Artificial Intelligence
Category: Amazon OpenSearch Service

Build a semantic layer for agentic AI on AWS with Stardog and Amazon Bedrock AgentCore
In this post we show how to build a semantic layer on AWS using Stardog’s Semantic AI Application over Amazon Aurora and Amazon Redshift, and how to run a Strands Agents agent on Amazon Bedrock AgentCore that queries the layer to answer customer 360 questions across both sources without extract, transform, and load (ETL). The same Stardog deployment works behind AWS computes (Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), and AWS Lambda). We use AgentCore here because it bundles inbound auth, hosting, and tool credentials into one managed service.

Embed the world: Multimodal AI for searchable aerial imagery at scale
In this post, we walk through the problem space, our architecture on Amazon Bedrock and Amazon OpenSearch Serverless, the evaluation methodology we built on OpenStreetMap ground truth, four experiments that compared embedding models, fusion strategies, captioning, and search methods, and the practical guidance you can apply when building a similar system. You’ll learn which design choices move the needle for geospatial semantic search, including why Amazon Nova Multimodal Embeddings delivered the highest F1 scores across both benchmark queries in our evaluation. The work described here evolved into Vexcel Intelligence, a searchable imagery product.

Halliburton enhances seismic workflow creation with Amazon Bedrock and Generative AI
In this post, we’ll explore how we built a proof-of-concept that converts natural language queries into executable seismic workflows while providing a question-answering capability for Halliburton’s Seismic Engine tools and documentation. We’ll cover the technical details of the solution, share evaluation results showing workflow acceleration of up to 95%, and discuss key learnings that can help other organizations enhance their complex technical workflows with generative AI.

Transform retail with AWS generative AI services
Online retailers face a persistent challenge: shoppers struggle to determine the fit and look when ordering online, leading to increased returns and decreased purchase confidence. The cost? Lost revenue, operational overhead, and customer frustration. Meanwhile, consumers increasingly expect immersive, interactive shopping experiences that bridge the gap between online and in-store retail. Retailers implementing virtual try-on […]

Building Intelligent Search with Amazon Bedrock and Amazon OpenSearch for hybrid RAG solutions
In this post, we show how to implement a generative AI agentic assistant that uses both semantic and text-based search using Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents and Amazon OpenSearch.

How LinqAlpha assesses investment theses using Devil’s Advocate on Amazon Bedrock
LinqAlpha is a Boston-based multi-agent AI system built specifically for institutional investors. The system supports and streamlines agentic workflows across company screening, primer generation, stock price catalyst mapping, and now, pressure-testing investment ideas through a new AI agent called Devil’s Advocate. In this post, we share how LinqAlpha uses Amazon Bedrock to build and scale Devil’s Advocate.

