Artificial Intelligence
Category: Advanced (300)
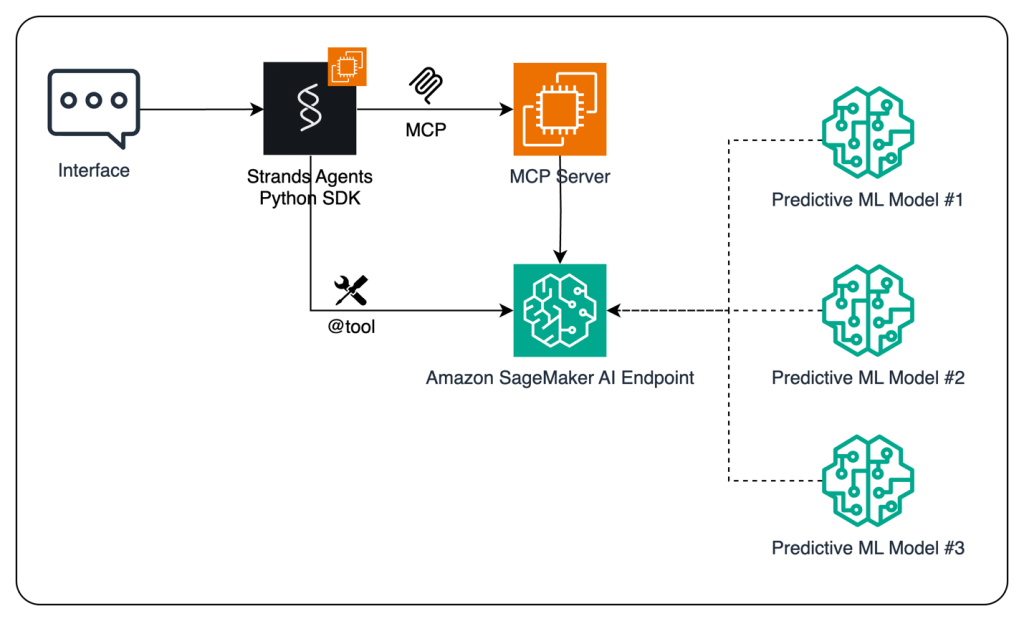
Enhance AI agents using predictive ML models with Amazon SageMaker AI and Model Context Protocol (MCP)
In this post, we demonstrate how to enhance AI agents’ capabilities by integrating predictive ML models using Amazon SageMaker AI and the MCP. By using the open source Strands Agents SDK and the flexible deployment options of SageMaker AI, developers can create sophisticated AI applications that combine conversational AI with powerful predictive analytics capabilities.
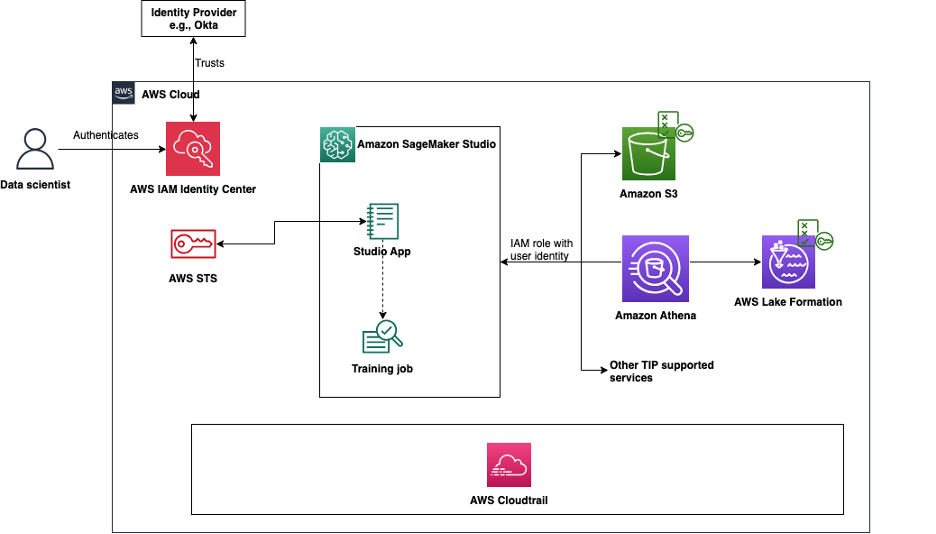
Simplify access control and auditing for Amazon SageMaker Studio using trusted identity propagation
In this post, we explore how to enable and use trusted identity propagation in Amazon SageMaker Studio, which allows organizations to simplify access management by granting permissions to existing AWS IAM Identity Center identities. The solution demonstrates how to implement fine-grained access controls based on a physical user’s identity, maintain detailed audit logs across supported AWS services, and support long-running user background sessions for training jobs.
