system, resulting in a 20% increase in retrieval accuracy. In this post, we discuss the details of this solution and how Adobe enhances their developer productivity.

Implement semantic video search using open source large vision models on Amazon SageMaker and Amazon OpenSearch Serverless
In this post, we demonstrate how to use large vision models (LVMs) for semantic video search using natural language and image queries. We introduce some use case-specific methods, such as temporal frame smoothing and clustering, to enhance the video search performance. Furthermore, we demonstrate the end-to-end functionality of this approach by using both asynchronous and real-time hosting options on Amazon SageMaker AI to perform video, image, and text processing using publicly available LVMs on the Hugging Face Model Hub. Finally, we use Amazon OpenSearch Serverless with its vector engine for low-latency semantic video search.

Using Amazon OpenSearch ML connector APIs
OpenSearch offers a wide range of third-party machine learning (ML) connectors to support this augmentation. This post highlights two of these third-party ML connectors. The first connector we demonstrate is the Amazon Comprehend connector. In this post, we show you how to use this connector to invoke the LangDetect API to detect the languages of ingested documents. The second connector we demonstrate is the Amazon Bedrock connector to invoke the Amazon Titan Text Embeddings v2 model so that you can create embeddings from ingested documents and perform semantic search.

Revolutionizing earth observation with geospatial foundation models on AWS
In this post, we explore how a leading GeoFM (Clay Foundation’s Clay foundation model available on Hugging Face) can be deployed for large-scale inference and fine-tuning on Amazon SageMaker.

Combine keyword and semantic search for text and images using Amazon Bedrock and Amazon OpenSearch Service
In this post, we walk you through how to build a hybrid search solution using OpenSearch Service powered by multimodal embeddings from the Amazon Titan Multimodal Embeddings G1 model through Amazon Bedrock. This solution demonstrates how you can enable users to submit both text and images as queries to retrieve relevant results from a sample retail image dataset.

Clario enhances the quality of the clinical trial documentation process with Amazon Bedrock
The collaboration between Clario and AWS demonstrated the potential of AWS AI and machine learning (AI/ML) services and generative AI models, such as Anthropic’s Claude, to streamline document generation processes in the life sciences industry and, specifically, for complicated clinical trial processes.