Artificial Intelligence
Category: AWS Glue

How Genworth built a serverless ML pipeline on AWS using Amazon SageMaker and AWS Glue
This post is co-written with Liam Pearson, a Data Scientist at Genworth Mortgage Insurance Australia Limited. Genworth Mortgage Insurance Australia Limited is a leading provider of lenders mortgage insurance (LMI) in Australia; their shares are traded on Australian Stock Exchange as ASX: GMA. Genworth Mortgage Insurance Australia Limited is a lenders mortgage insurer with over […]

Setting up Amazon Personalize with AWS Glue
Data can be used in a variety of ways to satisfy the needs of different business units, such as marketing, sales, or product. In this post, we focus on using data to create personalized recommendations to improve end-user engagement. Most ecommerce applications consume a huge amount of customer data that can be used to provide […]
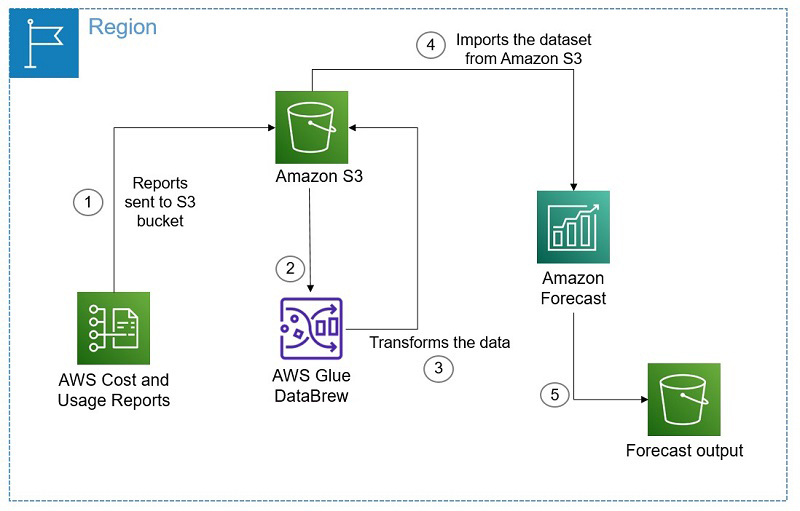
Forecasting AWS spend using the AWS Cost and Usage Reports, AWS Glue DataBrew, and Amazon Forecast
AWS Cost Explorer enables you to view and analyze your AWS Cost and Usage Reports (AWS CUR). You can also predict your overall cost associated with AWS services in the future by creating a forecast of AWS Cost Explorer, but you can’t view historical data beyond 12 months. Moreover, running custom machine learning (ML) models […]
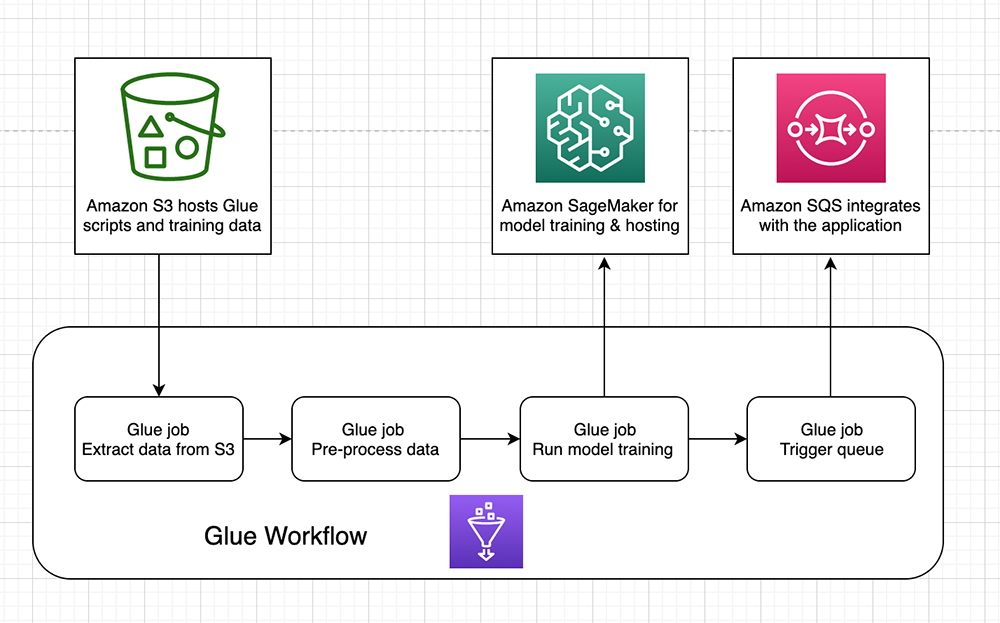
Moving from notebooks to automated ML pipelines using Amazon SageMaker and AWS Glue
A typical machine learning (ML) workflow involves processes such as data extraction, data preprocessing, feature engineering, model training and evaluation, and model deployment. As data changes over time, when you deploy models to production, you want your model to learn continually from the stream of data. This means supporting the model’s ability to autonomously learn […]

Data visualization and anomaly detection using Amazon Athena and Pandas from Amazon SageMaker
Many organizations use Amazon SageMaker for their machine learning (ML) requirements and source data from a data lake stored on Amazon Simple Storage Service (Amazon S3). The petabyte scale source data on Amazon S3 may not always be clean because data lakes ingest data from several source systems, such as like flat files, external feeds, […]

Access Amazon S3 data managed by AWS Glue Data Catalog from Amazon SageMaker notebooks
In this blog post, I’ll show you how to perform exploratory analysis on massive corporate data sets in Amazon SageMaker. From your Jupyter notebook running on Amazon SageMaker, you’ll identify and explore several corporate datasets in the corporate data lake that seem interesting to you. You’ll discover that each contains a subset of the information you need. You’ll join them to extract the interesting information, then continue analyzing and visualizing your data in your Amazon SageMaker notebook, in a seamless experience.

Serverless Unsupervised Machine Learning with AWS Glue and Amazon Athena
Have you ever had the need to segment a data set based on some of its attributes? K-means is one of the most common machine learning algorithms used to segment data. The algorithm works by separating data into different groups, called clusters. Each sample is assigned a cluster so that the samples assigned to the […]