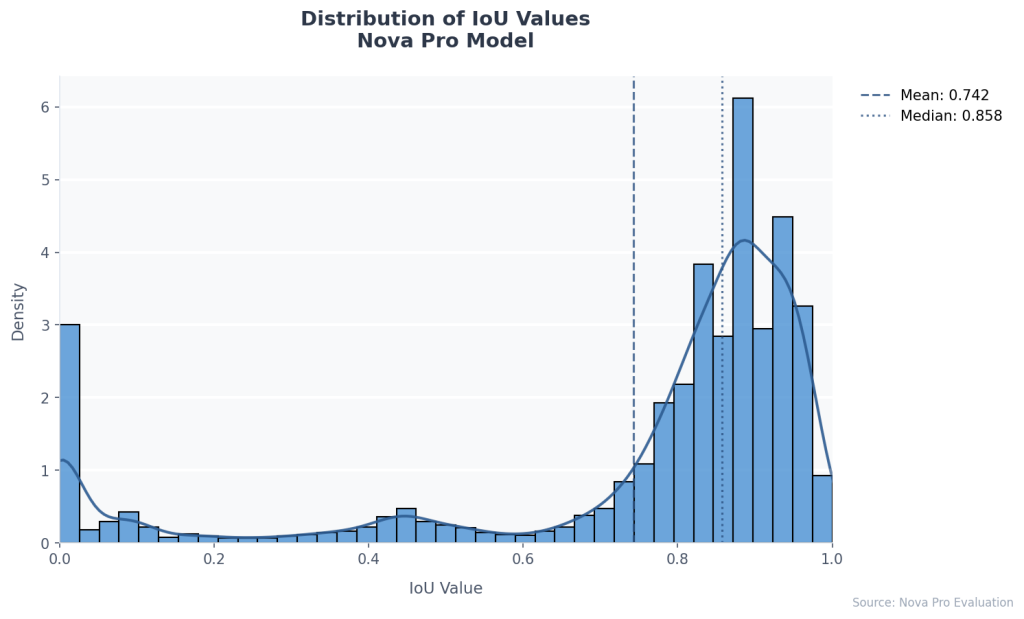
Benchmarking document information localization with Amazon Nova
This post demonstrates how to use foundation models (FMs) in Amazon Bedrock, specifically Amazon Nova Pro, to achieve high-accuracy document field localization while dramatically simplifying implementation. We show how these models can precisely locate and interpret document fields with minimal frontend effort, reducing processing errors and manual intervention.
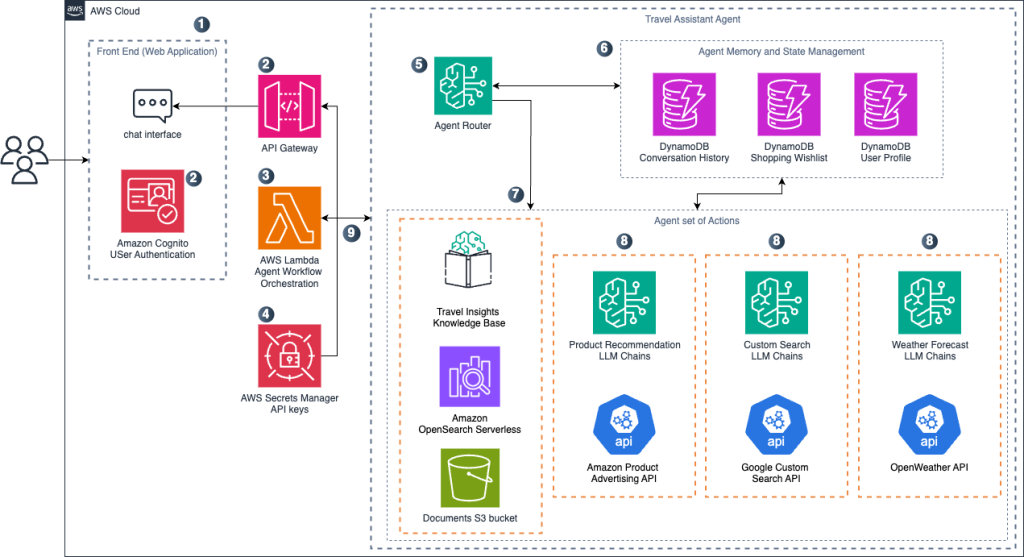
Create a travel planning agentic workflow with Amazon Nova
In this post, we explore how to build a travel planning solution using AI agents. The agent uses Amazon Nova, which offers an optimal balance of performance and cost compared to other commercial LLMs. By combining accurate but cost-efficient Amazon Nova models with LangGraph orchestration capabilities, we create a practical travel assistant that can handle complex planning tasks while keeping operational costs manageable for production deployments.