Unlocking video understanding with TwelveLabs Marengo on Amazon Bedrock
In this post, we’ll show how the TwelveLabs Marengo embedding model, available on Amazon Bedrock, enhances video understanding through multimodal AI. We’ll build a video semantic search and analysis solution using embeddings from the Marengo model with Amazon OpenSearch Serverless as the vector database, for semantic search capabilities that go beyond simple metadata matching to deliver intelligent content discovery.
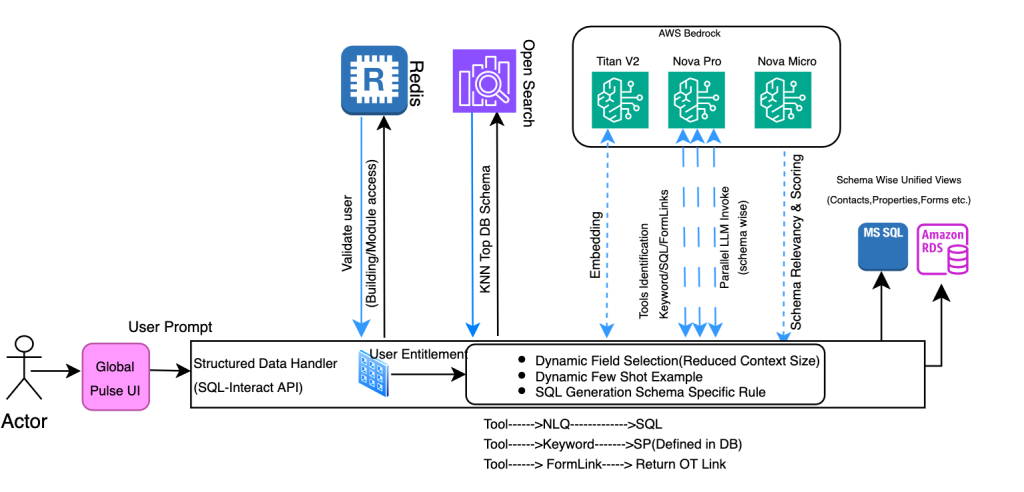
How CBRE powers unified property management search and digital assistant using Amazon Bedrock
In this post, CBRE and AWS demonstrate how they transformed property management by building a unified search and digital assistant using Amazon Bedrock, enabling professionals to access millions of documents and multiple databases through natural language queries. The solution combines Amazon Nova Pro for SQL generation and Claude Haiku for document interactions, achieving a 67% reduction in processing time while maintaining enterprise-grade security across more than eight million documents.
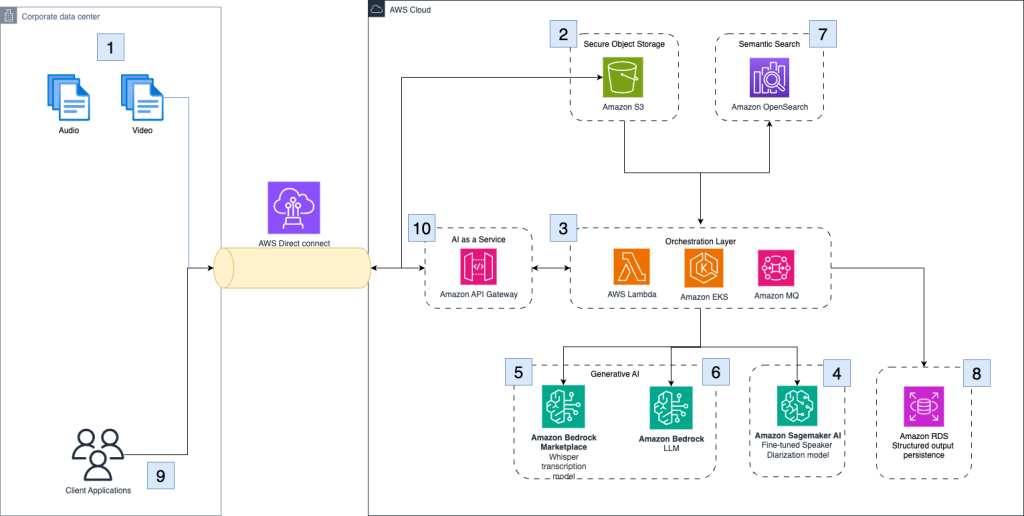
How Clario automates clinical research analysis using generative AI on AWS
In this post, we demonstrate how Clario has used Amazon Bedrock and other AWS services to build an AI-powered solution that automates and improves the analysis of COA interviews.
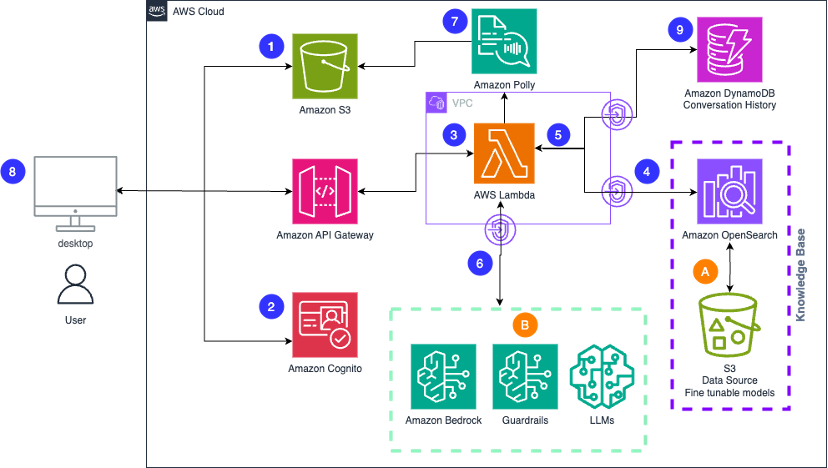
Build scalable creative solutions for product teams with Amazon Bedrock
In this post, we explore how product teams can leverage Amazon Bedrock and AWS services to transform their creative workflows through generative AI, enabling rapid content iteration across multiple formats while maintaining brand consistency and compliance. The solution demonstrates how teams can deploy a scalable generative AI application that accelerates everything from product descriptions and marketing copy to visual concepts and video content, significantly reducing time to market while enhancing creative quality.