Artificial Intelligence
Category: Responsible AI

Build an AI-Powered Equipment Repair Assistant Using Amazon Bedrock AgentCore
In this post, you build an AI-powered equipment repair assistant using Amazon Bedrock AgentCore that helps farmers and field technicians diagnose equipment problems, identify required parts, and access manufacturer-approved repair procedures through natural language. The solution uses AgentCore Runtime with the Strands Agents SDK, Amazon Nova 2 Lite as the foundation model, Amazon Bedrock Knowledge Base for retrieval-augmented generation (RAG), and AgentCore Memory for conversation persistence.

Navigating EU AI Act requirements for LLM fine-tuning on Amazon SageMaker AI
In this post, we show you how to set up FLOPs tracking during LLM fine-tuning using the open source Fine-Tuning FLOPs Meter toolkit on Amazon SageMaker AI. You learn how to determine your compliance status with a single configuration flag and generate audit-ready documentation.

How Automated Reasoning checks in Amazon Bedrock transform generative AI compliance
In this post, you’ll learn why probabilistic AI validation falls short in regulated industries and how Automated Reasoning checks use formal verification to deliver mathematically proven results. You’ll also see how customers across six industries use this technology to produce formally verified, auditable AI outputs, and how to get started.

Build safe generative AI applications like a Pro: Best Practices with Amazon Bedrock Guardrails
In this post, we will show you how to configure Amazon Bedrock Guardrails for efficient performance, implement best practices to protect your applications, and monitor your deployment effectively to maintain the right balance between safety and user experience.

Governance by design: The essential guide for successful AI scaling
Picture this: Your enterprise has just deployed its first generative AI application. The initial results are promising, but as you plan to scale across departments, critical questions emerge. How will you enforce consistent security, prevent model bias, and maintain control as AI applications multiply?
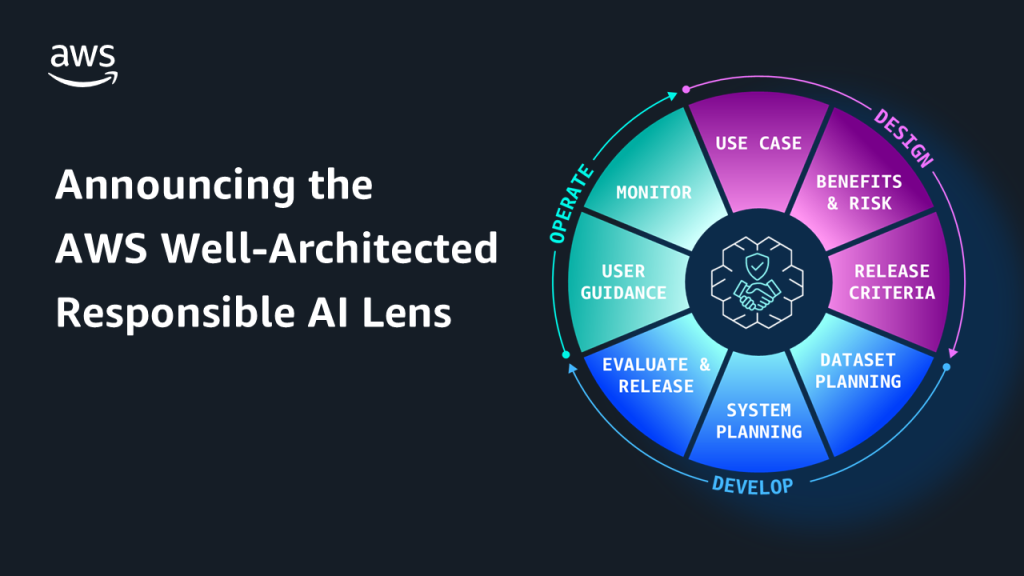
Announcing the AWS Well-Architected Responsible AI Lens
Today, we’re announcing the AWS Well-Architected Responsible AI Lens—a set of thoughtful questions and corresponding best practices that help builders address responsible AI concerns throughout development and operation.
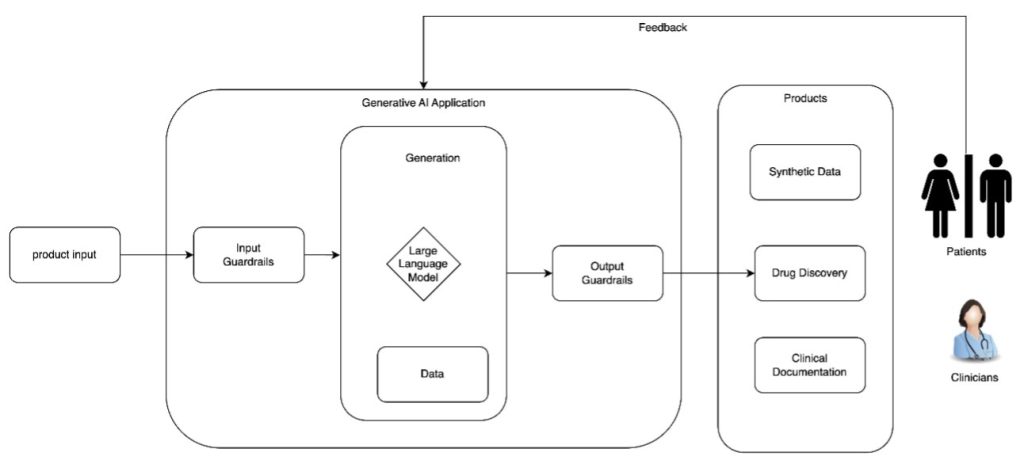
Responsible AI design in healthcare and life sciences
In this post, we explore the critical design considerations for building responsible AI systems in healthcare and life sciences, focusing on establishing governance mechanisms, transparency artifacts, and security measures that ensure safe and effective generative AI applications. The discussion covers essential policies for mitigating risks like confabulation and bias while promoting trust, accountability, and patient safety throughout the AI development lifecycle.

Incorporating responsible AI into generative AI project prioritization
In this post, we explore how companies can systematically incorporate responsible AI practices into their generative AI project prioritization methodology to better evaluate business value against costs while addressing novel risks like hallucination and regulatory compliance. The post demonstrates through a practical example how conducting upfront responsible AI risk assessments can significantly change project rankings by revealing substantial mitigation work that affects overall project complexity and timeline.

Responsible AI for the payments industry – Part 1
This post explores the unique challenges facing the payments industry in scaling AI adoption, the regulatory considerations that shape implementation decisions, and practical approaches to applying responsible AI principles. In Part 2, we provide practical implementation strategies to operationalize responsible AI within your payment systems.

Responsible AI for the payments industry – Part 2
In Part 1 of our series, we explored the foundational concepts of responsible AI in the payments industry. In this post, we discuss the practical implementation of responsible AI frameworks.