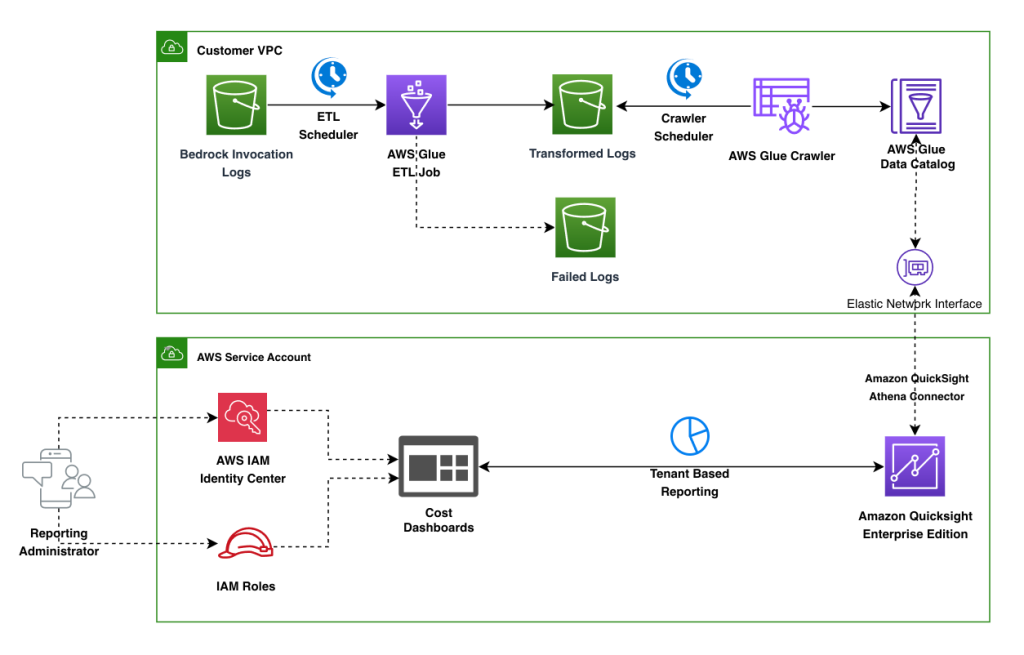
Cost tracking multi-tenant model inference on Amazon Bedrock
In this post, we demonstrate how to track and analyze multi-tenant model inference costs on Amazon Bedrock using the Converse API’s requestMetadata parameter. The solution includes an ETL pipeline using AWS Glue and Amazon QuickSight dashboards to visualize usage patterns, token consumption, and cost allocation across different tenants and departments.

Building an AI-driven course content generation system using Amazon Bedrock
In this post, we explore each component in detail, along with the technical implementation of the two core modules: course outline generation and course content generation.

Building AIOps with Amazon Q Developer CLI and MCP Server
In this post, we discuss how to implement a low-code no-code AIOps solution that helps organizations monitor, identify, and troubleshoot operational events while maintaining their security posture. We show how these technologies work together to automate repetitive tasks, streamline incident response, and enhance operational efficiency across your organization.
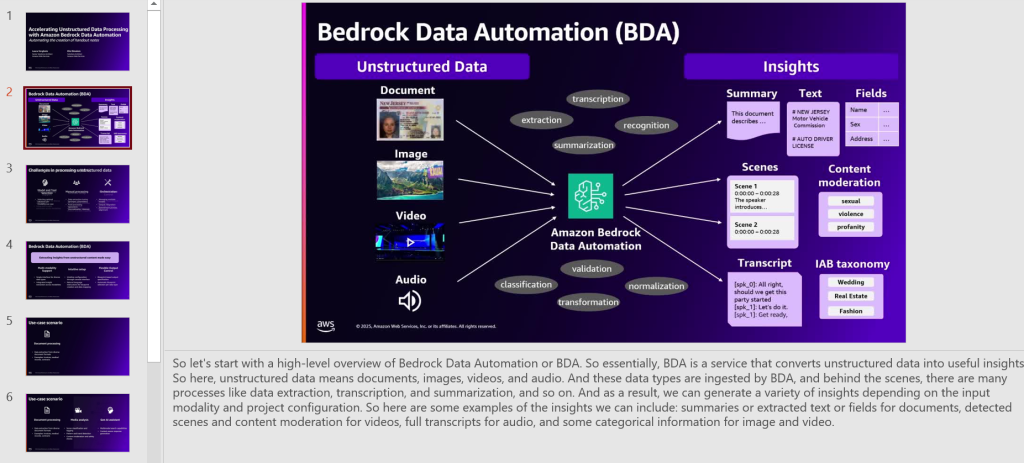
Automate the creation of handout notes using Amazon Bedrock Data Automation
In this post, we show how you can build an automated, serverless solution to transform webinar recordings into comprehensive handouts using Amazon Bedrock Data Automation for video analysis. We walk you through the implementation of Amazon Bedrock Data Automation to transcribe and detect slide changes, as well as the use of Amazon Bedrock foundation models (FMs) for transcription refinement, combined with custom AWS Lambda functions orchestrated by AWS Step Functions.
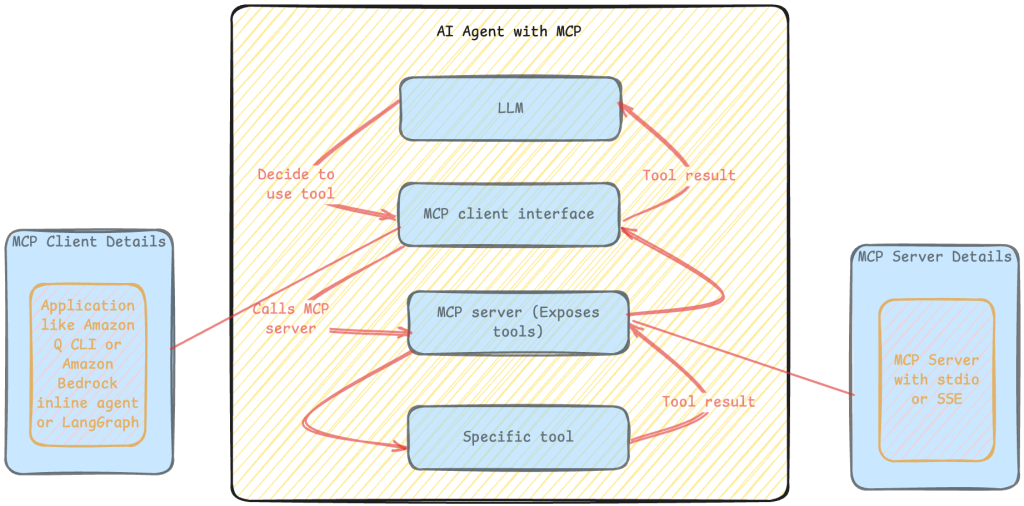
Streamline GitHub workflows with generative AI using Amazon Bedrock and MCP
This blog post explores how to create powerful agentic applications using the Amazon Bedrock FMs, LangGraph, and the Model Context Protocol (MCP), with a practical scenario of handling a GitHub workflow of issue analysis, code fixes, and pull request generation.
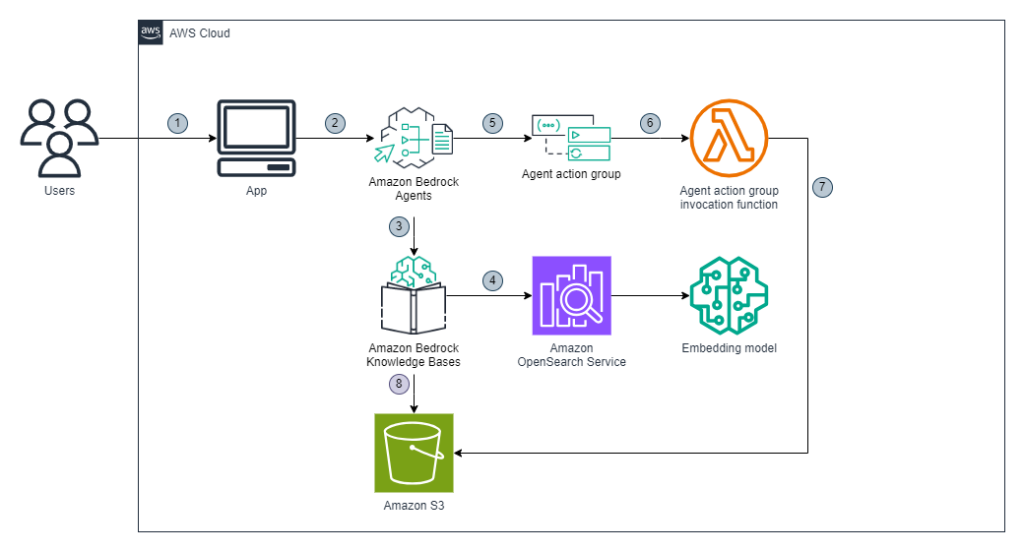
Generate suspicious transaction report drafts for financial compliance using generative AI
A suspicious transaction report (STR) or suspicious activity report (SAR) is a type of report that a financial organization must submit to a financial regulator if they have reasonable grounds to suspect any financial transaction that has occurred or was attempted during their activities. In this post, we explore a solution that uses FMs available in Amazon Bedrock to create a draft STR.